Operand stack
Miden VM is a stack machine. The stack is a push-down stack of practically unlimited depth (in practical terms, the depth will never exceed ), but only the top items are directly accessible to the VM. Items on the stack are elements in a prime field with modulus .
To keep the constraint system for the stack manageable, we impose the following rules:
- All operations executed on the VM can shift the stack by at most one item. That is, the end result of an operation must be that the stack shrinks by one item, grows by one item, or the number of items on the stack stays the same.
- Stack depth must always be greater than or equal to . At the start of program execution, the stack is initialized with exactly input values, all of which could be 's.
- By the end of program execution, exactly items must remain on the stack (again, all of them could be 's). These items comprise the output of the program.
To ensure that managing stack depth does not impose significant burden, we adopt the following rule:
- When the stack depth is , removing additional items from the stack does not change its depth. To keep the depth at , 's are inserted into the deep end of the stack for each removed item.
Stack representation
The VM allocates trace columns for the stack. The layout of the columns is illustrated below.

The meaning of the above columns is as follows:
- are the columns representing the top slots of the stack.
- Column contains the number of items on the stack (i.e., the stack depth). In the above picture, there are 16 items on the stacks, so .
- Column contains an address of a row in the "overflow table" in which we'll store the data that doesn't fit into the top slots. When , it means that all stack data fits into the top slots of the stack.
- Helper column is used to ensure that stack depth does not drop below . Values in this column are set by the prover non-deterministically to when , and to any other value otherwise.
Overflow table
To keep track of the data which doesn't fit into the top stack slots, we'll use an overflow table. This will be a virtual table. To represent this table, we'll use a single auxiliary column .
The table itself can be thought of as having 3 columns as illustrated below.
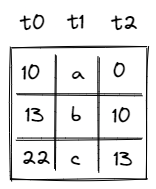
The meaning of the columns is as follows:
- Column contains row address. Every address in the table must be unique.
- Column contains the value that overflowed the stack.
- Column contains the address of the row containing the value that overflowed the stack right before the value in the current row. For example, in the picture above, first value overflowed the stack, then overflowed the stack, and then value overflowed the stack. Thus, row with value points back to the row with value , and row with value points back to the row with value .
To reduce a table row to a single value, we'll compute a randomized product of column values as follows:
Then, when row is added to the table, we'll update the value in the column like so:
Analogously, when row is removed from the table, we'll update the value in column like so:
The initial value of is set to . Thus, if by the time Miden VM finishes executing a program the table is empty (we added and then removed exactly the same set of rows), will also be equal to .
There are a couple of other rules we'll need to enforce:
- We can delete a row only after the row has been inserted into the table.
- We can't insert a row with the same address twice into the table (even if the row was inserted and then deleted).
How these are enforced will be described a bit later.
Right shift
If an operation adds data to the stack, we say that the operation caused a right shift. For example, PUSH and DUP operations cause a right shift. Graphically, this looks like so:
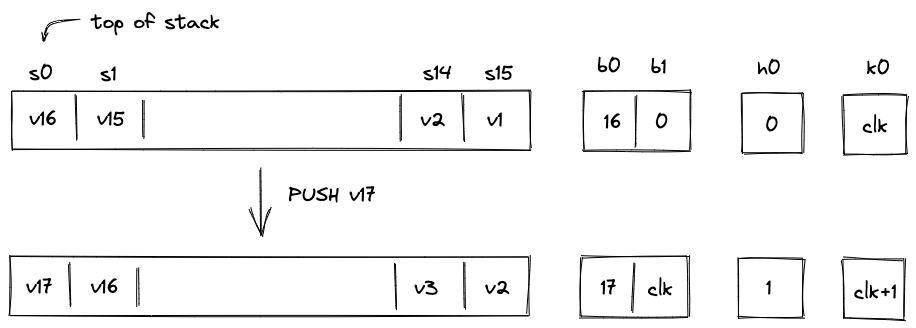
Here, we pushed value onto the stack. All other values on the stack are shifted by one slot to the right and the stack depth increases by . There is not enough space at the top of the stack for all values, thus, needs to be moved to the overflow table.
To do this, we need to rely on another column: . This is a system column which keeps track of the current VM cycle. The value in this column is simply incremented by with every step.
The row we want to add to the overflow table is defined by tuple , and after it is added, the table would look like so:

The reason we use VM clock cycle as row address is that the clock cycle is guaranteed to be unique, and thus, the same row can not be added to the table twice.
Let's push another item onto the stack:
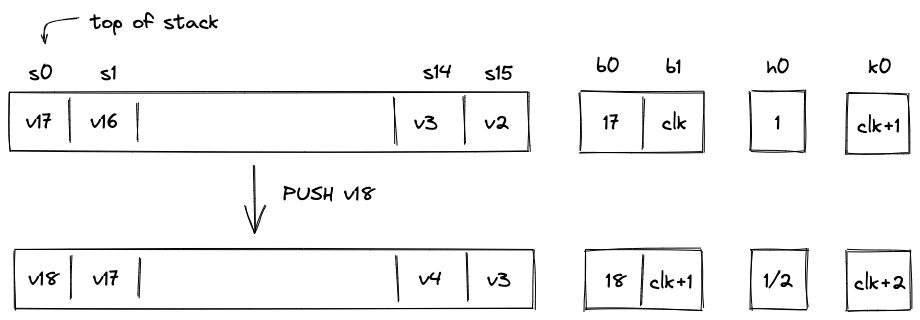
Again, as we push onto the stack, all items on the stack are shifted to the right, and now needs to be moved to the overflow table. The tuple we want to insert into the table now is . After the operation, the overflow table will look like so:
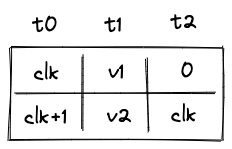
Notice that for row which contains value points back to the row with address .
Overall, during a right shift we do the following:
- Increment stack depth by .
- Shift stack columns right by slot.
- Add a row to the overflow table described by tuple .
- Set the next value of to the current value of .
Also, as mentioned previously, the prover sets values in non-deterministically to .
Left shift
If an operation removes an item from the stack, we say that the operation caused a left shift. For example, a DROP operation causes a left shift. Assuming the stack is in the state we left it at the end of the previous section, graphically, this looks like so:
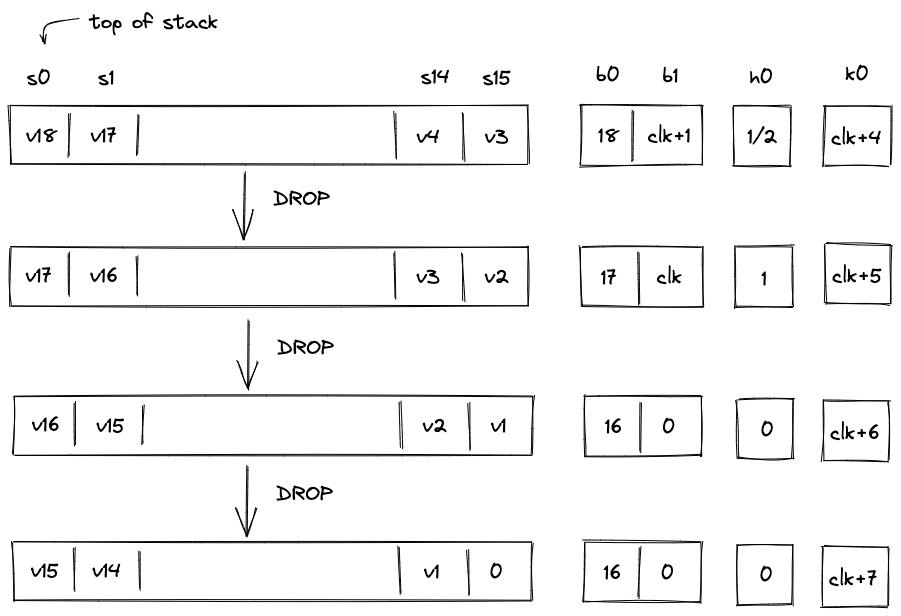
Overall, during the left shift we do the following:
- When stack depth is greater than :
- Decrement stack depth by .
- Shift stack columns left by slot.
- Remove a row from the overflow table with equal to the current value of .
- Set the next value of to the value in of the removed overflow table row.
- Set the next value of to the value in of the removed overflow table row.
- When the stack depth is equal to :
- Keep the stack depth the same.
- Shift stack columns left by slot.
- Set the value of to .
- Set the value to to (or any other value).
If the stack depth becomes (or remains) , the prover can set to any value (e.g., ). But if the depth is greater than the prover sets to .
AIR Constraints
To simplify constraint descriptions, we'll assume that the VM exposes two binary flag values described below.
| Flag | Degree | Description |
|---|---|---|
| 6 | When this flag is set to , the instruction executing on the VM is performing a "right shift". | |
| 5 | When this flag is set to , the instruction executing on the VM is performing a "left shift". |
These flags are mutually exclusive. That is, if , then and vice versa. However, both flags can be set to simultaneously. This happens when the executed instruction does not shift the stack. How these flags are computed is described here.
Stack overflow flag
Additionally, we'll define a flag to indicate whether the overflow table contains values. This flag will be set to when the overflow table is empty, and to otherwise (i.e., when stack depth ). This flag can be computed as follows:
To ensure that this flag is set correctly, we need to impose the following constraint:
The above constraint can be satisfied only when either of the following holds:
- , in which case evaluates to , regardless of the value of .
- , in which case cannot be equal to (and must be set to ).
Stack depth constraints
To make sure stack depth column is updated correctly, we need to impose the following constraints:
| Condition | Constraint__ | Description |
|---|---|---|
| When the stack is shifted to the right, stack depth should be incremented by . | ||
| | When the stack is shifted to the left and the overflow table is not empty, stack depth should be decremented by . | |
| otherwise | In all other cases, stack depth should not change. |
We can combine the above constraints into a single expression as follows:
Overflow table constraints
When the stack is shifted to the right, a tuple should be added to the overflow table. We will denote value of the row to be added to the table as follows:
When the stack is shifted to the left, a tuple should be removed from the overflow table. We will denote value of the row to be removed from the table as follows.
Using the above variables, we can ensure that right and left shifts update the overflow table correctly by enforcing the following constraint:
The above constraint reduces to the following under various flag conditions:
| Condition | Applied constraint |
|---|---|
| , , | |
| , , | |
| , , | |
| , , |
Notice that in the case of the left shift, the constraint forces the prover to set the next values of and to values and of the row removed from the overflow table.
In case of a right shift, we also need to make sure that the next value of is set to the current value of . This can be done with the following constraint:
In case of a left shift, when the overflow table is empty, we need to make sure that a is "shifted in" from the right (i.e., is set to ). This can be done with the following constraint:
Boundary constraints
In addition to the constraints described above, we also need to enforce the following boundary constraints:
- at the first and at the last row of execution trace.
- at the first and at the last row of execution trace.
- at the first and at the last row of execution trace.