Hash chiplet
Miden VM "offloads" all hash-related computations to a separate hash processor. This chiplet supports executing the Rescue Prime Optimized hash function (or rather a specific instantiation of it) in the following settings:
- A single permutation of Rescue Prime Optimized.
- A simple 2-to-1 hash.
- A linear hash of field elements.
- Merkle path verification.
- Merkle root update.
The chiplet can be thought of as having a small instruction set of instructions. These instructions are listed below, and examples of how these instructions are used by the chiplet are described in the following sections.
| Instruction | Description |
|---|---|
HR | Executes a single round of the VM's native hash function. All cycles which are not one less than a multiple of execute this instruction. That is, the chiplet executes this instruction on cycles , but not , and then again, , but not etc. |
BP | Initiates computation of a single permutation, a 2-to-1 hash, or a linear hash of many elements. This instruction can be executed only on cycles which are multiples of , and it can also be executed concurrently with an HR instruction. |
MP | Initiates Merkle path verification computation. This instruction can be executed only on cycles which are multiples of , and it can also be executed concurrently with an HR instruction. |
MV | Initiates Merkle path verification for the "old" node value during Merkle root update computation. This instruction can be executed only on cycles which are multiples of , and it can also be executed concurrently with an HR instruction. |
MU | Initiates Merkle path verification for the "new" node value during Merkle root update computation. This instruction can be executed only on cycles which are multiples of , and it can also be executed concurrently with an HR instruction. |
HOUT | Returns the result of the currently running computation. This instruction can be executed only on cycles which are one less than a multiple of (e.g. , etc.). |
SOUT | Returns the whole hasher state. This instruction can be executed only on cycles which are one less than a multiple of , and only if the computation was started using BP instruction. |
ABP | Absorbs a new set of elements into the hasher state when computing a linear hash of many elements. This instruction can be executed only on cycles which are one less than a multiple of , and only if the computation was started using BP instruction. |
MPA | Absorbs the next Merkle path node into the hasher state during Merkle path verification computation. This instruction can be executed only on cycles which are one less than a multiple of , and only if the computation was started using MP instruction. |
MVA | Absorbs the next Merkle path node into the hasher state during Merkle path verification for the "old" node value during Merkle root update computation. This instruction can be executed only on cycles which are one less than a multiple of , and only if the computation was started using MV instruction. |
MUA | Absorbs the next Merkle path node into the hasher state during Merkle path verification for the "new" node value during Merkle root update computation. This instruction can be executed only on cycles which are one less than a multiple of , and only if the computation was started using Mu instruction. |
Chiplet trace
Execution trace table of the chiplet consists of trace columns and periodic columns. The structure of the table is such that a single permutation of the hash function can be computed using table rows. The layout of the table is illustrated below.
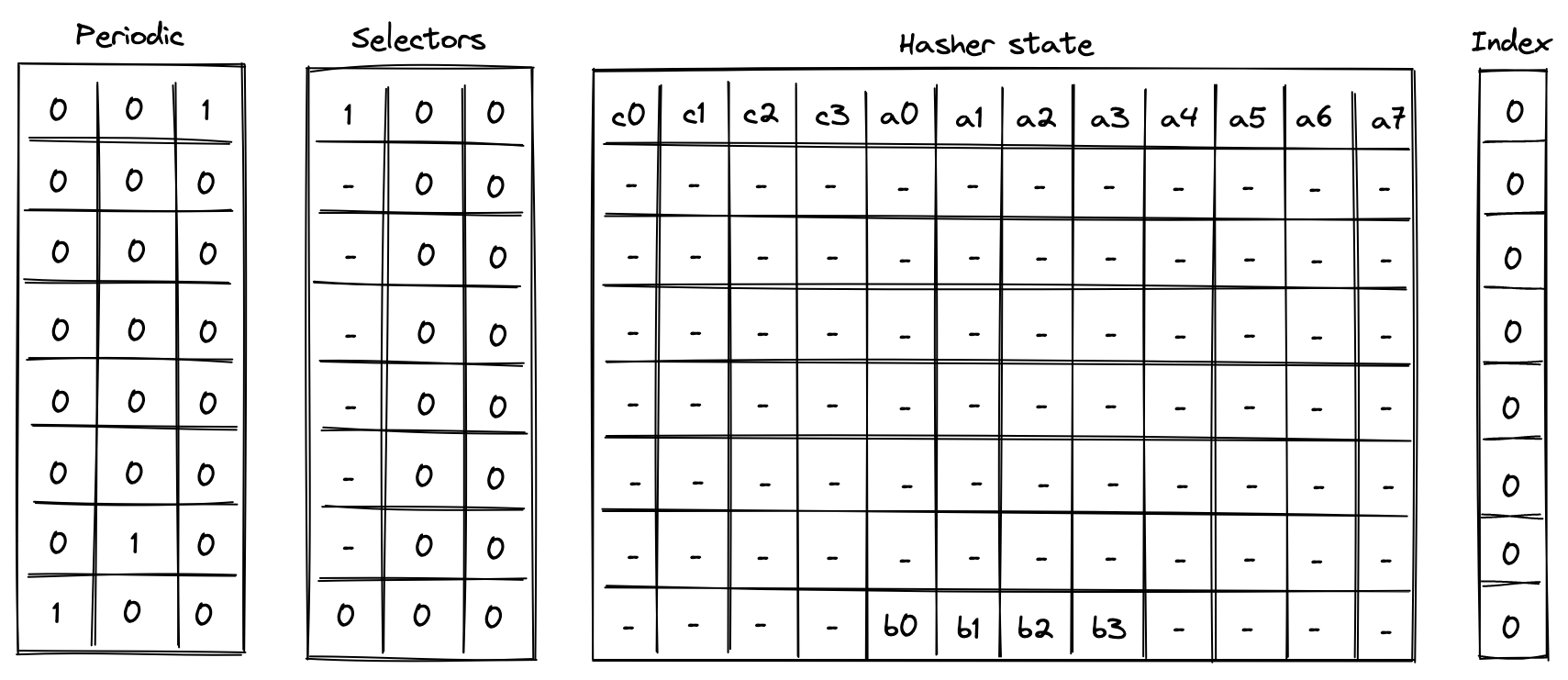
The meaning of the columns is as follows:
- Three periodic columns , , and are used to help select the instruction executed at a given row. All of these columns contain patterns which repeat every rows. For the pattern is zeros followed by one, helping us identify the last row in the cycle. For the pattern is zeros, one, and zero, which can be used to identify the second-to-last row in a cycle. For the pattern is one followed by zeros, which can identify the first row in the cycle.
- Three selector columns , , and . These columns can contain only binary values (ones or zeros), and they are also used to help select the instruction to execute at a given row.
- Twelve hasher state columns . These columns are used to hold the hasher state for each round of the hash function permutation. The state is laid out as follows:
- The first four columns () are reserved for capacity elements of the state. When the state is initialized for hash computations, should be set to if the number of elements to be hashed is a multiple of the rate width (). Otherwise, should be set to . should be set to the domain value if a domain has been provided (as in the case of control block hashing). All other capacity elements should be set to 's.
- The next eight columns () are reserved for the rate elements of the state. These are used to absorb the values to be hashed. Once the permutation is complete, hash output is located in the first four rate columns ().
- One index column . This column is used to help with Merkle path verification and Merkle root update computations.
In addition to the columns described above, the chiplet relies on two running product columns which are used to facilitate multiset checks (similar to the ones described here). These columns are:
- - which is used to tie the chiplet table with the main VM's stack and decoder. That is, values representing inputs consumed by the chiplet and outputs produced by the chiplet are multiplied into , while the main VM stack (or decoder) divides them out of . Thus, if the sets of inputs and outputs between the main VM stack and hash chiplet are the same, the value of should be equal to at the start and the end of the execution trace.
- - which is used to keep track of the sibling table used for Merkle root update computations. Specifically, when a root for the old leaf value is computed, we add an entry for all sibling nodes to the table (i.e., we multiply by the values representing these entries). When the root for the new leaf value is computed, we remove the entries for the nodes from the table (i.e., we divide by the value representing these entries). Thus, if both computations used the same set of sibling nodes (in the same order), the sibling table should be empty by the time Merkle root update procedure completes (i.e., the value of would be ).
Instruction flags
As mentioned above, chiplet instructions are encoded using a combination of periodic and selector columns. These columns can be used to compute a binary flag for each instruction. Thus, when a flag for a given instruction is set to , the chiplet executes this instruction. Formulas for computing instruction flags are listed below.
| Flag | Value | Notes |
|---|---|---|
| Set to on the first steps of every -step cycle. | ||
| Set to when selector flags are on rows which are multiples of . | ||
| Set to when selector flags are on rows which are multiples of . | ||
| Set to when selector flags are on rows which are multiples of . | ||
| Set to when selector flags are on rows which are multiples of . | ||
| Set to when selector flags are on rows which are less than a multiple of . | ||
| Set to when selector flags are on rows which are less than a multiple of . | ||
| Set to when selector flags are on rows which are less than a multiple of . | ||
| Set to when selector flags are on rows which are less than a multiple of . | ||
| Set to when selector flags are on rows which are less than a multiple of . | ||
| Set to when selector flags are on rows which are less than a multiple of . |
A few additional notes about flag values:
- With the exception of , all flags are mutually exclusive. That is, if one flag is set to , all other flats are set to .
- With the exception of , computing flag values involves multiplications, and thus the degree of these flags is .
- We can also define a flag . This flag will be set to when either or in the current row.
- We can define a flag . This flag will be set to when either or in the next row.
We also impose the following restrictions on how values in selector columns can be updated:
- Values in columns and must be copied over from one row to the next, unless or indicating the
houtorsoutflag is set for the current or the next row. - Value in must be set to if for the previous row, and to if any of the flags , , , or are set to for the previous row.
The above rules ensure that we must finish one computation before starting another, and we can't change the type of the computation before the computation is finished.
Computation examples
Single permutation
Computing a single permutation of Rescue Prime Optimized hash function involves the following steps:
- Initialize hasher state with field elements.
- Apply Rescue Prime Optimized permutation.
- Return the entire hasher state as output.
The chiplet accomplishes the above by executing the following instructions:
[BP, HR] // init state and execute a hash round (concurrently)
HR HR HR HR HR HR // execute 6 more hash rounds
SOUT // return the entire state as output
Execution trace for this computation would look as illustrated below.
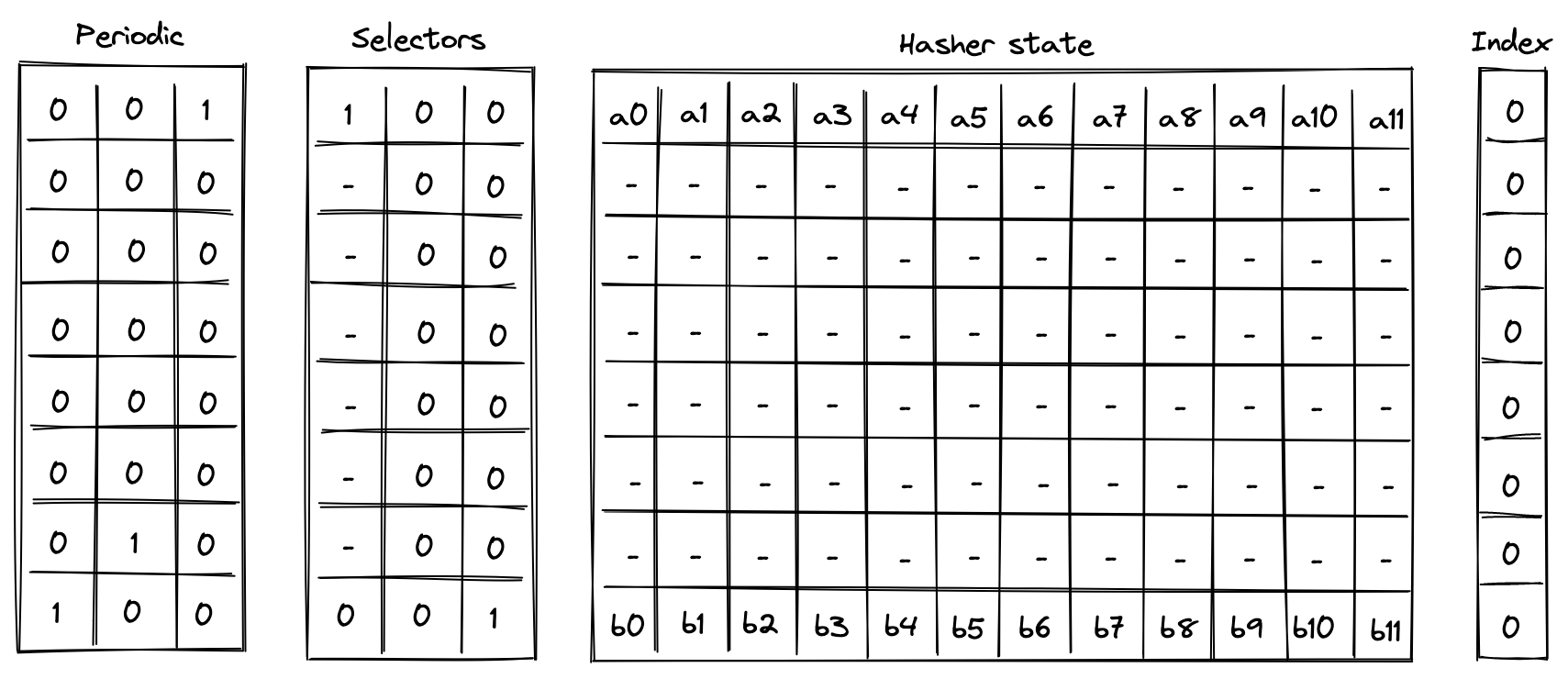
In the above is the input state of the hasher, and is the output state of the hasher.
Simple 2-to-1 hash
Computing a 2-to-1 hash involves the following steps:
- Initialize hasher state with field elements, setting the second capacity element to if the domain is provided (as in the case of control block hashing) or else , and the remaining capacity elements to .
- Apply Rescue Prime Optimized permutation.
- Return elements of the hasher state as output.
The chiplet accomplishes the above by executing the following instructions:
[BP, HR] // init state and execute a hash round (concurrently)
HR HR HR HR HR HR // execute 6 more hash rounds
HOUT // return elements 4, 5, 6, 7 of the state as output
Execution trace for this computation would look as illustrated below.
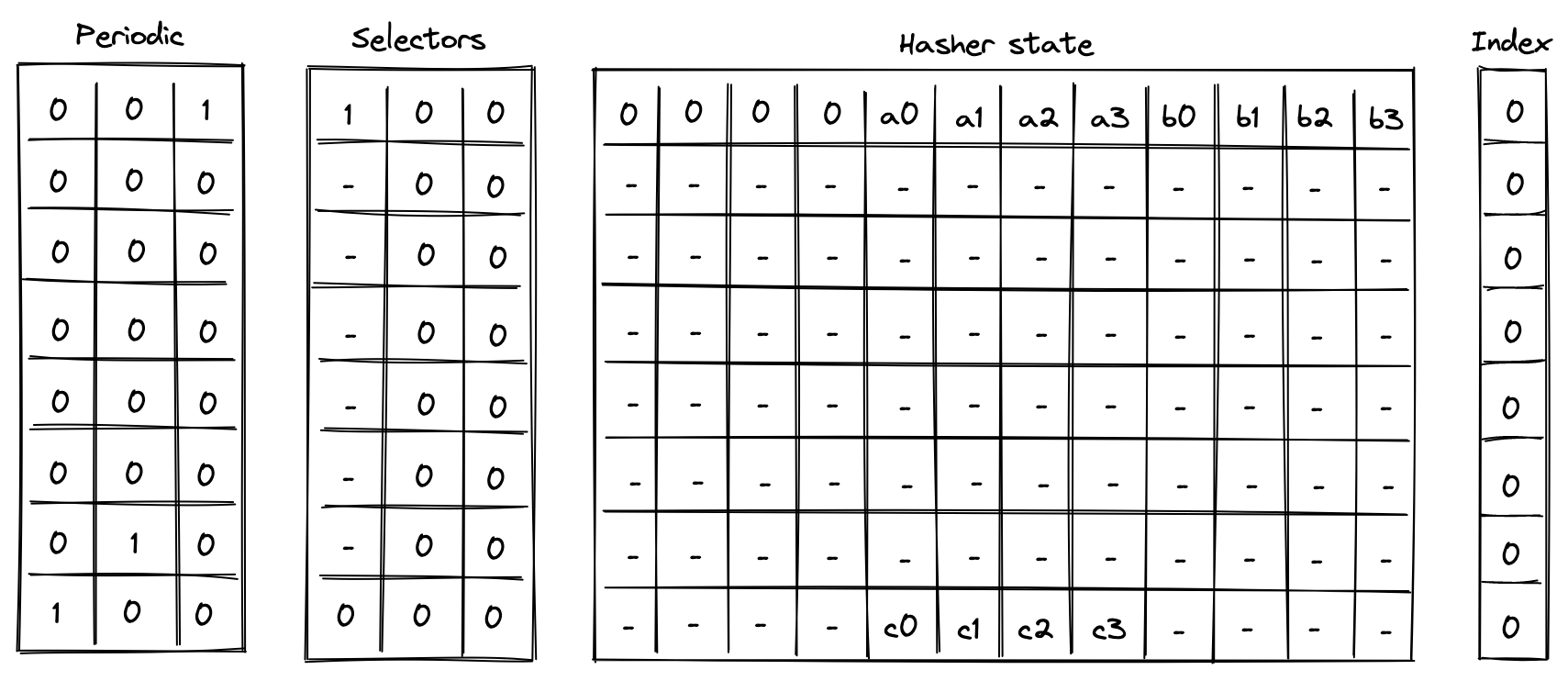
In the above, we compute the following:
Linear hash of n elements
Computing a linear hash of elements consists of the following steps:
- Initialize hasher state with the first elements, setting the first capacity register to if is a multiple of the rate width () or else , and the remaining capacity elements to .
- Apply Rescue Prime Optimized permutation.
- Absorb the next set of elements into the state (up to elements), while keeping capacity elements unchanged.
- Repeat steps 2 and 3 until all elements have been absorbed.
- Return elements of the hasher state as output.
The chiplet accomplishes the above by executing the following instructions (for hashing elements):
[BP, HR] // init state and execute a hash round (concurrently)
HR HR HR HR HR HR // execute 6 more hash rounds
ABP // absorb the next set of elements into the state
HR HR HR HR HR HR HR // execute 7 hash rounds
HOUT // return elements 4, 5, 6, 7 of the state as output
Execution trace for this computation would look as illustrated below.
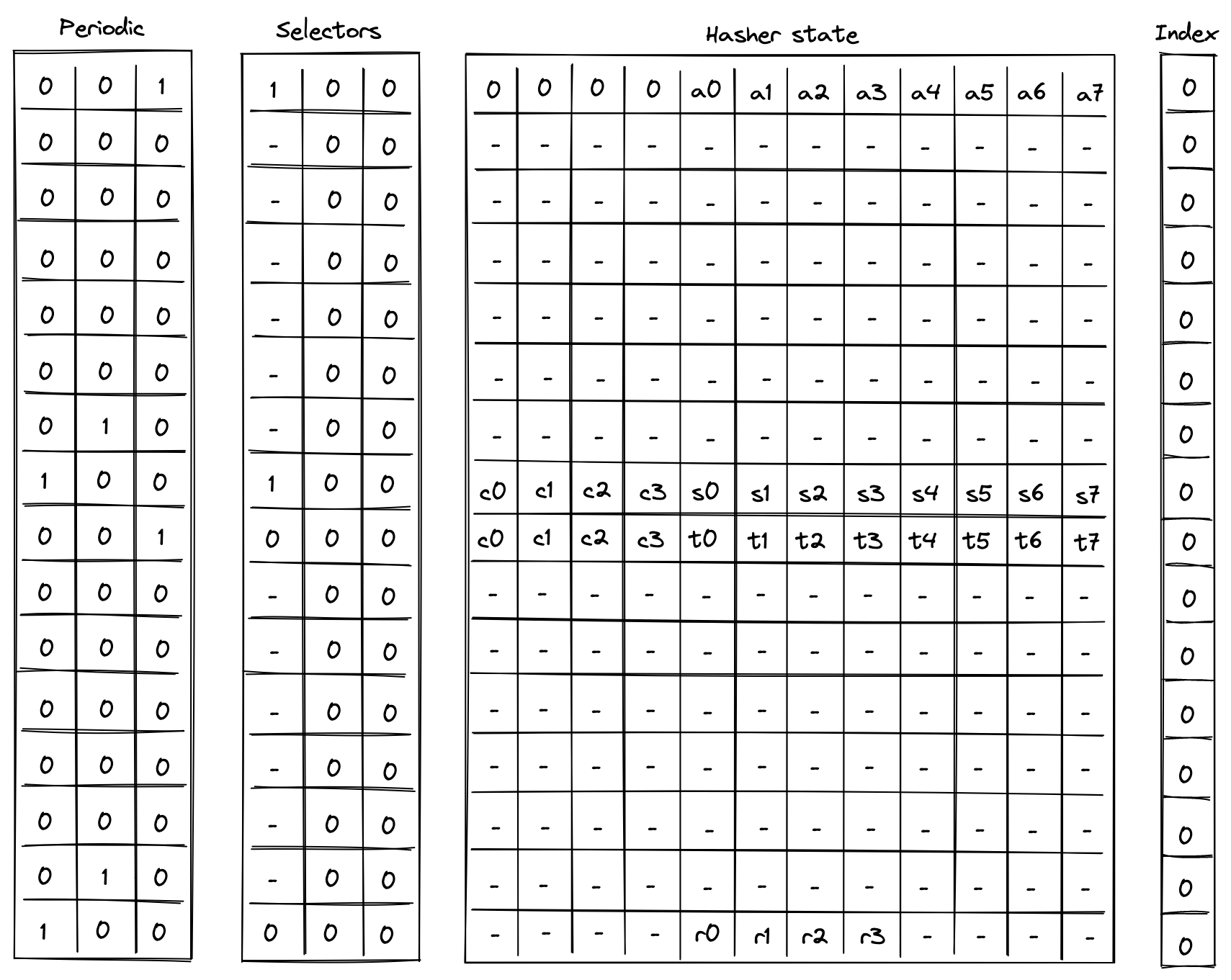
In the above, the value absorbed into hasher state between rows and is the delta between values and . Thus, if we define for , the above computes the following:
Verify Merkle path
Verifying a Merkle path involves the following steps:
- Initialize hasher state with the leaf and the first node of the path, setting all capacity elements to s. a. Also, initialize the index register to the leaf's index value.
- Apply Rescue Prime Optimized permutation. a. Make sure the index value doesn't change during this step.
- Copy the result of the hash to the next row, and absorb the next node of the Merkle path into the hasher state. a. Remove a single bit from the index, and use it to determine how to place the copied result and absorbed node in the state.
- Repeat steps 2 and 3 until all nodes of the Merkle path have been absorbed.
- Return elements of the hasher state as output. a. Also, make sure the index value has been reduced to .
The chiplet accomplishes the above by executing the following instructions (for Merkle tree of depth ):
[MP, HR] // init state and execute a hash round (concurrently)
HR HR HR HR HR HR // execute 6 more hash rounds
MPA // copy result & absorb the next node into the state
HR HR HR HR HR HR HR // execute 7 hash rounds
HOUT // return elements 4, 5, 6, 7 of the state as output
Suppose we have a Merkle tree as illustrated below. This Merkle tree has leaves, each of which consists of field elements. For example, leaf consists of elements , leaf be consists of elements etc.
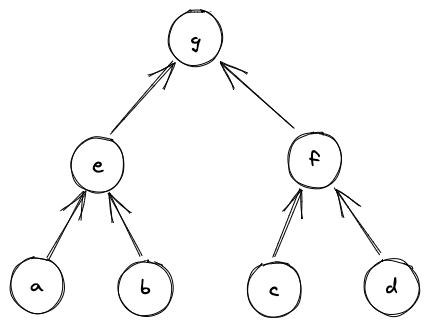
If we wanted to verify that leaf is in fact in the tree, we'd need to compute the following hashes:
And if , we can be convinced that is in fact in the tree at position . Execution trace for this computation would look as illustrated below.
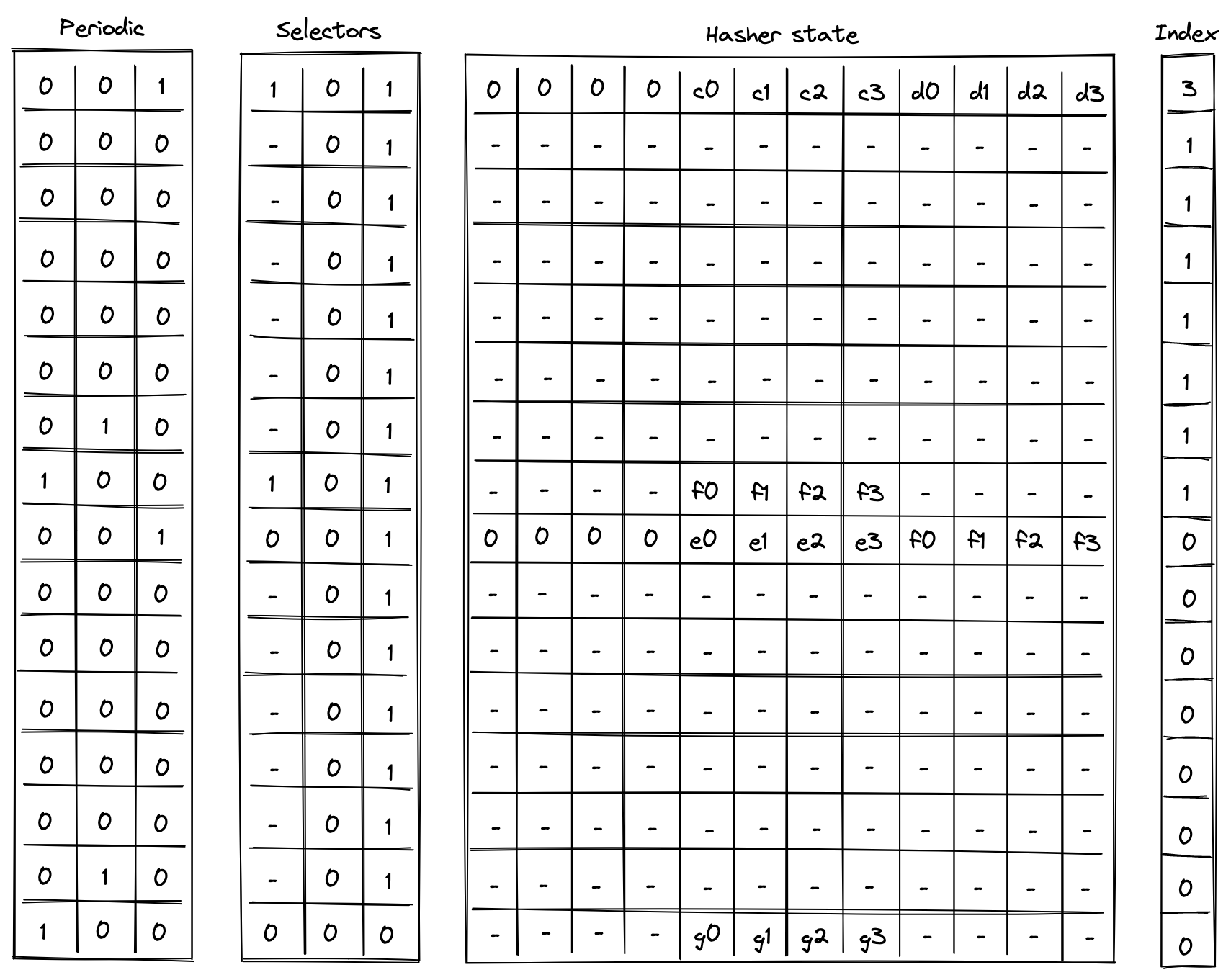
In the above, the prover provides values for nodes and non-deterministically.
Update Merkle root
Updating a node in a Merkle tree (which also updates the root of the tree) can be simulated by verifying two Merkle paths: the path that starts with the old leaf and the path that starts with the new leaf.
Suppose we have the same Merkle tree as in the previous example, and we want to replace node with node . The computations we'd need to perform are:
Then, as long as , and the same values were used for and in both computations, we can be convinced that the new root of the tree is .
The chiplet accomplishes the above by executing the following instructions:
// verify the old merkle path
[MV, HR] // init state and execute a hash round (concurrently)
HR HR HR HR HR HR // execute 6 more hash rounds
MPV // copy result & absorb the next node into the state
HR HR HR HR HR HR HR // execute 7 hash rounds
HOUT // return elements 4, 5, 6, 7 of the state as output
// verify the new merkle path
[MU, HR] // init state and execute a hash round (concurrently)
HR HR HR HR HR HR // execute 6 more hash rounds
MPU // copy result & absorb the next node into the state
HR HR HR HR HR HR HR // execute 7 hash rounds
HOUT // return elements 4, 5, 6, 7 of the state as output
The semantics of MV and MU instructions are similar to the semantics of MP instruction from the previous example (and MVA and MUA are similar to MPA) with one important difference: MV* instructions add the absorbed node (together with its index in the tree) to permutation column , while MU* instructions remove the absorbed node (together with its index in the tree) from . Thus, if the same nodes were used during both Merkle path verification, the state of should not change. This mechanism is used to ensure that the same internal nodes were used in both computations.
AIR constraints
When describing AIR constraints, we adopt the following notation: for column , we denote the value in the current row simply as , and the value in the next row of the column as . Thus, all transition constraints described in this note work with two consecutive rows of the execution trace.
Selector columns constraints
For selector columns, first we must ensure that only binary values are allowed in these columns. This can be done with the following constraints:
Next, we need to make sure that unless or , the values in columns and are copied over to the next row. This can be done with the following constraints:
Next, we need to enforce that if any of flags is set to , the next value of is . In all other cases, should be unconstrained. These flags will only be set for rows that are 1 less than a multiple of 8 (the last row of each cycle). This can be done with the following constraint:
Lastly, we need to make sure that no invalid combinations of flags are allowed. This can be done with the following constraints:
The above constraints enforce that on every step which is one less than a multiple of , if , then must also be set to . Basically, if we set , then we must make sure that either or .
Node index constraints
Node index column is relevant only for Merkle path verification and Merkle root update computations, but to simplify the overall constraint system, the same constraints will be imposed on this column for all computations.
Overall, we want values in the index column to behave as follows:
- When we start a new computation, we should be able to set to an arbitrary value.
- When a computation is finished, value in must be .
- When we absorb a new node into the hasher state we must shift the value in by one bit to the right.
- In all other cases value in should not change.
A shift by one bit to the right can be described with the following equation: , where is the value of the bit which is discarded. Thus, as long as is a binary value, the shift to the right is performed correctly, and this can be enforced with the following constraint:
Since we want to enforce this constraint only when a new node is absorbed into the hasher state, we'll define a flag for when this should happen as follows:
And then the full constraint would looks as follows:
Next, to make sure when a computation is finished , we can use the following constraint:
Finally, to make sure that the value in is copied over to the next row unless we are absorbing a new row or the computation is finished, we impose the following constraint:
To satisfy these constraints for computations not related to Merkle paths (i.e., 2-to-1 hash and liner hash of elements), we can set at the start of the computation. This guarantees that will remain until the end of the computation.
Hasher state constraints
Hasher state columns should behave as follows:
- For the first row of every -row cycle (i.e., when ), we need to apply Rescue Prime Optimized round constraints to the hasher state. For brevity, we omit these constraints from this note.
- On the th row of every -row cycle, we apply the constraints based on which transition flag is set as described in the table below.
Specifically, when absorbing the next set of elements into the state during linear hash computation (i.e., ), the first elements (the capacity portion) are carried over to the next row. For this can be described as follows:
When absorbing the next node during Merkle path computation (i.e., ), the result of the previous hash () are copied over either to or to depending on the value of , which is defined in the same way as in the previous section. For this can be described as follows:
Note, that when a computation is completed (i.e., ), the next hasher state is unconstrained.
Multiset check constraints
In this sections we describe constraints which enforce updates for multiset check columns and . These columns can be updated only on rows which are multiples of or less than a multiple of . On all other rows the values in the columns remain the same.
To simplify description of the constraints, we define the following variables. Below, we denote random values sent by the verifier after the prover commits to the main execution trace as , , etc.
In the above:
- is a transition label, composed of the operation label and the periodic columns that uniquely identify each transition function. The values in the and periodic columns are included to identify the row in the hash cycle where the operation occurs. They serve to differentiate between operations that share selectors but occur at different rows in the cycle, such as
BP, which uses at the first row in the cycle to initiate a linear hash, andABP, which uses at the last row in the cycle to absorb new elements. - is a common header which is a combination of the transition label, a unique row address, and the node index. For the unique row address, the
clkcolumn from the system component is used, but we add , because the system'sclkcolumn starts at . - , , are the first, second, and third words (4 elements) of the hasher state.
- is the third word of the hasher state but computed using the same values as used for the second word. This is needed for computing the value of below to ensure that the same values are used for the leaf node regardless of which part of the state the node comes from.
Chiplets bus constraints
As described previously, the chiplets bus , implemented as a running product column, is used to tie the hash chiplet with the main VM's stack and decoder. When receiving inputs from or returning results to the stack (or decoder), the hash chiplet multiplies by their respective values. On the other side, when sending inputs to the hash chiplet or receiving results from the chiplet, the stack (or decoder) divides by their values.
In the section below we describe only the hash chiplet side of the constraints (i.e., multiplying by relevant values). We define the values which are to be multiplied into for each operation as follows:
When starting a new simple or linear hash computation (i.e., ) or when returning the entire state of the hasher (), the entire hasher state is included into :
When starting a Merkle path computation (i.e., ), we include the leaf of the path into . The leaf is selected from the state based on value of (defined as in the previous section):
When absorbing a new set of elements into the state while computing a linear hash (i.e., ), we include deltas between the last elements of the hasher state (the rate) into :
When a computation is complete (i.e., ), we include the second word of the hasher state (the result) into :
Using the above values, we can describe the constraints for updating column as follows.
The above constraint reduces to the following under various flag conditions:
| Condition | Applied constraint |
|---|---|
| Otherwise |
Note that the degree of the above constraint is .
Sibling table constraints
Note: Although this table is described independently, it is implemented as part of the chiplets virtual table, which combines all virtual tables required by any of the chiplets into a single master table.
As mentioned previously, the sibling table (represented by running column ) is used to keep track of sibling nodes used during Merkle root update computations. For this computation, we need to enforce the following rules:
- When computing the old Merkle root, whenever a new sibling node is absorbed into the hasher state (i.e., ), an entry for this sibling should be included into .
- When computing the new Merkle root, whenever a new sibling node is absorbed into the hasher state (i.e., ), the entry for this sibling should be removed from .
To simplify the description of the constraints, we use variables and defined above and define the value representing an entry in the sibling table as follows:
Using the above value, we can define the constraint for updating as follows:
The above constraint reduces to the following under various flag conditions:
| Condition | Applied constraint |
|---|---|
| Otherwise |
Note that the degree of the above constraint is .
To make sure computation of the old Merkle root is immediately followed by the computation of the new Merkle root, we impose the following constraint:
The above means that whenever we start a new computation which is not the computation of the new Merkle root, the sibling table must be empty. Thus, after the hash chiplet computes the old Merkle root, the only way to clear the table is to compute the new Merkle root.
Together with boundary constraints enforcing that at the first and last rows of the running product column which implements the sibling table, the above constraints ensure that if a node was included into as a part of computing the old Merkle root, the same node must be removed from as a part of computing the new Merkle root. These two boundary constraints are described as part of the chiplets virtual table constraints.