Miden VM decoder AIR constraints
In this section we describe AIR constraints for Miden VM program decoder. These constraints enforce that the execution trace generated by the prover when executing a particular program complies with the rules described in the previous section.
To refer to decoder execution trace columns, we use the names shown on the diagram below (these are the same names as in the previous section). Additionally, we denote the register containing the value at the top of the stack as .

We assume that the VM exposes a flag per operation which is set to when the operation is executed, and to otherwise. The notation for such flags is . For example, when the VM executes a PUSH operation, flag . All flags are mutually exclusive - i.e., when one flag is set to all other flags are set to . The flags are computed based on values in op_bits columns.
AIR constraints for the decoder involve operations listed in the table below. For each operation we also provide the degree of the corresponding flag and the effect that the operation has on the operand stack (however, in this section we do not cover the constraints needed to enforce the correct transition of the operand stack).
| Operation | Flag | Degree | Effect on stack |
|---|---|---|---|
JOIN | 5 | Stack remains unchanged. | |
SPLIT | 5 | Top stack element is dropped. | |
LOOP | 5 | Top stack element is dropped. | |
REPEAT | 4 | Top stack element is dropped. | |
SPAN | 5 | Stack remains unchanged. | |
RESPAN | 4 | Stack remains unchanged. | |
DYN | 5 | Stack remains unchanged. | |
CALL | 4 | Stack remains unchanged. | |
SYSCALL | 4 | Stack remains unchanged. | |
END | 4 | When exiting a loop block, top stack element is dropped; otherwise, the stack remains unchanged. | |
HALT | 4 | Stack remains unchanged. | |
PUSH | 5 | An immediate value is pushed onto the stack. | |
EMIT | 5 | Stack remains unchanged. |
We also use the control flow flag exposed by the VM, which is set when any one of the above control flow operations is being executed. It has degree .
As described previously, the general idea of the decoder is that the prover provides the program to the VM by populating some of cells in the trace non-deterministically. Values in these are then used to update virtual tables (represented via multiset checks) such as block hash table, block stack table etc. Transition constraints are used to ensure that the tables are updates correctly, and we also apply boundary constraints to enforce the correct initial and final states of these tables. One of these boundary constraints binds the execution trace to the hash of the program being executed. Thus, if the virtual tables were updated correctly and boundary constraints hold, we can be convinced that the prover executed the claimed program on the VM.
In the sections below, we describe constraints according to their logical grouping. However, we start out with a set of general constraints which are applicable to multiple parts of the decoder.
General constraints
When SPLIT or LOOP operation is executed, the top of the operand stack must contain a binary value:
When a DYN operation is executed, the hasher registers must all be set to :
When REPEAT operation is executed, the value at the top of the operand stack must be :
Also, when REPEAT operation is executed, the value in column (the is_loop_body flag), must be set to . This ensures that REPEAT operation can be executed only inside a loop:
When RESPAN operation is executed, we need to make sure that the block ID is incremented by :
When END operation is executed and we are exiting a loop block (i.e., is_loop, value which is stored in , is ), the value at the top of the operand stack must be :
Also, when END operation is executed and the next operation is REPEAT, values in (the hash of the current block and the is_loop_body flag) must be copied to the next row:
A HALT instruction can be followed only by another HALT instruction:
When a HALT operation is executed, block address column must be :
Values in op_bits columns must be binary (i.e., either or ):
When the value in in_span column is set to , control flow operations cannot be executed on the VM, but when in_span flag is , only control flow operations can be executed on the VM:
Block hash computation constraints
As described previously, when the VM starts executing a new block, it also initiates computation of the block's hash. There are two separate methodologies for computing block hashes.
For join, split, and loop blocks, the hash is computed directly from the hashes of the block's children. The prover provides these child hashes non-deterministically by populating registers . For dyn, the hasher registers are populated with zeros, so the resulting hash is a constant value. The hasher is initialized using the hash chiplet, and we use the address of the hasher as the block's ID. The result of the hash is available rows down in the hasher table (i.e., at row with index equal to block ID plus ). We read the result from the hasher table at the time the END operation is executed for a given block.
For span blocks, the hash is computed by absorbing a linear sequence of instructions (organized into operation groups and batches) into the hasher and then returning the result. The prover provides operation batches non-deterministically by populating registers . Similarly to other blocks, the hasher is initialized using the hash chiplet at the start of the block, and we use the address of the hasher as the ID of the first operation batch in the block. As we absorb additional operation batches into the hasher (by executing RESPAN operation), the batch address is incremented by . This moves the "pointer" into the hasher table rows down with every new batch. We read the result from the hasher table at the time the END operation is executed for a given block.
Chiplets bus constraints
The decoder communicates with the hash chiplet via the chiplets bus. This works by dividing values of the multiset check column by the values of operations providing inputs to or reading outputs from the hash chiplet. A constraint to enforce this would look as , where is the value which defines the operation.
In constructing value of for decoder AIR constraints, we will use the following labels (see here for an explanation of how values for these labels are computed):
- this label specifies that we are starting a new hash computation.
- this label specifies that we are absorbing the next sequence of elements into an ongoing hash computation.
- this label specifies that we are reading the result of a hash computation.
To simplify constraint description, we define the following variables:
In the above, can be thought of as initiating a hasher with address and absorbing elements from the hasher state () into it. Control blocks are always padded to fill the hasher rate and as such the (first capacity register) term is set to .
It should be noted that refers to a column in the decoder, as depicted. The addresses in this column are set using the address from the hasher chiplet for the corresponding hash initialization / absorption / return. In the case of the value of the address in column in the current row of the decoder is set to equal the value of the address of the row in the hasher chiplet where the previous absorption (or initialization) occurred. is the address of the next row of the decoder, which is set to equal the address in the hasher chiplet where the absorption referred to by the label is happening.
In the above, represents the address value in the decoder which corresponds to the hasher chiplet address at which the hasher was initialized (or the last absorption took place). As such, corresponds to the hasher chiplet address at which the result is returned.
In the above, is set to when a control flow operation that signifies the initialization of a control block is being executed on the VM (only those control blocks that don't do any concurrent requests to the chiplets but). Otherwise, it is set to . An exception is made for the DYN, DYNCALL, and SYSCALL operations, since although they initialize a control block, they also run another concurrent bus request, and so are handled separately.
In the above, represents the opcode value of the opcode being executed on the virtual machine. It is calculated via a bitwise combination of the op bits. We leverage the opcode value to achieve domain separation when hashing control blocks. This is done by populating the second capacity register of the hasher with the value via the term when initializing the hasher.
Using the above variables, we define operation values as described below.
When a control block initializer operation (JOIN, SPLIT, LOOP, CALL) is executed, a new hasher is initialized and the contents of are absorbed into the hasher. As mentioned above, the opcode value is populated in the second capacity register via the term.
As mentioned previously, the value sent by the SYSCALL operation is defined separately, since in addition to communicating with the hash chiplet it must also send a kernel procedure access request to the kernel ROM chiplet. This value of this kernel procedure request is described by .
In the above, is the unique operation label of the kernel procedure call operation. The values contain the root hash of the procedure being called, which is the procedure that must be requested from the kernel ROM chiplet.
The above value sends both the hash initialization request and the kernel procedure access request to the chiplets bus when the SYSCALL operation is executed.
Similar to SYSCALL, DYN and DYNCALL are handled separately, since in addition to communicating with the hash chiplet they must also issue a memory read operation for the hash of the procedure being called.
In the above, can be thought of as , but where the values used for the hasher decoder trace registers is all 0's. represents a memory read request from memory address (the top stack element), where the result is placed in the first half of the decoder hasher trace, and where is a label that represents a memory read request.
When SPAN operation is executed, a new hasher is initialized and contents of are absorbed into the hasher. The number of operation groups to be hashed is padded to a multiple of the rate width () and so the is set to 0:
When RESPAN operation is executed, contents of (which contain the new operation batch) are absorbed into the hasher:
When END operation is executed, the hash result is copied into registers :
Using the above definitions, we can describe the constraint for computing block hashes as follows:
We need to add and subtract the sum of the relevant operation flags to ensure that when none of the flags is set to , the above constraint reduces to .
The degree of this constraint is .
Block stack table constraints
As described previously, block stack table keeps track of program blocks currently executing on the VM. Thus, whenever the VM starts executing a new block, an entry for this block is added to the block stack table. And when execution of a block completes, it is removed from the block stack table.
Adding and removing entries to/from the block stack table is accomplished as follows:
- To add an entry, we multiply the value in column by a value representing a tuple
(blk, prnt, is_loop, ctx_next, fmp_next, b0_next, b1_next, fn_hash_next). A constraint to enforce this would look as , where is the value representing the row to be added. - To remove an entry, we divide the value in column by a value representing a tuple
(blk, prnt, is_loop, ctx_next, fmp_next, b0_next, b1_next, fn_hash_next). A constraint to enforce this would look as , where is the value representing the row to be removed.
Recall that the columns
ctx_next, fmp_next, b0_next, b1_next, fn_hash_nextare only set onCALL,SYSCALL, and their correspondingENDblock. Therefore, for simplicity, we will ignore them when documenting all other block types (such that their values are set to0).
Before describing the constraints for the block stack table, we first describe how we compute the values to be added and removed from the table for each operation. In the below, for block start operations (JOIN, SPLIT, LOOP, SPAN) refers to the ID of the parent block, and refers to the ID of the starting block. For END operation, the situation is reversed: is the ID of the ending block, and is the ID of the parent block. For RESPAN operation, refers to the ID of the current operation batch, refers to the ID of the next batch, and the parent ID for both batches is set by the prover non-deterministically in register .
When JOIN operation is executed, row is added to the block stack table:
When SPLIT operation is executed, row is added to the block stack table:
When LOOP operation is executed, row is added to the block stack table if the value at the top of the operand stack is , and row is added to the block stack table if the value at the top of the operand stack is :
When SPAN operation is executed, row is added to the block stack table:
When RESPAN operation is executed, row is removed from the block stack table, and row is added to the table. The prover sets the value of register at the next row to the ID of the parent block:
When a DYN operation is executed, row is added to the block stack table:
When a DYNCALL operation is executed, row is added to the block stack table:
When a CALL or SYSCALL operation is executed, row is added to the block stack table:
When END operation is executed, how we construct the row will depend on whether the IS_CALL or IS_SYSCALL values are set (stored in registers and respectively). If they are not set, then row is removed from the block span table (where contains the is_loop flag); otherwise, row .
Using the above definitions, we can describe the constraint for updating the block stack table as follows:
We need to add and subtract the sum of the relevant operation flags from each side to ensure that when none of the flags is set to , the above constraint reduces to .
The degree of this constraint is .
In addition to the above transition constraint, we also need to impose boundary constraints against the column to make sure the first and the last values in the column are set to . This enforces that the block stack table starts and ends in an empty state.
Block hash table constraints
As described previously, when the VM starts executing a new program block, it adds hashes of the block's children to the block hash table. And when the VM finishes executing a block, it removes the block's hash from the block hash table. This means that the block hash table gets updated when we execute the JOIN, SPLIT, LOOP, REPEAT, DYN, and END operations (executing SPAN operation does not affect the block hash table because a span block has no children).
Adding and removing entries to/from the block hash table is accomplished as follows:
- To add an entry, we multiply the value in column by a value representing a tuple
(prnt_id, block_hash, is_first_child, is_loop_body). A constraint to enforce this would look as , where is the value representing the row to be added. - To remove an entry, we divide the value in column by a value representing a tuple
(prnt_id, block_hash, is_first_child, is_loop_body). A constraint to enforce this would look as , where is the value representing the row to be removed.
To simplify constraint descriptions, we define values representing left and right children of a block as follows:
Graphically, this looks like so:
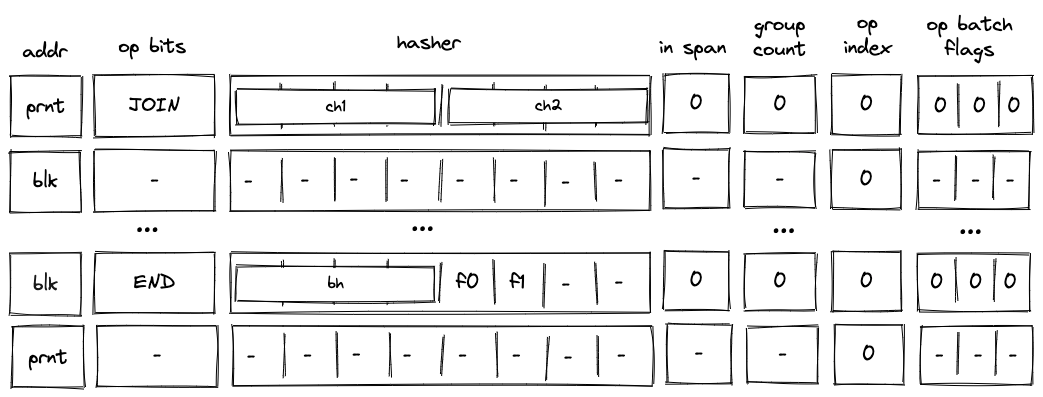
In a similar manner, we define a value representing the result of hash computation as follows:
1
Above, refers to the value in the IS_LOOP_BODY column (already constrained to be 0 or 1), located in . Also, note that we are not adding a flag indicating whether the block is the first child of a join block (i.e., term is missing). It will be added later on.
Using the above variables, we define row values to be added to and removed from the block hash table as follows.
When JOIN operation is executed, hashes of both child nodes are added to the block hash table. We add term to the first child value to differentiate it from the second child (i.e., this sets is_first_child to ):
When SPLIT operation is executed and the top of the stack is , hash of the true branch is added to the block hash table, but when the top of the stack is , hash of the false branch is added to the block hash table:
When LOOP operation is executed and the top of the stack is , hash of loop body is added to the block hash table. We add term to indicate that the child is a body of a loop. The below also means that if the top of the stack is , nothing is added to the block hash table as the expression evaluates to :
When REPEAT operation is executed, hash of loop body is added to the block hash table. We add term to indicate that the child is a body of a loop:
When DYN, DYNCALL, CALL or SYSCALL operation is executed, the hash of the child is added to the block hash table. In all cases, this child is found in the first half of the decoder hasher state.
When END operation is executed, hash of the completed block is removed from the block hash table. However, we also need to differentiate between removing the first and the second child of a join block. We do this by looking at the next operation. Specifically, if the next operation is neither END nor REPEAT nor HALT, we know that another block is about to be executed, and thus, we have just finished executing the first child of a join block. Thus, if the next operation is neither END nor REPEAT nor HALT we need to set the term for coefficient to as shown below:
Using the above definitions, we can describe the constraint for updating the block hash table as follows:
We need to add and subtract the sum of the relevant operation flags from each side to ensure that when none of the flags is set to , the above constraint reduces to .
The degree of this constraint is .
In addition to the above transition constraint, we also need to set the following boundary constraints against the column:
- The first value in the column represents a row for the entire program. Specifically, the row tuple would be
(0, program_hash, 0, 0). This row should be removed from the table when the lastENDoperation is executed. - The last value in the column is - i.e., the block hash table is empty.
Span block
Span block constraints ensure proper decoding of span blocks. In addition to the block stack table constraints and block hash table constraints described previously, decoding of span blocks requires constraints described below.
In-span column constraints
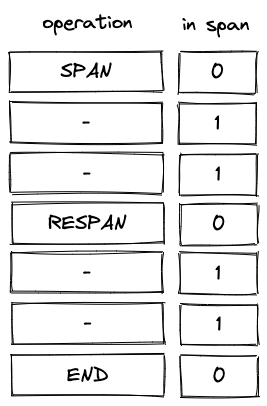
The in_span column (denoted as ) is used to identify rows which execute non-control flow operations. The values in this column are set as follows:
- Executing a
SPANoperation sets the value ofin_spancolumn to . - The value remains until the
ENDoperation is executed. - If
RESPANoperation is executed betweenSPANandENDoperations, in the row at whichRESPANoperation is executedin_spanis set to . It is then reset to in the following row. - In all other cases, value in the
in_spancolumn should be .
The picture below illustrates the above rules.
To enforce the above rules we need the following constraints.
When executing SPAN or RESPAN operation, the next value in column must be set to :
When the next operation is END or RESPAN, the next value in column must be set .
In all other cases, the value in column must be copied over to the next row:
Additionally, we will need to impose a boundary constraint which specifies that the first value in . Note, however, that we do not need to impose a constraint ensuring that values in are binary - this will follow naturally from the above constraints.
Also, note that the combination of the above constraints makes it impossible to execute END or RESPAN operations right after SPAN or RESPAN operations.
Block address constraints
When we are inside a span block, values in block address columns (denoted as ) must remain the same. This can be enforced with the following constraint:
Notice that this constraint does not apply when we execute any of the control flow operations. For such operations, the prover sets the value of the column non-deterministically, except for the RESPAN operation. For the RESPAN operation the value in the column is incremented by , which is enforced by a constraint described previously.
Notice also that this constraint implies that when the next operation is the END operation, the value in the column must also be copied over to the next row. This is exactly the behavior we want to enforce so that when the END operation is executed, the block address is set to the address of the current span batch.
Group count constraints
The group_count column (denoted as ) is used to keep track of the number of operation groups which remains to be executed in a span block.
In the beginning of a span block (i.e., when SPAN operation is executed), the prover sets the value of non-deterministically. This value is subsequently decremented according to the rules described below. By the time we exit the span block (i.e., when END operation is executed), the value in must be .
The rules for decrementing values in the column are as follows:
- The count cannot be decremented by more than in a single row.
- When an operation group is fully executed (which happens when inside a span block), the count is decremented by .
- When
SPAN,RESPAN,EMITorPUSHoperations are executed, the count is decremented by .
Note that these rules imply that the EMIT and PUSH operations cannot be the last operation in an operation group (otherwise the count would have to be decremented by ).
To simplify the description of the constraints, we will define the following variable:
Using this variable, we can describe the constraints against the column as follows:
Inside a span block, group count can either stay the same or decrease by one:
When group count is decremented inside a span block, either must be (we consumed all operations in a group) or we must be executing an operation with an immediate value:
Notice that the above constraint does not preclude and from being true at the same time. If this happens, op group decoding constraints (described here) will force that the operation following the operation with an immediate value is a NOOP.
When executing a SPAN, a RESPAN, or an operation with an immediate value, group count must be decremented by :
If the next operation is either an END or a RESPAN, group count must remain the same:
When an END operation is executed, group count must be :
Op group decoding constraints
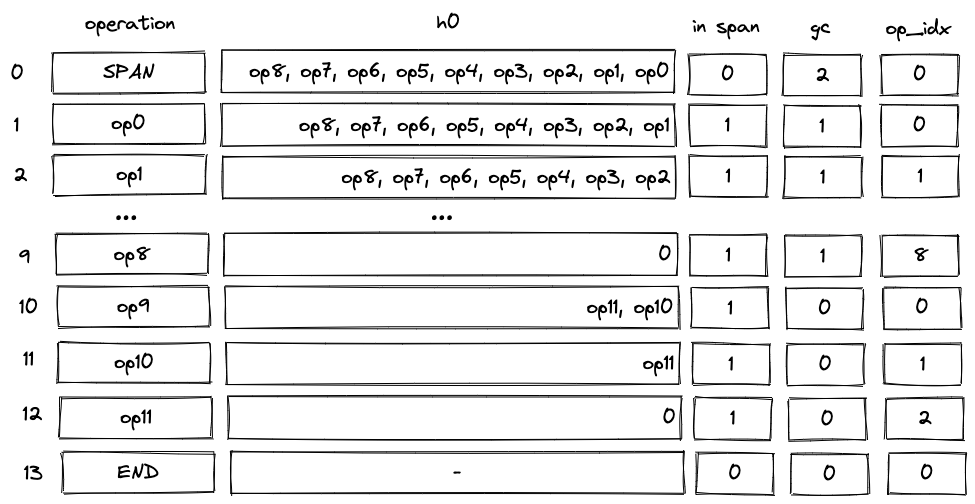
Inside a span block, register is used to keep track of operations to be executed in the current operation group. The value of this register is set by the prover non-deterministically at the time when the prover executes a SPAN or a RESPAN operation, or when processing of a new operation group within a batch starts. The picture below illustrates this.
In the above:
- The prover sets the value of non-deterministically at row . The value is set to an operation group containing operations
op0throughop8. - As we start executing the group, at every row we "remove" the least significant operation from the group. This can be done by subtracting opcode of the operation from the group, and then dividing the result by .
- By row the group is fully executed. This decrements the group count and set
op_indexto (constraints againstop_indexcolumn are described in the next section). - At row we start executing the next group with operations
op9throughop11. In this case, the prover populates with the group having its first operation (op9) already removed, and sets theop_bitsregisters to the value encodingop9. - By row this group is also fully executed.
To simplify the description of the constraints, we define the following variables:
is just an opcode value implied by the values in op_bits registers. is a flag which is set to when the group count within a span block does not change. We multiply it by to make sure the flag is when we are about to end decoding of an operation batch. Note that flag is mutually exclusive with , , and flags as these three operations decrement the group count.
Using these variables, we can describe operation group decoding constraints as follows:
When a SPAN, a RESPAN, or an operation with an immediate value is executed or when the group count does not change, the value in should be decremented by the value of the opcode in the next row.
Notice that when the group count does change, and we are not executing , , or operations, no constraints are placed against , and thus, the prover can populate this register non-deterministically.
When we are in a span block and the next operation is END or RESPAN, the current value in column must be .
Op index constraints
The op_index column (denoted as ) tracks index of an operation within its operation group. It is used to ensure that the number of operations executed per group never exceeds . The index is zero-based, and thus, the possible set of values for is between and (both inclusive).
To simplify the description of the constraints, we will define the following variables:
The value of is set to when we are about to start executing a new operation group (i.e., group count is decremented but we did not execute an operation with an immediate value). Using these variables, we can describe the constraints against the column as follows.
When executing SPAN or RESPAN operations the next value of op_index must be set to :
When starting a new operation group inside a span block, the next value of op_index must be set to . Note that we multiply by to exclude the cases when the group count is decremented because of SPAN or RESPAN operations:
When inside a span block but not starting a new operation group, op_index must be incremented by . Note that we multiply by to exclude the cases when we are about to exit processing of an operation batch (i.e., the next operation is either END or RESPAN):
Values of op_index must be in the range .
Op batch flags constraints
Operation batch flag columns (denoted , , and ) are used to specify how many operation groups are present in an operation batch. This is relevant for the last batch in a span block (or the first batch if there is only one batch in a block) as all other batches should be completely full (i.e., contain 8 operation groups).
These columns are used to define the following 4 flags:
- : there are 8 operation groups in the batch.
- : there are 4 operation groups in the batch.
- : there are 2 operation groups in the batch.
- : there is only 1 operation groups in the batch.
Notice that the degree of is , while the degree of the remaining flags is .
These flags can be set to only when we are executing SPAN or RESPAN operations as this is when the VM starts processing new operation batches. Also, for a given flag we need to ensure that only the specified number of operations groups are present in a batch. This can be done with the following constraints.
All batch flags must be binary:
When SPAN or RESPAN operations is executed, one of the batch flags must be set to .
When neither SPAN nor RESPAN is executed, all batch flags must be set to .
When we have at most 4 groups in a batch, registers should be set to 's.
When we have at most 2 groups in a batch, registers and should also be set to 's.
When we have at most 1 groups in a batch, register should also be set to .
Op group table constraints
Op group table is used to ensure that all operation groups in a given batch are consumed before a new batch is started (i.e., via a RESPAN operation) or the execution of a span block is complete (i.e., via an END operation). The op group table is updated according to the following rules:
- When a new operation batch is started, we add groups from this batch to the table. To add a group to the table, we multiply the value in column by a value representing a tuple
(batch_id, group_pos, group). A constraint to enforce this would look as , where is the value representing the row to be added. Depending on the batch, we may need to add multiple groups to the table (i.e., ). Flags , , , and are used to define how many groups to add. - When a new operation group starts executing or when an immediate value is consumed, we remove the corresponding group from the table. To do this, we divide the value in column by a value representing a tuple
(batch_id, group_pos, group). A constraint to enforce this would look as , where is the value representing the row to be removed.
To simplify constraint descriptions, we first define variables representing the rows to be added to and removed from the op group table.
When a SPAN or a RESPAN operation is executed, we compute the values of the rows to be added to the op group table as follows:
Where . Thus, defines row value for group in , defines row value for group etc. Note that batch address column comes from the next row of the block address column ().
We compute the value of the row to be removed from the op group table as follows:
In the above, the value of the group is computed as . This basically says that when we execute a PUSH or EMIT operation we need to remove the immediate value from the table. For PUSH, this value is at the top of the stack (column ) in the next row; for EMIT, it is found in . However, when we are executing neither a PUSH nor EMIT operation, the value to be removed is an op group value which is a combination of values in and op_bits columns (also in the next row). Note also that value for batch address comes from the current value in the block address column (), and the group position comes from the current value of the group count column ().
We also define a flag which is set to when a group needs to be removed from the op group table.
The above says that we remove groups from the op group table whenever group count is decremented. We multiply by to exclude the cases when the group count is decremented due to SPAN or RESPAN operations.
Using the above variables together with flags , , defined in the previous section, we describe the constraint for updating op group table as follows (note that we do not use flag as when a batch consists of a single group, nothing is added to the op group table):
The above constraint specifies that:
- When
SPANorRESPANoperations are executed, we add between and groups to the op group table; else, leave untouched. - When group count is decremented inside a span block, we remove a group from the op group table; else, leave untouched.
The degree of this constraint is .
In addition to the above transition constraint, we also need to impose boundary constraints against the column to make sure the first and the last value in the column is set to . This enforces that the op group table table starts and ends in an empty state.