Introduction

note
Welcome to the Miden book! The one-stop shop where you can find everything Miden related.
Miden is a rollup for high-throughput, private applications.
Using Polygon Miden, builders can create novel, high-throughput, private applications for payments, DeFi, digital assets, and gaming. Applications and users are secured by Ethereum and AggLayer.
If you want to join the technical discussion, please check out the following:
warning
- These docs are still work-in-progress.
- Some topics have been discussed in greater depth, while others require additional clarification.
Status and features
Polygon Miden is currently on release v0.8 This is an early version of the protocol and its components.
warning
We expect breaking changes on all components.
At the time of writing, Polygon Miden doesn't offer all the features you may expect from a zkRollup yet. During 2025, we expect to gradually implement more features.
Feature highlights
Private accounts
The Miden operator only tracks a commitment to account data in the public database. Users can only execute smart contracts when they know the interface.
Private notes
Like private accounts, the Miden operator only tracks a commitment to notes in the public database. Users need to communicate note details to each other off-chain (via a side channel) in order to consume private notes in transactions.
Public accounts
Polygon Miden supports public smart contracts like Ethereum. The code and state of those accounts are visible to the network and anyone can execute transactions against them.
Public notes
As with public accounts, public notes are also supported. That means, the Miden operator publicly stores note data. Note consumption is not private.
Local transaction execution
The Miden client allows for local transaction execution and proving. The Miden operator verifies the proof and, if valid, updates the state DBs with the new data.
Simple smart contracts
Currently, there are three different smart contracts available. A basic wallet smart contract that sends and receives assets, and fungible and non-fungible faucets to mint and burn assets.
All accounts are written in MASM.
P2ID, P2IDR, and SWAP note scripts
Currently, there are three different note scripts available. Two different versions of pay-to-id scripts of which P2IDR is reclaimable, and a swap script that allows for simple token swaps.
Simple block building
The Miden operator running the Miden node builds the blocks containing transactions.
Maintaining state
The Miden node stores all necessary information in its state DBs and provides this information via its RPC endpoints.
Planned features
warning
The following features are at a planning stage only.
Customized smart contracts
Accounts can expose any interface in the future. This is the Miden version of a smart contract. Account code can be arbitrarily complex due to the underlying Turing-complete Miden VM.
Customized note scripts
Users will be able to write their own note scripts using the Miden client. Note scripts are executed during note consumption and they can be arbitrarily complex due to the underlying Turing-complete Miden VM.
Network transactions
Transaction execution and proving can be outsourced to the network and to the Miden operator. Those transactions will be necessary when it comes to public shared state, and they can be useful if the user's device is not powerful enough to prove transactions efficiently.
Rust compiler
In order to write account code, note or transaction scripts, in Rust, there will be a Rust -> Miden Assembly compiler.
Block and epoch proofs
The Miden node will recursively verify transactions and in doing so build batches of transactions, blocks, and epochs.
Benefits of Polygon Miden
- Ethereum security.
- Developers can build applications that are infeasible on other systems. For example:
- on-chain order book exchange due to parallel transaction execution and updatable transactions.
- complex, incomplete information games due to client-side proving and cheap complex computations.
- safe wallets due to hidden account state.
- Better privacy properties than on Ethereum - first web2 privacy, later even stronger self-sovereignty.
- Transactions can be recalled and updated.
- Lower fees due to client-side proving.
- dApps on Miden are safe to use due to account abstraction and compile-time safe Rust smart contracts.
License
Licensed under the MIT license.
Roadmap
You can find the interactive roadmap here
Miden architecture overview
Polygon Miden’s architecture departs considerably from typical blockchain designs to support privacy and parallel transaction execution.
In traditional blockchains, state and transactions must be transparent to be verifiable. This is necessary for block production and execution.
However, user generated zero-knowledge proofs allow state transitions, e.g. transactions, to be verifiable without being transparent.
Miden design goals
- High throughput: The ability to process a high number of transactions (state changes) over a given time interval.
- Privacy: The ability to keep data known to one’s self and anonymous while processing and/or storing it.
- Asset safety: Maintaining a low risk of mistakes or malicious behavior leading to asset loss.
Actor model
The actor model inspires Polygon Miden’s execution model. This is a well-known computational design paradigm in concurrent systems. In the actor model, actors are state machines responsible for maintaining their own state. In the context of Polygon Miden, each account is an actor. Actors communicate with each other by exchanging messages asynchronously. One actor can send a message to another, but it is up to the recipient to apply the requested change to their state.
Polygon Miden’s architecture takes the actor model further and combines it with zero-knowledge proofs. Now, actors not only maintain and update their own state, but they can also prove the validity of their own state transitions to the rest of the network. This ability to independently prove state transitions enables local smart contract execution, private smart contracts, and much more. And it is quite unique in the rollup space. Normally only centralized entities - sequencer or prover - create zero-knowledge proofs, not the users.
Core concepts
Miden uses accounts and notes, both of which hold assets. Accounts consume and produce notes during transactions. Transactions describe the account state changes of single accounts.
Accounts
An Account can hold assets and define rules how assets can be transferred. Accounts can represent users or autonomous smart contracts. The account chapter describes the design of an account, its storage types, and creating an account.
Notes
A Note is a message that accounts send to each other. A note stores assets and a script that defines how the note can be consumed. The note chapter describes the design, the storage types, and the creation of a note.
Assets
An Asset can be fungible and non-fungible. They are stored in the owner’s account itself or in a note. The asset chapter describes asset issuance, customization, and storage.
Transactions
A Transactions describe the production and consumption of notes by a single account.
Executing a transaction always results in a STARK proof.
The transaction chapter describes the transaction design and implementation, including an in-depth discussion of how transaction execution happens in the transaction kernel program.
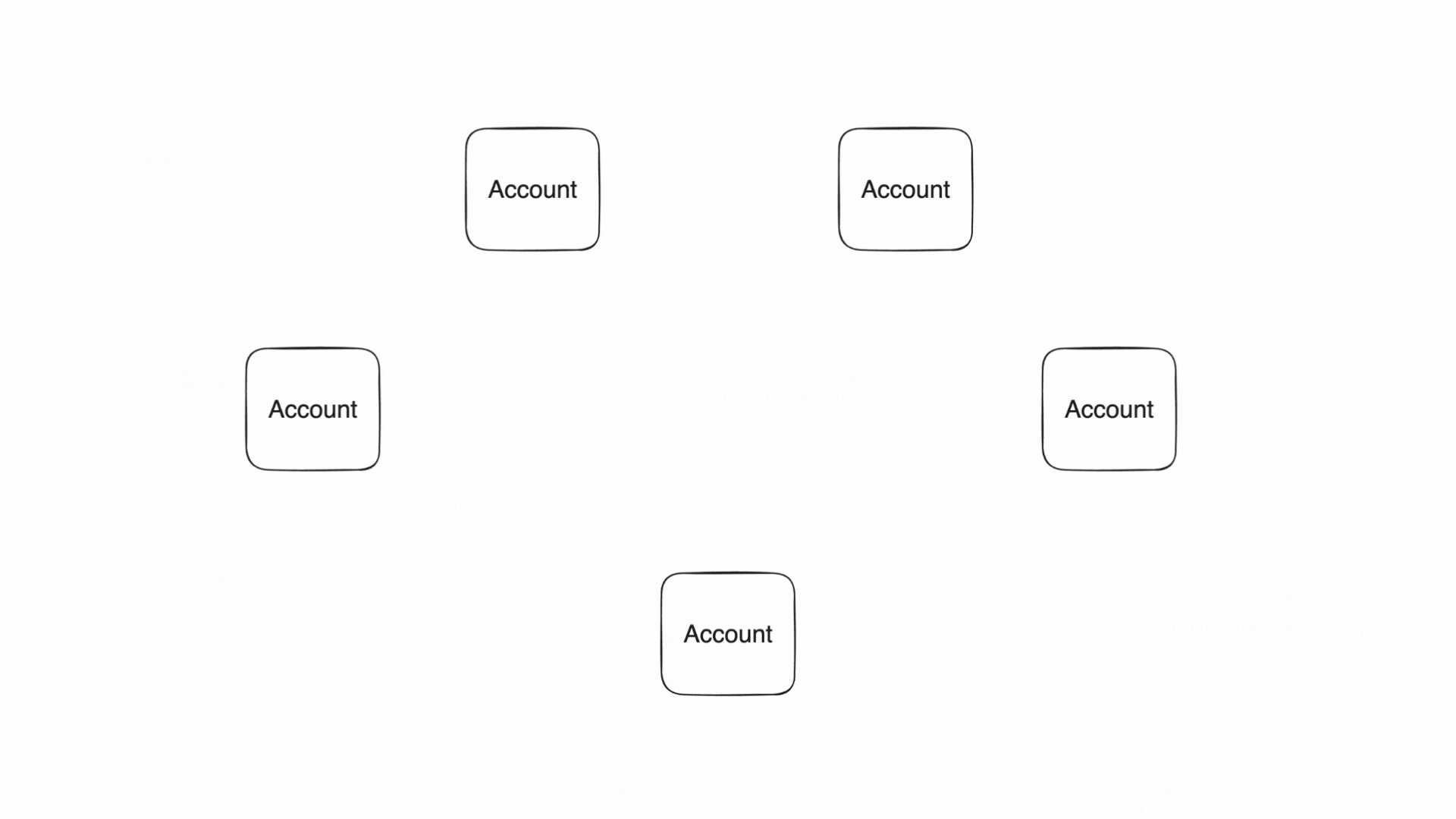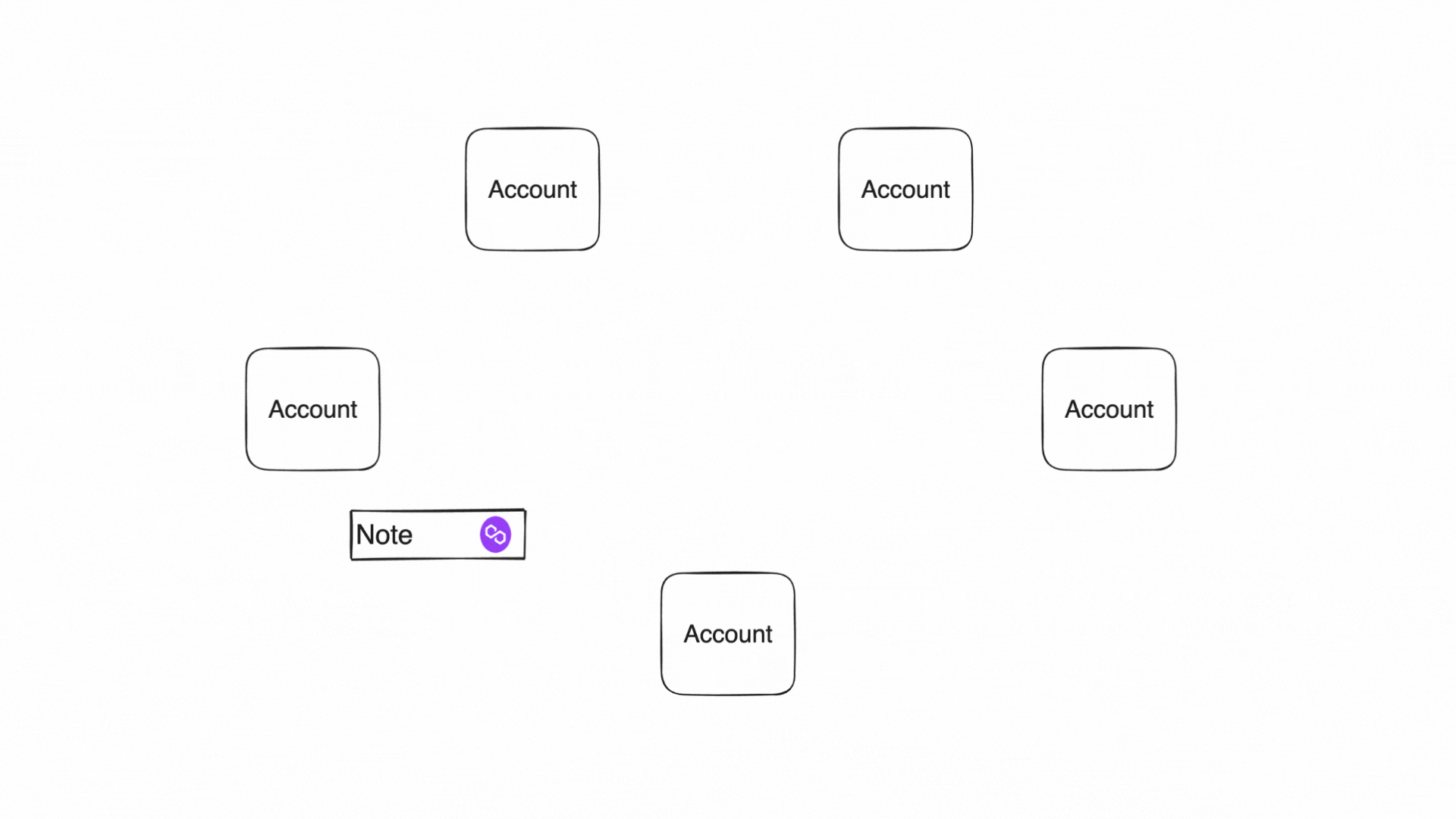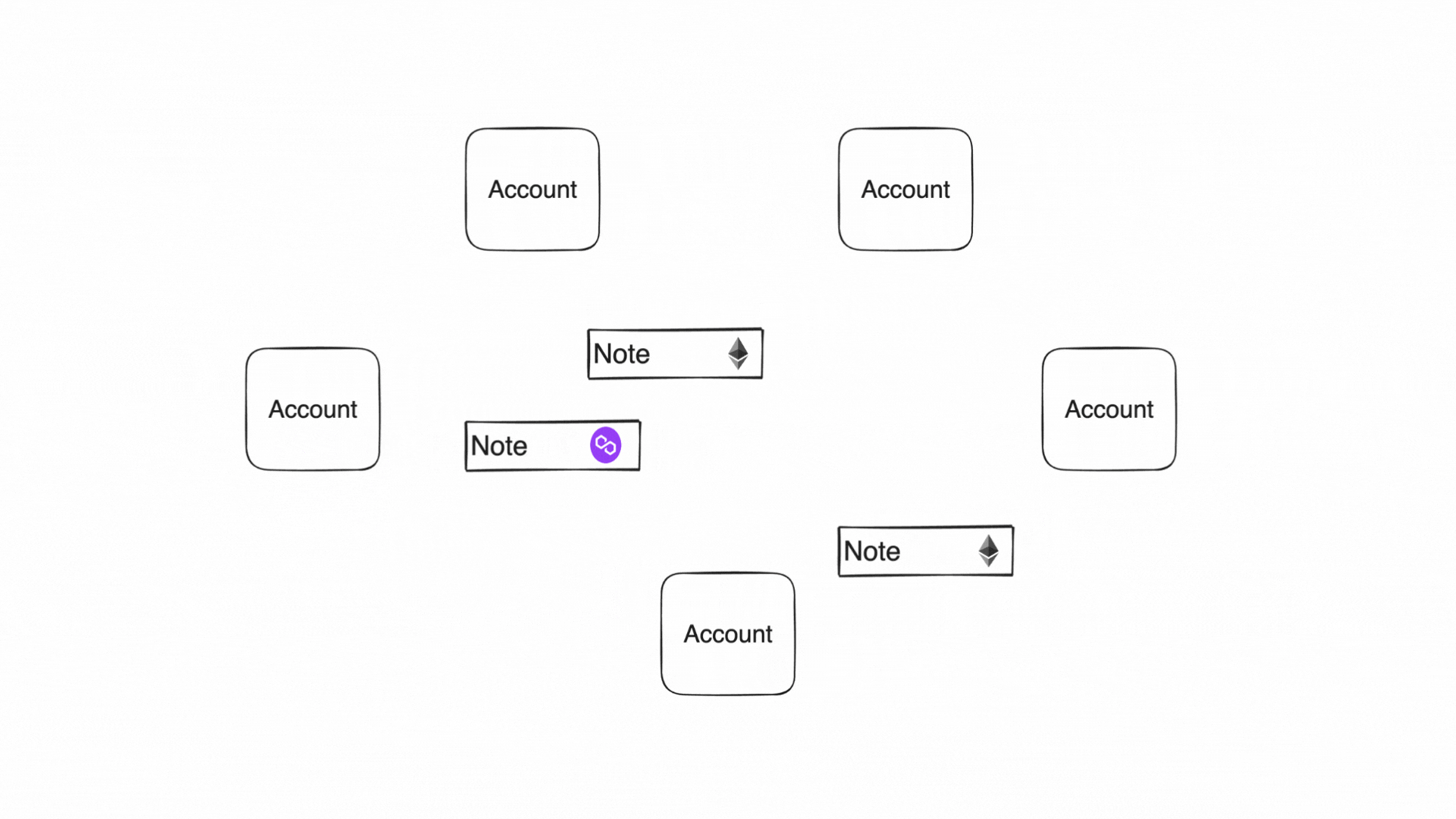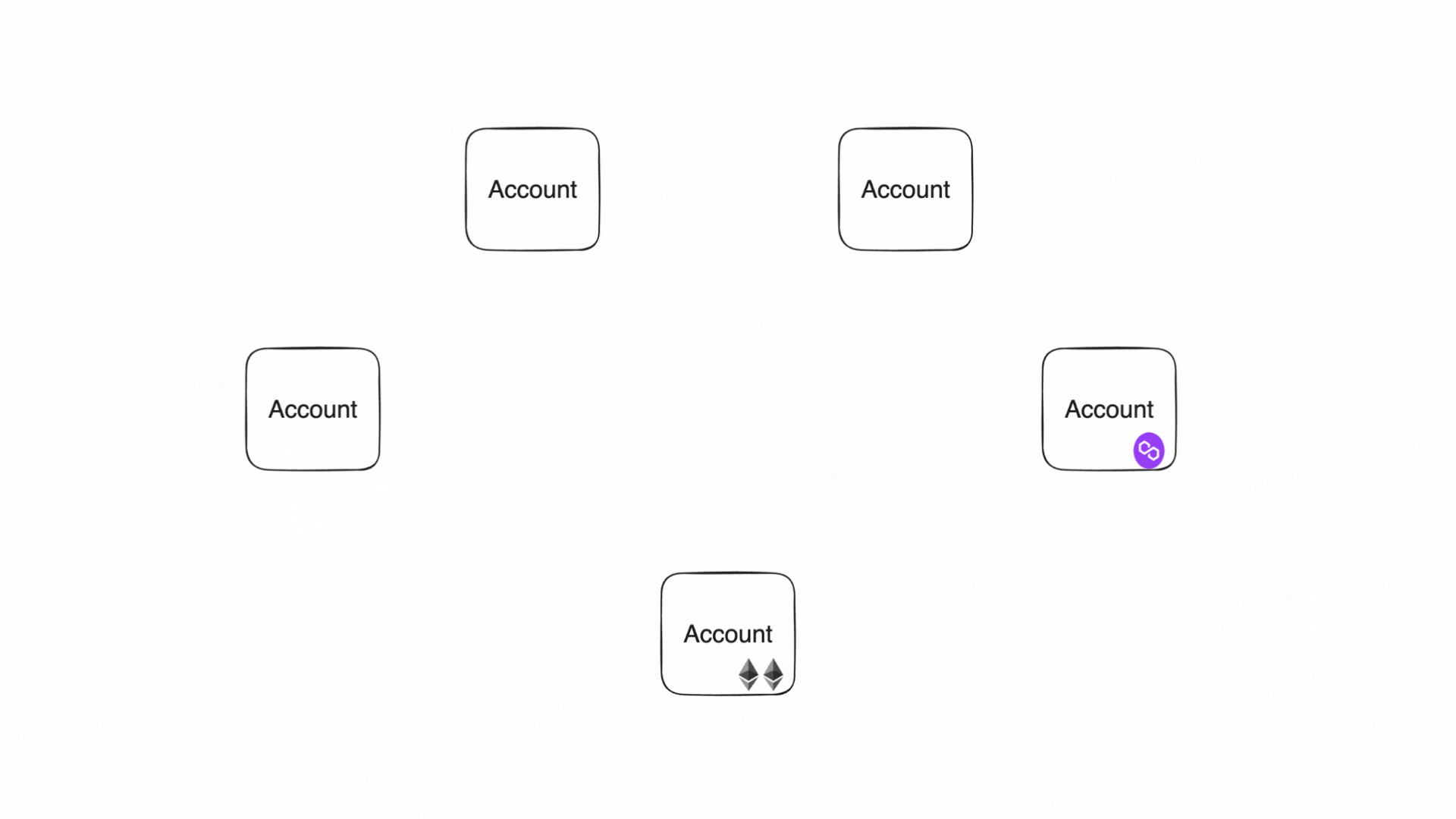
Accounts produce and consume notes to communicate
State and execution
The actor-based execution model requires a radically different approach to recording the system's state. Actors and the messages they exchange must be treated as first-class citizens. Polygon Miden addresses this by combining the state models of account-based systems like Ethereum and UTXO-based systems like Bitcoin and Zcash.
Miden's state model captures the individual states of all accounts and notes, and the execution model describes state progress in a sequence of blocks.
State model
State describes everything that is the case at a certain point in time. Individual states of accounts or notes can be stored on-chain and off-chain. This chapter describes the three different state databases in Miden.
Blockchain
The Blockchain defines how state progresses as aggregated-state-updates in batches, blocks, and epochs. The blockchain chapter describes the execution model and how blocks are built.
Operators capture and progress state

Accounts / Smart Contracts
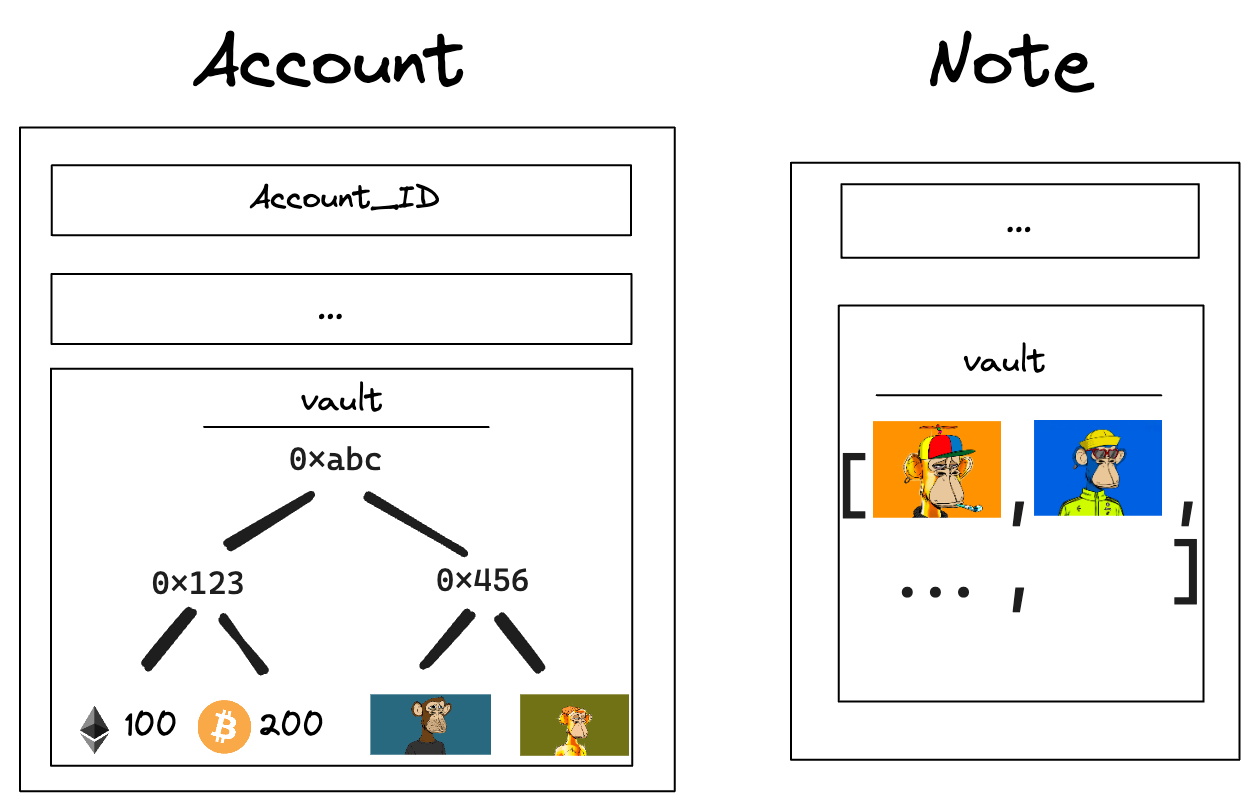
An Account represents the primary entity of the protocol. Capable of holding assets, storing data, and executing custom code. Each Account is a specialized smart contract providing a programmable interface for interacting with its state and assets.
What is the purpose of an account?
In Miden's hybrid UTXO- and account-based model Accounts enable the creation of expressive smart contracts via a Turing-complete language.
Account core elements
An Account is composed of several core elements, illustrated below:
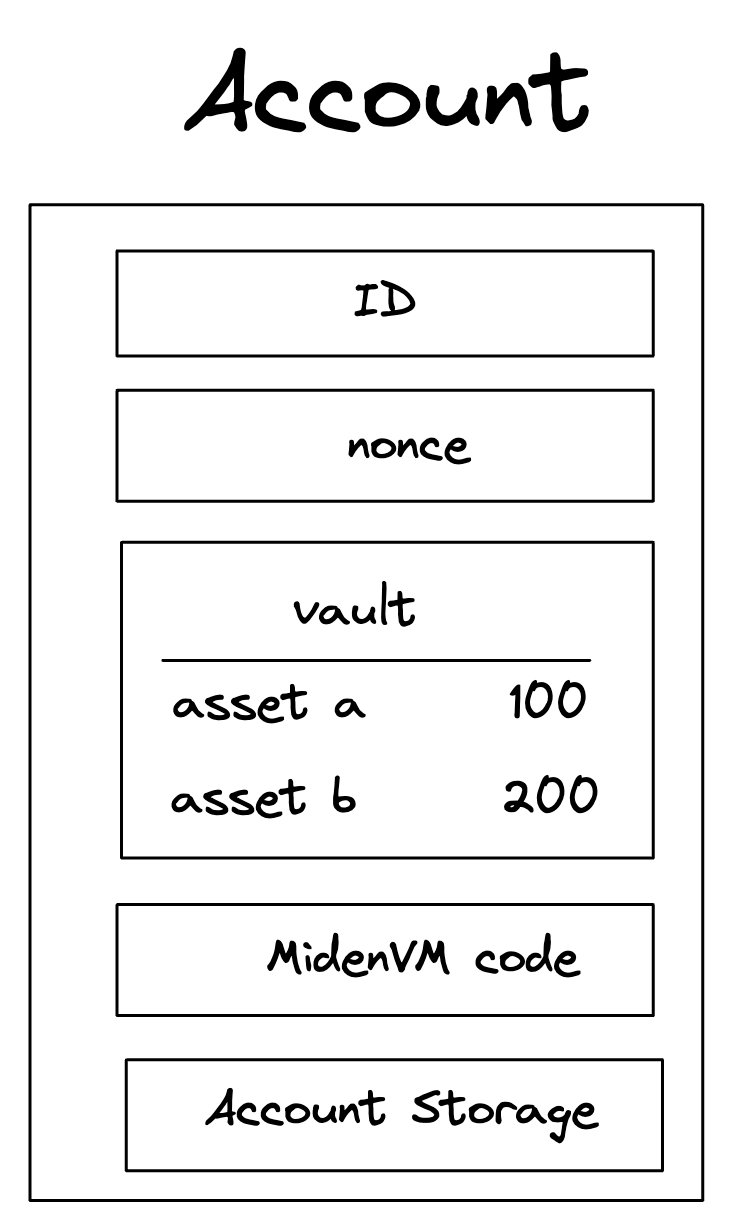
These elements are:
ID
note
An immutable and unique identifier for the Account.
A 120-bit long number represents the Account ID. This identifier is structured to encapsulate specific account metadata while preventing precomputed attack vectors (e.g., rainbow table attacks).
The ID is generated by hashing a user-generated random seed together with commitments to the initial code and storage of the Account and the anchor block. The anchor block refers to specific blockchain epoch block in which the account is created. The resulting 256-bit long hash is then manipulated and shortened to 120-bit. Manipulation includes encoding the account type, account storage mode, the version of the Account ID scheme, and the anchor block.
Account type, storage mode, and version are included in the ID, to ensure these properties can be determined without additional computation. Anyone can immediately tell those properties by just looking at the ID in bit representation.
Also, the ID generation process ensures that an attacker cannot precompute an ID before the anchor block's commitment is available. This significantly mitigates the risk of ID hijacking, where an adversary might attempt to claim assets sent to an unregistered ID. By anchoring the ID to a recent epoch block, the window for potential attacks is minimized, reinforcing the security of asset transfers and account registration.
An Account ID is considered invalid if:
- The metadata (storage mode, type, or version) does not match any recognized values.
- The anchor epoch exceeds .
- The least significant 8 bits of the ID are nonzero.
An Account ID can be encoded in different formats:
- Bech32 (default):
- Example:
mm1qq2qlgz2reslcyqqqqfxa7836chrjcvk - Benefits:
- Built-in error detection via checksum algorithm
- Human-readable prefix indicates network type
- Less prone to transcription errors
- Structure:
- Human-readable prefix:
mm(e.g., indicates Miden Mainnet) - Separator:
1 - Data part with integrated checksum
- Human-readable prefix:
- Example:
Info
- We strongly recommend encoding account ID's using Bech32 for all user-facing applications
- Hexadecimal (debugging):
- Example:
0x140fa04a1e61fc100000126ef8f1d6 - Frequenty used encoding for blockchain addresses
- Example:
Code
note
A collection of functions defining the Account’s programmable interface.
Every Miden Account is essentially a smart contract. The Code component defines the account’s functions, which can be invoked through both Note scripts and transaction scripts. Key characteristics include:
- Mutable access: Only the
Account’s own functions can modify its storage and vault. All state changes—such as updating storage slots, incrementing the nonce, or transferring assets—must occur through these functions. - Function commitment: Each function can be called by its MAST root. The root represents the underlying code tree as a 32-byte commitment. This ensures integrity, i.e., the caller calls what he expects.
- Note creation:
Accountfunctions can generate new notes.
Storage
note
A flexible, arbitrary data store within the Account.
The storage is divided into a maximum of 255 indexed storage slots. Each slot can either store a 32-byte value or serve as a pointer to a key-value store with large amounts capacity.
StorageSlot::Value: Contains 32 bytes of arbitrary data.StorageSlot::Map: Contains a StorageMap, a key-value store where both keys and values are 32 bytes. The slot's value is a commitment to the entire map.
Vault
note
A collection of assets stored by the Account.
Large amounts of fungible and non-fungible assets can be stored in the Accounts vault.
Nonce
note
A counter incremented with each state update to the Account.
The nonce enforces ordering and prevents replay attacks. It must strictly increase with every Account state update. The increment must be less than but always greater than the previous nonce, ensuring a well-defined sequence of state changes.
If a smart contract function should be callable by other users, it must increment the Account's nonce. Otherwise, only the contract owner—i.e., the party possessing the contract's key—can execute the function.
Account lifecycle
Throughout its lifetime, an Account progresses through various phases:
- Creation and Deployment: Initialization of the
Accounton the network. - Active Operation: Continuous state updates via
Accountfunctions that modify the storage, nonce, and vault. - Termination or Deactivation: Optional, depending on the contract’s design and governance model.
Account creation
For an Account to be recognized by the network, it must exist in the account database maintained by Miden node(s).
However, a user can locally create a new Account ID before it’s recognized network-wide. The typical process might be:
- Alice generates a new
AccountID locally (according to the desiredAccounttype) using the Miden client. - The Miden client checks with a Miden node to ensure the ID does not already exist.
- Alice shares the new ID with Bob (for example, to receive assets).
- Bob executes a transaction, creating a note containing assets for Alice.
- Alice consumes Bob’s note in her own transaction to claim the asset.
- Depending on the
Account’s storage mode and transaction type, the operator receives the newAccountID and, if all conditions are met, includes it in theAccountdatabase.
Additional information
Account type
There are two main categories of Accounts in Miden: basic accounts and faucets.
-
Basic Accounts: Basic Accounts may be either mutable or immutable:
- Mutable: Code can be changed after deployment.
- Immutable: Code cannot be changed once deployed.
-
Faucets: Faucets are always immutable and can be specialized by the type of assets they issue:
Type and mutability are encoded in the two most significant bits of the Account's ID.
Account storage mode
Users can choose whether their Accounts are stored publicly or privately. The preference is encoded in the third and forth most significant bits of the Accounts ID:
-
Public
Accounts: TheAccount’s state is stored on-chain, similar to howAccounts are stored in public blockchains like Ethereum. Contracts that rely on a shared, publicly accessible state (e.g., a DEX) should be public. -
Private
Accounts: Only a commitment (hash) to theAccount’s state is stored on-chain. This mode is suitable for users who prioritize privacy or plan to store a large amount of data in theirAccount. To interact with a privateAccount, a user must have knowledge of its interface.
The storage mode is chosen during Account creation, it cannot be changed later.
Account component templates
An account component template provides a general description of an account component. It encapsulates all the information needed to initialize and manage the component.
Specifically, a template specifies a component's metadata and its code.
Once defined, a component template can be instantiated as account components, which can then be merged to form the account's Code.
Component code
The component template’s code defines a library of functions that operate on the specified storage layout.
Component metadata
The component metadata describes the account component entirely: its name, description, version, and storage layout.
The storage layout must specify a contiguous list of slot values that starts at index 0, and can optionally specify initial values for each of the slots. Alternatively, placeholders can be utilized to identify values that should be provided at the moment of instantiation.
TOML specification
The component metadata can be defined using TOML. Below is an example specification:
name = "Fungible Faucet"
description = "This component showcases the component template format, and the different ways of
providing valid values to it."
version = "1.0.0"
supported-types = ["FungibleFaucet"]
[[storage]]
name = "token_metadata"
description = "Contains metadata about the token associated to the faucet account. The metadata
is formed by three fields: max supply, the token symbol and the asset's decimals"
slot = 0
value = [
{ type = "felt", name = "max_supply", description = "Maximum supply of the token in base units" },
{ type = "token_symbol", value = "TST" },
{ type = "u8", name = "decimals", description = "Number of decimal places for converting to absolute units", value = "10" },
{ value = "0x0" }
]
[[storage]]
name = "owner_public_key"
description = "This is a value placeholder that will be interpreted as a Falcon public key"
slot = 1
type = "auth::rpo_falcon512::pub_key"
[[storage]]
name = "map_storage_entry"
slot = 2
values = [
{ key = "0x1", value = ["0x0", "249381274", "998123581", "124991023478"] },
{ key = "0xDE0B1140012A9FD912F18AD9EC85E40F4CB697AE", value = { name = "value_placeholder", description = "This value will be defined at the moment of instantiation" } }
]
[[storage]]
name = "multislot_entry"
slots = [3,4]
values = [
["0x1","0x2","0x3","0x4"],
["50000","60000","70000","80000"]
]
Specifying values and their types
In the TOML format, any value that is one word long can be written as a single value, or as exactly four field elements. In turn, a field element is a number within Miden's finite field.
A word can be written as a hexadecimal value, and field elements can be written either as hexadecimal or decimal numbers. In all cases, numbers should be input as strings.
In our example, the token_metadata single-slot entry is defined as four elements, where the first element is a placeholder, and the second, third and fourth are hardcoded values.
Word types
Valid word types are word (default type) and auth::rpo_falcon512::pub_key (represents a Falcon public key). Both can be written and interpreted as hexadecimal strings.
Felt types
Valid field element types are u8, u16, u32, felt (default type) and token_symbol:
u8,u16andu32values can be parsed as decimal numbers and represent 8-bit, 16-bit and 32-bit unsigned integersfeltvalues represent a field element, and can be parsed as decimal or hexadecimal valuestoken_symbolvalues represent the symbol for basic fungible tokens, and are parsed as strings made of four uppercase characters
Header
The metadata header specifies four fields:
name: The component template's namedescription(optional): A brief description of the component template and its functionalityversion: A semantic version of this component templatesupported-types: Specifies the types of accounts on which the component can be used. Valid values areFungibleFaucet,NonFungibleFaucet,RegularAccountUpdatableCodeandRegularAccountImmutableCode
Storage entries
An account component template can have multiple storage entries. A storage entry can specify either a single-slot value, a multi-slot value, or a storage map.
Each of these storage entries contain the following fields:
name: A name for identifying the storage entrydescription(optional): Describes the intended function of the storage slot within the component definition
Additionally, based on the type of the storage entry, there are specific fields that should be specified.
Single-slot value
A single-slot value fits within one slot (i.e., one word).
For a single-slot entry, the following fields are expected:
slot: Specifies the slot index in which the value will be placedvalue(optional): Contains the initial storage value for this slot. Will be interpreted as awordunless anothertypeis specifiedtype(optional): Describes the expected type for the slot
If no value is provided, the entry acts as a placeholder, requiring a value to be passed at instantiation. In this case, specifying a type is mandatory to ensure the input is correctly parsed. So the rule is that at least one of value and type has to be specified.
Valid types for a single-slot value are word or auth::rpo_falcon512::pub_key.
In the above example, the first and second storage entries are single-slot values.
Storage map entries
Storage maps consist of key-value pairs, where both keys and values are single words.
Storage map entries can specify the following fields:
slot: Specifies the slot index in which the root of the map will be placedvalues: Contains a list of map entries, defined by akeyandvalue
Where keys and values are word values, which can be defined as placeholders.
In the example, the third storage entry defines a storage map.
Multi-slot value
Multi-slot values are composite values that exceed the size of a single slot (i.e., more than one word).
For multi-slot values, the following fields are expected:
slots: Specifies the list of contiguous slots that the value comprisesvalues: Contains the initial storage value for the specified slots
Placeholders can currently not be defined for multi-slot values. In our example, the fourth entry defines a two-slot value.
Notes
A Note is the medium through which Accounts communicate. A Note holds assets and defines how they can be consumed.
What is the purpose of a note?
In Miden's hybrid UTXO and account-based model Notes represent UTXO's which enable parallel transaction execution and privacy through asynchronous local Note production and consumption.
Note core components
A Note is composed of several core components, illustrated below:
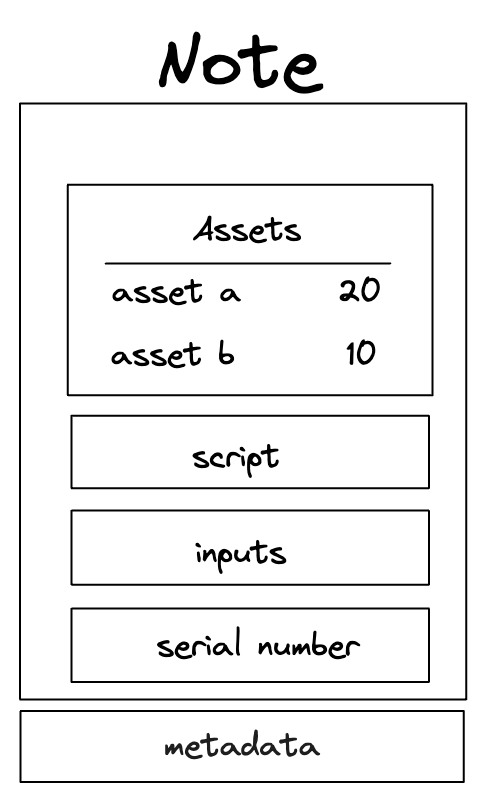
These components are:
Assets
note
An asset container for a Note.
A Note can contain from 0 up to 256 different assets. These assets represent fungible or non-fungible tokens, enabling flexible asset transfers.
Script
note
The code executed when the Note is consumed.
Each Note has a script that defines the conditions under which it can be consumed. When accounts consume Notes in transactions, Note scripts call the account’s interface functions. This enables all sorts of operations beyond simple asset transfers. The Miden VM’s Turing completeness allows for arbitrary logic, making Note scripts highly versatile. There is no limit to the amount of code a Note can hold.
Inputs
note
Arguments passed to the Note script during execution.
A Note can have up to 128 input values, which adds up to a maximum of 1 KB of data. The Note script can access these inputs. They can convey arbitrary parameters for Note consumption.
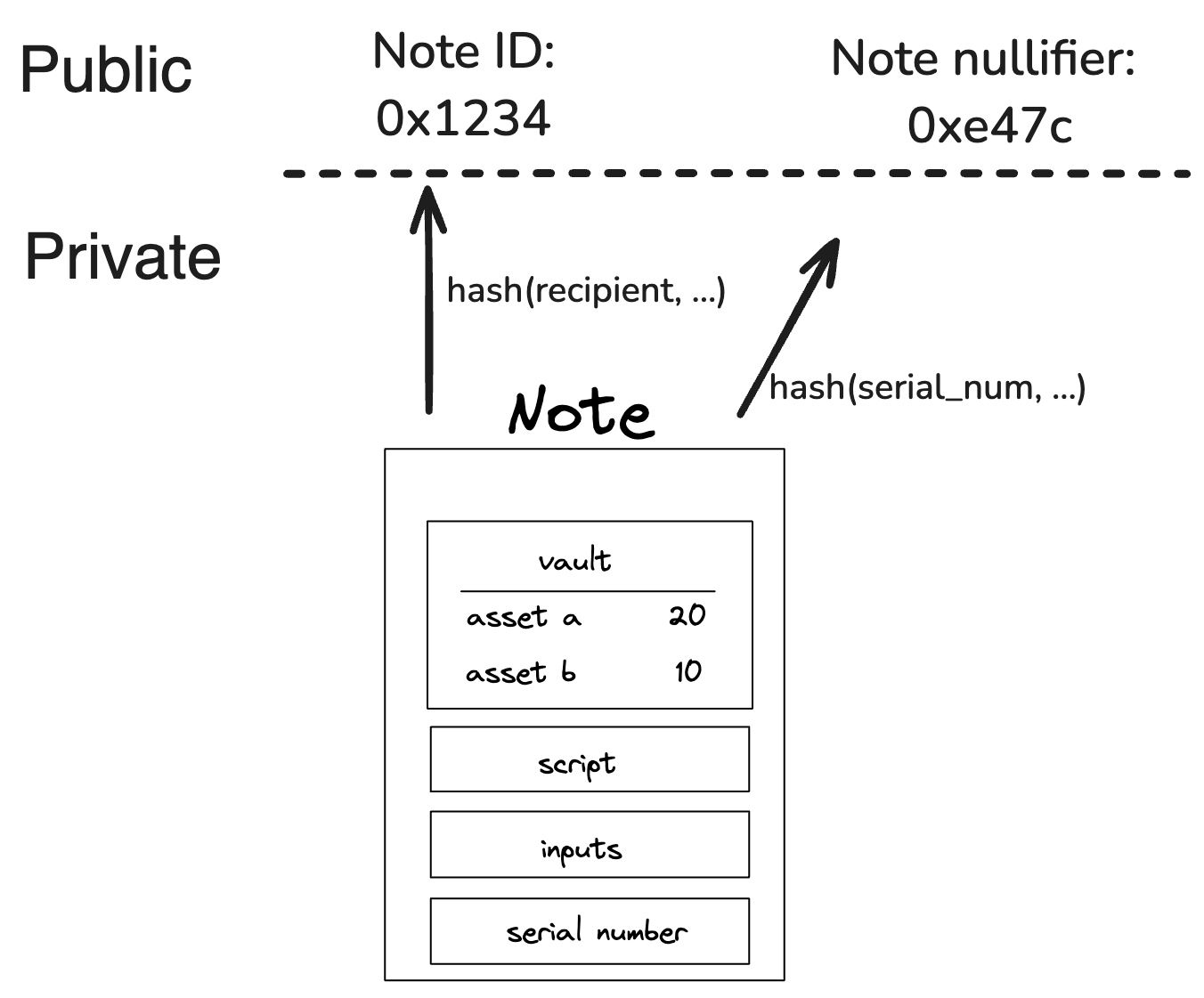
Serial number
note
A unique and immutable identifier for the Note.
The serial number has two main purposes. Firstly by adding some randomness to the Note it ensures it's uniqueness, secondly in private Notes it helps prevent linkability between the Note's hash and its nullifier. The serial number should be a random 32 bytes number chosen by the user. If leaked, the Note’s nullifier can be easily computed, potentially compromising privacy.
Metadata
note
Additional Note information.
Notes include metadata such as the sender’s account ID and a tag that aids in discovery. Regardless of storage mode, these metadata fields remain public.
Note Lifecycle
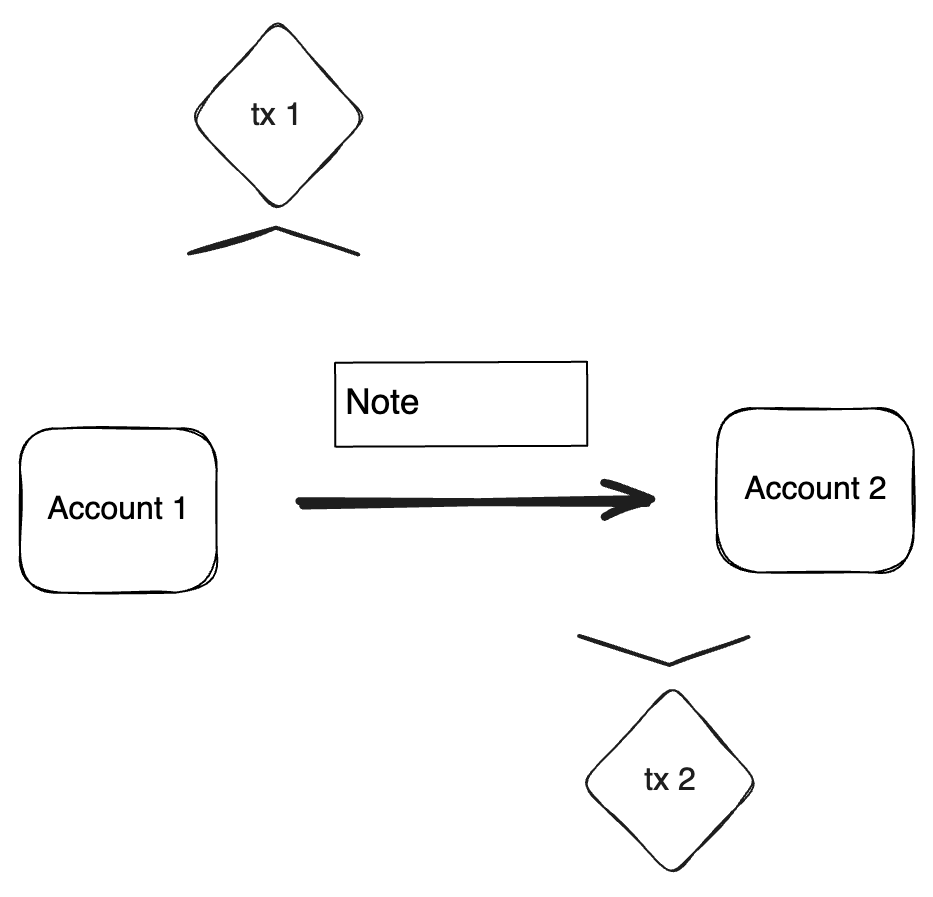
The Note lifecycle proceeds through four primary phases: creation, validation, discovery, and consumption. Creation and consumption requires two separate transactions. Throughout this process, Notes function as secure, privacy-preserving vehicles for asset transfers and logic execution.
Note creation
Accounts can create Notes in a transaction. The Note exists if it is included in the global Notes DB.
- Users: Executing local or network transactions.
- Miden operators: Facilitating on-chain actions, e.g. such as executing user
Notes against a DEX or other contracts.
Note storage mode
As with accounts, Notes can be stored either publicly or privately:
- Public mode: The
Notedata is stored in the note database, making it fully visible on-chain. - Private mode: Only the
Note’s hash is stored publicly. TheNote’s actual data remains off-chain, enhancing privacy.
Note validation
Once created, a Note must be validated by a Miden operator. Validation involves checking the transaction proof that produced the Note to ensure it meets all protocol requirements.
After validation Notes become “live” and eligible for consumption. If creation and consumption happens within the same block, there is no entry in the Notes DB. All other notes, are being added either as a commitment or fully public.
Note discovery
Clients often need to find specific Notes of interest. Miden allows clients to query the Note database using Note tags. These lightweight, 32-bit data fields serve as best-effort filters, enabling quick lookups for Notes related to particular use cases, scripts, or account prefixes.
Using Note tags strikes a balance between privacy and efficiency. Without tags, querying a specific Note ID reveals a user’s interest to the operator. Conversely, downloading and filtering all registered Notes locally is highly inefficient. Tags allow users to adjust their level of privacy by choosing how broadly or narrowly they define their search criteria, letting them find the right balance between revealing too much information and incurring excessive computational overhead.
Note consumption
To consume a Note, the consumer must know its data, including the inputs needed to compute the nullifier. Consumption occurs as part of a transaction. Upon successful consumption a nullifier is generated for the consumed Notes.
Upon successful verification of the transaction:
- The Miden operator records the
Note’s nullifier as “consumed” in the nullifier database. - The
Note’s one-time claim is thus extinguished, preventing reuse.
Note recipient restricting consumption
Consumption of a Note can be restricted to certain accounts or entities. For instance, the P2ID and P2IDR Note scripts target a specific account ID. Alternatively, Miden defines a RECIPIENT (represented as 32 bytes) computed as:
hash(hash(hash(serial_num, [0; 4]), script_root), input_commitment)
Only those who know the RECIPIENT’s pre-image can consume the Note. For private Notes, this ensures an additional layer of control and privacy, as only parties with the correct data can claim the Note.
The transaction prologue requires all necessary data to compute the Note hash. This setup allows scenario-specific restrictions on who may consume a Note.
For a practical example, refer to the SWAP note script, where the RECIPIENT ensures that only a defined target can consume the swapped asset.
Note nullifier ensuring private consumption
The Note nullifier, computed as:
hash(serial_num, script_root, input_commitment, vault_hash)
This achieves the following properties:
- Every
Notecan be reduced to a single unique nullifier. - One cannot derive a
Note's hash from its nullifier. - To compute the nullifier, one must know all components of the
Note: serial_num, script_root, input_commitment, and vault_hash.
That means if a Note is private and the operator stores only the Note's hash, only those with the Note details know if this Note has been consumed already. Zcash first introduced this approach.
Assets
An Asset is a unit of value that can be transferred from one account to another using notes.
What is the purpose of an asset?
In Miden, Assets serve as the primary means of expressing and transferring value between accounts through notes. They are designed with four key principles in mind:
-
Parallelizable exchange:
By managing ownership and transfers directly at the account level instead of relying on global structures like ERC20 contracts, accounts can exchangeAssets concurrently, boosting scalability and efficiency. -
Self-sovereign ownership:
Assets are stored in the accounts directly. This ensures that users retain complete control over theirAssets. -
Censorship resistance:
Users can transact freely and privately with no single contract or entity controllingAssettransfers. This reduces the risk of censored transactions, resulting in a more open and resilient system. -
Flexible fee payment:
Unlike protocols that require a specific baseAssetfor fees, Miden allows users to pay fees in any supportedAsset. This flexibility simplifies the user experience.
Native asset
note
All data structures following the Miden asset model that can be exchanged.
Native Assets adhere to the Miden Asset model (encoding, issuance, storage). Every native Asset is encoded using 32 bytes, including both the ID of the issuing account and the Asset details.
Issuance
note
Only faucet accounts can issue assets.
Faucets can issue either fungible or non-fungible Assets as defined at account creation. The faucet's code specifies the Asset minting conditions: i.e., how, when, and by whom these Assets can be minted. Once minted, they can be transferred to other accounts using notes.
Type
Fungible asset
Fungible Assets are encoded with the amount and the faucet_id of the issuing faucet. The amount is always or smaller, representing the maximum supply for any fungible Asset. Examples include ETH and various stablecoins (e.g., DAI, USDT, USDC).
Non-fungible asset
Non-fungible Assets are encoded by hashing the Asset data into 32 bytes and placing the faucet_id as the second element. Examples include NFTs like a DevCon ticket.
Storage
Accounts and notes have vaults used to store Assets. Accounts use a sparse Merkle tree as a vault while notes use a simple list. This enables an account to store a practically unlimited number of assets while a note can only store 255 assets.
Burning
Assets in Miden can be burned through various methods, such as rendering them unspendable by storing them in an unconsumable note, or sending them back to their original faucet for burning using it's dedicated function.
Alternative asset models
note
All data structures not following the Miden asset model that can be exchanged.
Miden is flexible enough to support other Asset models. For example, developers can replicate Ethereum’s ERC20 pattern, where fungible Asset ownership is recorded in a single account. To transact, users send a note to that account, triggering updates in the global hashmap state.
Transactions
A Transaction in Miden is the state transition of a single account. A Transaction takes as input a single account and zero or more notes, and outputs the same account with an updated state, together with zero or more notes. Transactions in Miden are Miden VM programs, their execution resulting in the generation of a zero-knowledge proof.
Miden's Transaction model aims for the following:
- Parallel transaction execution: Accounts can update their state independently from each other and in parallel.
- Private transaction execution: Client-side
Transactionproving allows the network to verifyTransactions validity with zero knowledge.
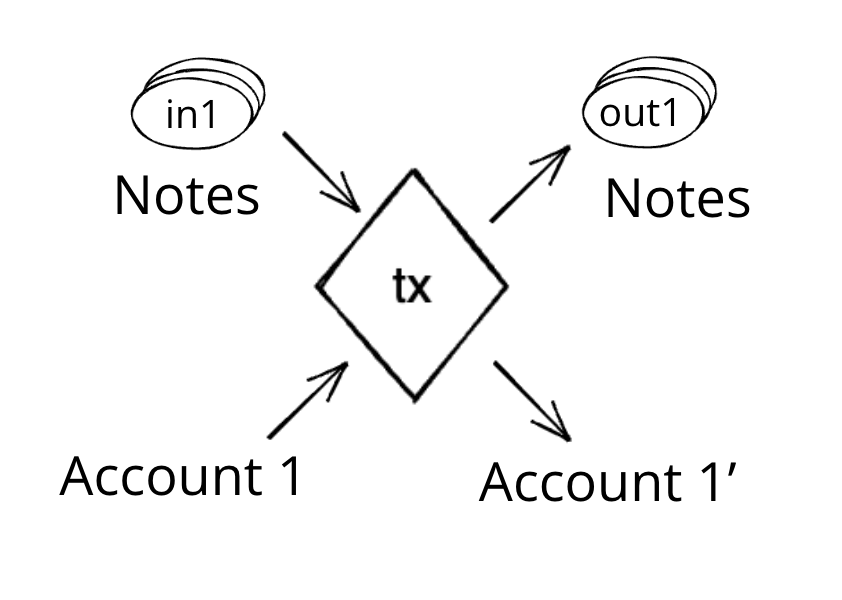
Compared to most blockchains, where a Transaction typically involves more than one account (e.g., sender and receiver), a Transaction in Miden involves a single account. To illustrate, Alice sends 5 ETH to Bob. In Miden, sending 5 ETH from Alice to Bob takes two Transactions, one in which Alice creates a note containing 5 ETH and one in which Bob consumes that note and receives the 5 ETH. This model removes the need for a global lock on the blockchain's state, enabling Miden to process Transactions in parallel.
Currently the protocol limits the number of notes that can be consumed and produced in a transaction to 1000 each, which means that in a single Transaction an application could serve up to 2000 different user requests like deposits or withdrawals into/from a pool.
A simple transaction currently takes about 1-2 seconds on a MacBook Pro. It takes around 90K cycles to create the proof, as of now the signature verification step is the dominant cost.
Transaction lifecycle
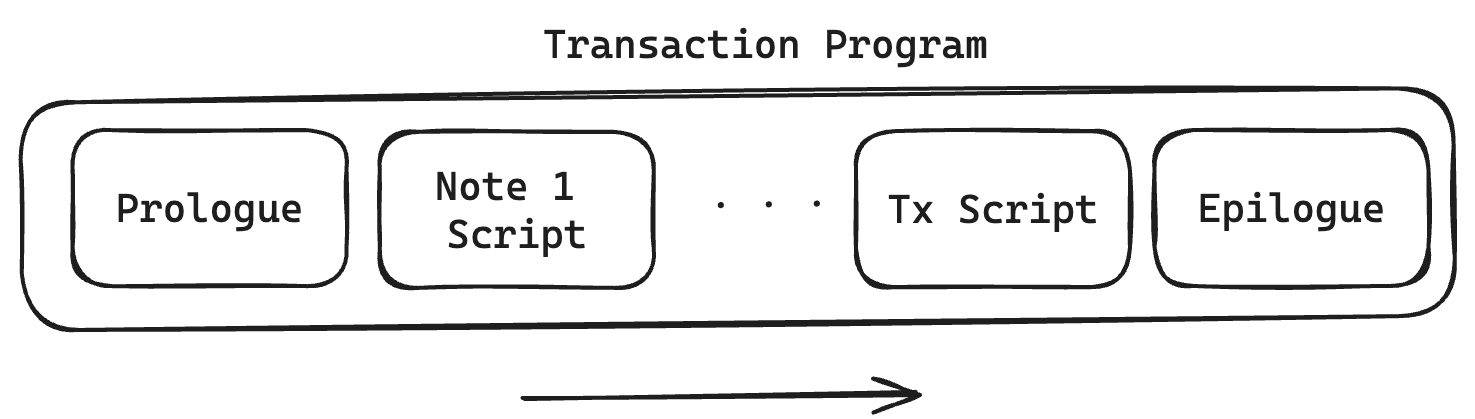
Every Transaction describes the process of an account changing its state. This process is described as a Miden VM program, resulting in the generation of a zero-knowledge proof. Transactions are being executed in a specified sequence, in which several notes and a transaction script can interact with an account.
Inputs
A Transaction requires several inputs:
- Account: A
Transactionis always executed against a single account. The executor must have complete knowledge of the account's state. - Notes: A
Transactioncan consume and output up to1024notes. The executor must have complete knowledge of the note data, including note inputs, before consumption. For private notes, the data cannot be fetched from the blockchain and must be received through an off-chain channel. - Blockchain state: The current reference block and information about the notes database used to authenticate notes to be consumed must be retrieved from the Miden operator before execution. Usually, notes to be consumed in a
Transactionmust have been created before the reference block. - Transaction script (optional): The
Transactionscript is code defined by the executor. And like note scripts, they can invoke account methods, e.g., sign a transaction. There is no limit to the amount of code aTransactionscript can hold. - Transaction arguments (optional): For every note, the executor can inject transaction arguments that are present at runtime. If the note script — and therefore the note creator — allows, the note script can read those arguments to allow dynamic execution. See below for an example.
- Foreign account data (optional): Any foreign account data accessed during a
Transaction, whether private or public, must be available beforehand. There is no need to know the full account storage, but the data necessary for theTransaction, e.g., the key/value pair that is read and the corresponding storage root.
Flow
- Prologue Executes at the beginning of a transaction. It validates on-chain commitments against the provided data. This is to ensure that the transaction executes against a valid on-chain recorded state of the account and to be consumed notes. Notes to be consumed must be registered on-chain — except for erasable notes which can be consumed without block inclusion.
- Note processing Notes are executed sequentially against the account, following a sequence defined by the executor. To execute a note means processing the note script that calls methods exposed on the account interface. Notes must be consumed fully, which means that all assets must be transferred into the account or into other created notes. Note scripts can invoke the account interface during execution. They can push assets into the account's vault, create new notes, set a transaction expiration, and read from or write to the account’s storage. Any method they call must be explicitly exposed by the account interface. Note scripts can also invoke methods of foreign accounts to read their state.
- Transaction script processing
Transactionscripts are an optional piece of code defined by the executor which interacts with account methods after all notes have been executed. For example,Transactionscripts can be used to sign theTransaction(e.g., sign the transaction by incrementing the nonce of the account, without which, the transaction would fail), to mint tokens from a faucet, create notes, or modify account storage.Transactionscripts can also invoke methods of foreign accounts to read their state. - Epilogue
Completes the execution, resulting in an updated account state and a generated zero-knowledge proof. The validity of the resulting state change is checked. The account's
Noncemust have been incremented, which is how the entire transaction is authenticated. Also, the net sum of all involved assets must be0(if the account is not a faucet).
The proof together with the corresponding data needed for verification and updates of the global state can then be submitted and processed by the network.
Examples
To illustrate the Transaction protocol, we provide two examples for a basic Transaction. We will use references to the existing Miden Transaction kernel — the reference implementation of the protocol — and to the methods in Miden Assembly.
Creating a P2ID note
Let's assume account A wants to create a P2ID note. P2ID notes are pay-to-ID notes that can only be consumed by a specified target account ID. Note creators can provide the target account ID using the note inputs.
In this example, account A uses the basic wallet and the authentication component provided by miden-lib. The basic wallet component defines the methods wallets::basic::create_note and wallets::basic::move_asset_to_note to create notes with assets, and wallets::basic::receive_asset to receive assets. The authentication component exposes auth::basic::auth_tx_rpo_falcon512 which allows for signing a transaction. Some account methods like account::get_id are always exposed.
The executor inputs to the Miden VM a Transaction script in which he places on the stack the data (tag, aux, note_type, execution_hint, RECIPIENT) of the note(s) that he wants to create using wallets::basic::create_note during the said Transaction. The NoteRecipient is a value that describes under which condition a note can be consumed and is built using a serial_number, the note_script (in this case P2ID script) and the note_inputs. The Miden VM will execute the Transaction script and create the note(s). After having been created, the executor can use wallets::basic::move_asset_to_note to move assets from the account's vault to the notes vault.
After finalizing the Transaction the updated state and created note(s) can now be submitted to the Miden operator to be recorded on-chain.
Consuming a P2ID note
Let's now assume that account A wants to consume a P2ID note to receive the assets contained in that note.
To start the transaction process, the executor fetches and prepares all the input data to the Transaction. First, it retrieves blockchain data, like global inputs and block data of the most recent block. This information is needed to authenticate the native account's state and that the P2ID note exists on-chain. Then it loads the full account and note data, to start the Transaction execution.
In the transaction's prologue the data is being authenticated by re-hashing the provided values and comparing them to the blockchain's data (this is how private data can be used and verified during the execution of transaction without actually revealing it to the network).
Then the P2ID note script is being executed. The script starts by reading the note inputs note::get_inputs — in our case the account ID of the intended target account. It checks if the provided target account ID equals the account ID of the executing account. This is the first time the note invokes a method exposed by the Transaction kernel, account::get_id.
If the check passes, the note script pushes the assets it holds into the account's vault. For every asset the note contains, the script calls the wallets::basic::receive_asset method exposed by the account's wallet component. The wallets::basic::receive_asset procedure calls account::add_asset, which cannot be called from the note itself. This allows accounts to control what functionality to expose, e.g. whether the account supports receiving assets or not, and the note cannot bypass that.
After the assets are stored in the account's vault, the transaction script is being executed. The script calls auth::basic::auth_tx_rpo_falcon512 which is explicitly exposed in the account interface. The method is used to verify a provided signature against a public key stored in the account's storage and a commitment to this specific transaction. If the signature can be verified, the method increments the nonce.
The Epilogue finalizes the transaction by computing the final account hash, asserting the nonce increment and checking that no assets were created or destroyed in the transaction — that means the net sum of all assets must stay the same.
Transaction types
There are two types of Transactions in Miden: local transactions and network transactions [not yet implemented].
Local transaction
Users transition their account's state locally using the Miden VM and generate a Transaction proof that can be verified by the network, which we call client-side proving. The network then only has to verify the proof and to change the global parts of the state to apply the state transition.
They are useful, because:
- They enable privacy as neither the account state nor account code are needed to verify the zero-knowledge proof. Public inputs are only commitments and block information that are stored on-chain.
- They are cheaper (i.e., lower in fees) as the execution of the state transition and the generation of the zero-knowledge proof are already made by the users. Hence privacy is the cheaper option on Miden.
- They allow arbitrarily complex computation to be done. The proof size doesn't grow linearly with the complexity of the computation. Hence there is no gas limit for client-side proving.
Client-side proving or local transactions on low-power devices can be slow, but Miden offers a pragmatic alternative: delegated proving. Instead of waiting for complex computations to finish on your device, you can hand off proof generation to a service, ensuring a consistent 1-2 second proving time, even on mobile.
Network transaction
The Miden operator executes the Transaction and generates the proof. Miden uses network Transactions for smart contracts with public shared state. This type of Transaction is quite similar to the ones in traditional blockchains (e.g., Ethereum).
They are useful, because:
- For public shared state of smart contracts. Network
Transactions allow orchestrated state changes of public smart contracts without race conditions. - Smart contracts should be able to be executed autonomously, ensuring liveness. Local
Transactions require a user to execute and prove, but in some cases a smart contract should be able to execute when certain conditions are met. - Clients may not have sufficient resources to generate zero-knowledge proofs.
The ability to facilitate both, local and network Transactions, is one of the differentiating factors of Miden compared to other blockchains. Local Transaction execution and proving can happen in parallel as for most Transactions there is no need for public state changes. This increases the network's throughput tremendously and provides privacy. Network Transactions on the other hand enable autonomous smart contracts and public shared state.
tip
-
Usually, notes that are consumed in a
Transactionmust be recorded on-chain in order for theTransactionto succeed. However, Miden supports erasable notes which are notes that can be consumed in aTransactionbefore being registered on-chain. For example, one can build a sub-second order book by allowing its traders to build faster transactions that depend on each other and are being validated or erased in batches. -
There is no nullifier check during a
Transaction. Nullifiers are checked by the Miden operator duringTransactionverification. So at the local level, there is "double spending." If a note was already spent, i.e. there exists a nullifier for that note, the block producer would never include theTransactionas it would make the block invalid. -
One of the main reasons for separating execution and proving steps is to allow stateless provers; i.e., the executed
Transactionhas all the data it needs to re-execute and prove aTransactionwithout database access. This supports easier proof-generation distribution. -
Not all
Transactions require notes. For example, the owner of a faucet can mint new tokens using only aTransactionscript, without interacting with external notes. -
In Miden executors can choose arbitrary reference blocks to execute against their state. Hence it is possible to set
Transactionexpiration heights and in doing so, to define a block height until aTransactionshould be included into a block. If theTransactionis expired, the resulting account state change is not valid and theTransactioncannot be verified anymore. -
Note and
Transactionscripts can read the state of foreign accounts during execution. This is called foreign procedure invocation. For example, the price of an asset for the Swap script might depend on a certain value stored in the oracle account. -
An example of the right usage of
Transactionarguments is the consumption of a Swap note. Those notes allow asset exchange based on predefined conditions. Example:- The note's consumption condition is defined as "anyone can consume this note to take
Xunits of asset A if they simultaneously create a note sending Y units of asset B back to the creator." If an executor wants to buy only a fraction(X-m)of asset A, they provide this amount via transaction arguments. The executor would provide the valuem. The note script then enforces the correct transfer:- A new note is created returning
Y-((m*Y)/X)of asset B to the sender. - A second note is created, holding the remaining
(X-m)of asset A for future consumption.
- A new note is created returning
- The note's consumption condition is defined as "anyone can consume this note to take
-
When executing a
Transactionthe max number of VM cycles is .
State
The State describes the current condition of all accounts, notes, nullifiers and their statuses. Reflecting the “current reality” of the protocol at any given time.
What is the purpose of the Miden state model?
By employing a concurrent State model with local execution and proving, Miden achieves three primary properties: preserving privacy, supporting parallel transactions, and reducing state-bloat by minimizing on-chain data storage.
Miden’s State model focuses on:
-
Concurrency: Multiple transactions can be processed concurrently by distinct actors using local transaction execution which improves throughput and efficiency.
-
Flexible data storage: Users can store data privately on their own devices or within the network. This approach reduces reliance on the network for data availability, helps maintain user sovereignty, and minimizes unnecessary on-chain storage.
-
Privacy: By using notes and nullifiers, Miden ensures that value transfers remain confidential. Zero-knowledge proofs allow users to prove correctness without revealing sensitive information.
State model components
The Miden node maintains three databases to describe State:
- Accounts
- Notes
- Nullifiers

Account database
The accounts database has two main purposes:
- Track state commitments of all accounts
- Store account data for public accounts
This is done using an authenticated data structure, a sparse Merkle tree.
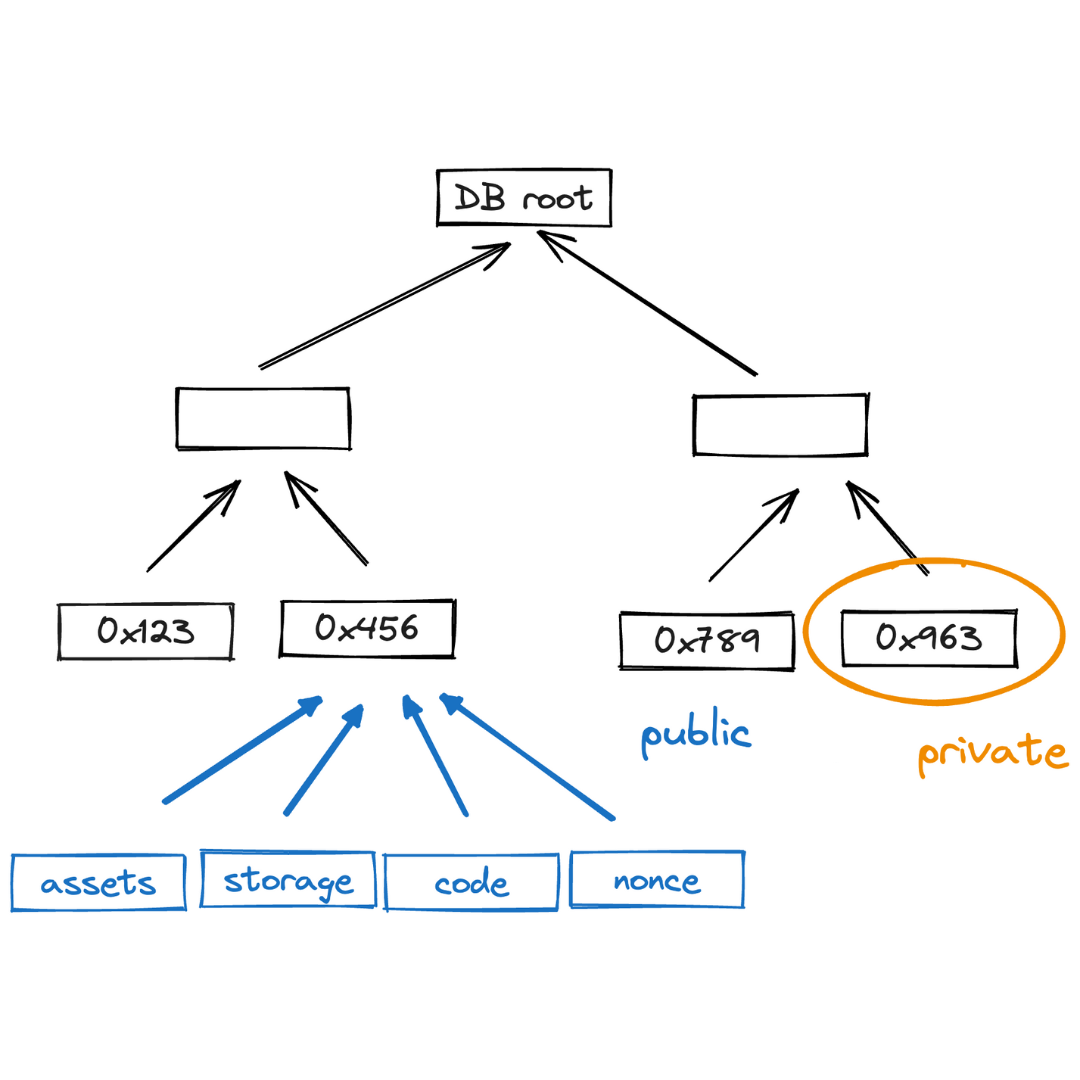
As described in the accounts section, there are two types of accounts:
- Public accounts: where all account data is stored on-chain.
- Private accounts: where only the commitments to the account is stored on-chain.
Private accounts significantly reduce storage overhead. A private account contributes only 40 bytes to the global State (15 bytes for the account ID + 32 bytes for the account commitment + 4 bytes for the block number). For example, 1 billion private accounts take up only 47.47 GB of State.
The storage contribution of a public account depends on the amount of data it stores.
warning
In Miden, when the user is the custodian of their account State (in the case of a private account), losing this State amounts to losing their funds, similar to losing a private key.
Note database
As described in the notes section, there are two types of notes:
- Public notes: where the entire note content is stored on-chain.
- Private notes: where only the note’s commitment is stored on-chain.
Private notes greatly reduce storage requirements and thus result in lower fees. At high throughput (e.g., 1K TPS), the note database could grow by about 1TB/year. However, only unconsumed public notes and enough information to construct membership proofs must be stored explicitly. Private notes, as well as consumed public notes, can be discarded. This solves the issue of infinitely growing note databases.
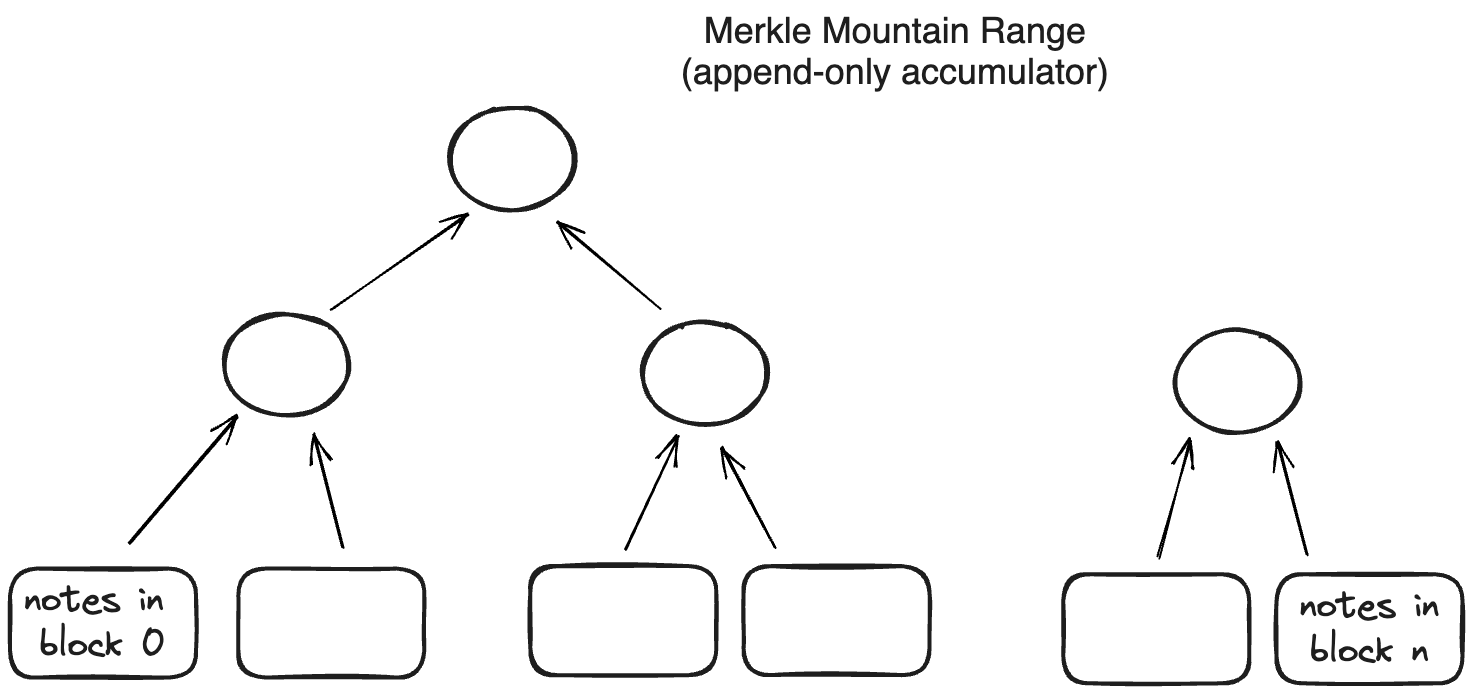
Notes are recorded in an append-only accumulator, a Merkle Mountain Range.
Using a Merkle Mountain Range (append-only accumulator) is important for two reasons:
- Membership witnesses (that a note exists in the database) against such an accumulator needs to be updated very infrequently.
- Old membership witnesses can be extended to a new accumulator value, but this extension does not need to be done by the original witness holder.
Both of these properties are needed for supporting local transactions using client-side proofs and privacy. In an append-only data structure, witness data does not become stale when the data structure is updated. That means users can generate valid proofs even if they don’t have the latest State of this database; so there is no need to query the operator on a constantly changing State.
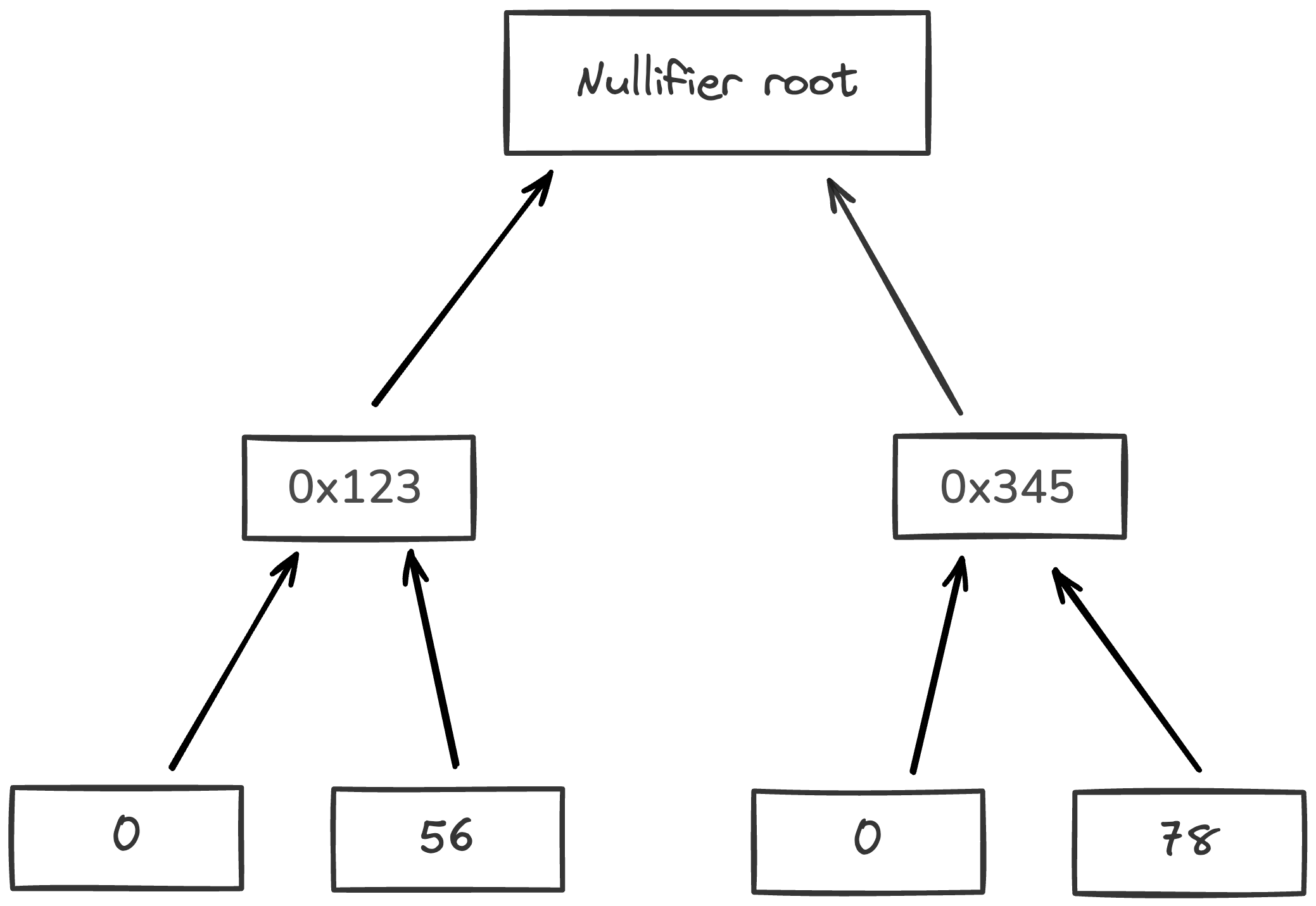
Nullifier database
Each note has an associated nullifier which enables the tracking of whether it's associated note has been consumed or not, preventing double-spending.
To prove that a note has not been consumed, the operator must provide a Merkle path to the corresponding node and show that the node’s value is 0. Since nullifiers are 32 bytes each, the sparse Merkle tree height must be sufficient to represent all possible nullifiers. Operators must maintain the entire nullifier set to compute the new tree root after inserting new nullifiers. For each nullifier we also record the block in which it was created. This way "unconsumed" nullifiers have block 0, but all consumed nullifiers have a non-zero block.
note
Nullifiers in Miden break linkability between privately stored notes and their consumption details. To know the note’s nullifier, one must know the note’s data.
Additional information
Public shared state
In most blockchains, most smart contracts and decentralized applications (e.g., AAVE, Uniswap) need public shared State. Public shared State is also available on Miden and can be represented as in the following example:
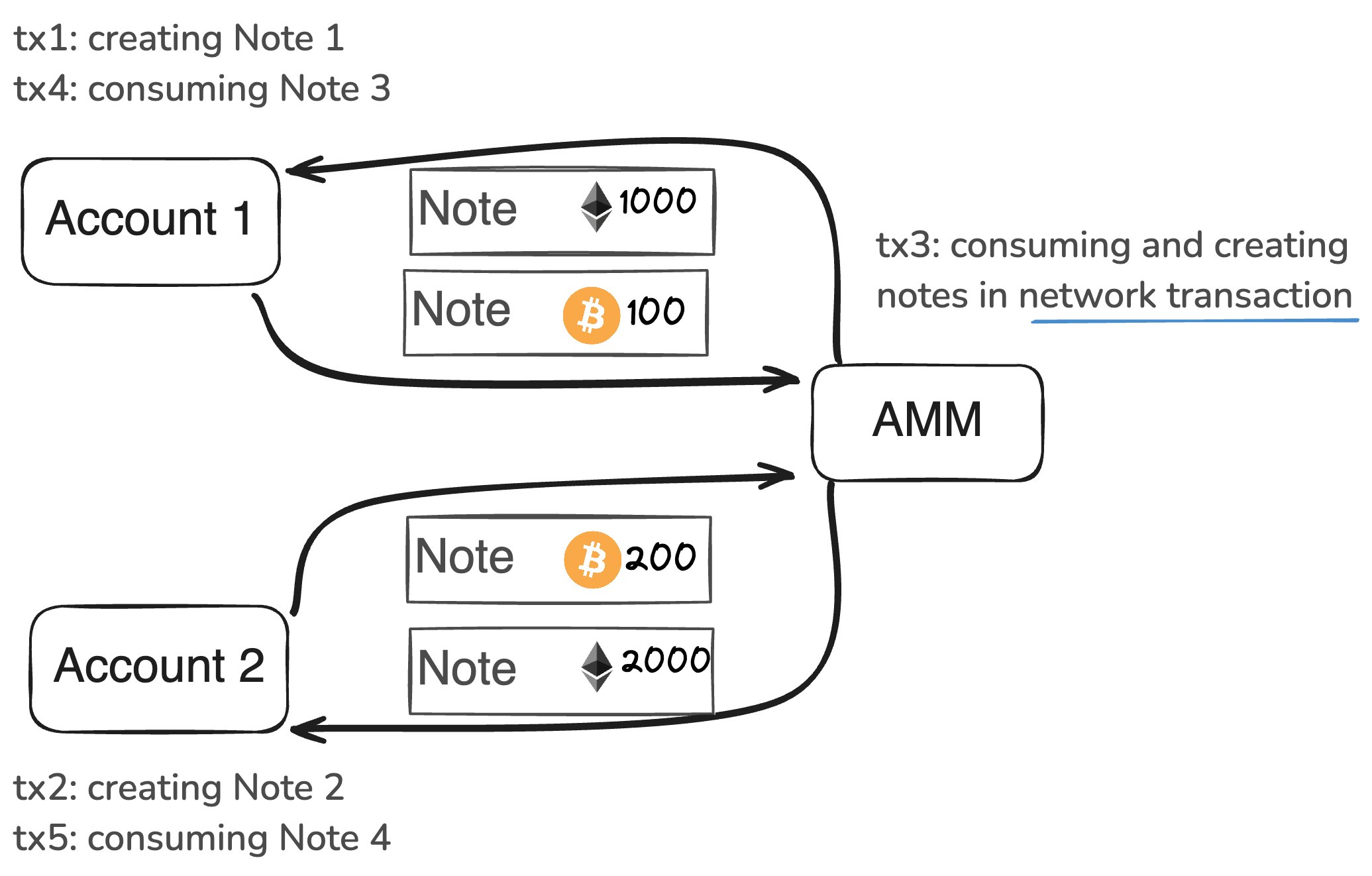
In this diagram, multiple participants interact with a common, publicly accessible State. The figure illustrates how notes are created and consumed:
-
Independent Transactions Creating Notes (tx1 & tx2): Two separate users (Acc1 and Acc2) execute transactions independently:
- tx1 produces note 1
- tx2 produces note 2
These transactions occur in parallel and do not rely on each other, allowing concurrent processing without contention.
-
Sequencing and Consuming Notes (tx3):
The Miden node executes tx3 against the shared account, consuming notes 1 & 2 and producing notes 3 & 4. tx3 is a network transaction executed by the Miden operator. It merges independent contributions into a unifiedStateupdate. -
Further Independent Transactions (tx4 & tx5):
After the sharedStateis updated:- tx4 consumes note 4
- tx5 consumes note 5
Both users can now interact with notes generated by the public account, continuing the cycle of
Stateevolution.
State bloat minimization
Miden nodes do not need to know the entire State to verify or produce new blocks. Rather than storing the full State data with the nodes, users keep their data locally, and the rollup stores only commitments to that data. While some contracts must remain publicly visible, this approach minimizes State bloat. Furthermore the Miden rollup can discard non-required data after certain conditions have been met.
This ensures that the account and note databases remain manageable, even under sustained high usage.
Blockchain
The Miden blockchain protocol describes how the state progresses through Blocks, which are containers that aggregate account state changes and their proofs, together with created and consumed notes. Blocks represent the delta of the global state between two time periods, and each is accompanied by a corresponding proof that attests to the correctness of all state transitions it contains. The current global state can be derived by applying all the Blocks to the genesis state.
Miden's blockchain protocol aims for the following:
- Proven transactions: All included transactions have already been proven and verified when they reach the block.
- Fast genesis syncing: New nodes can efficiently sync to the tip of the chain.
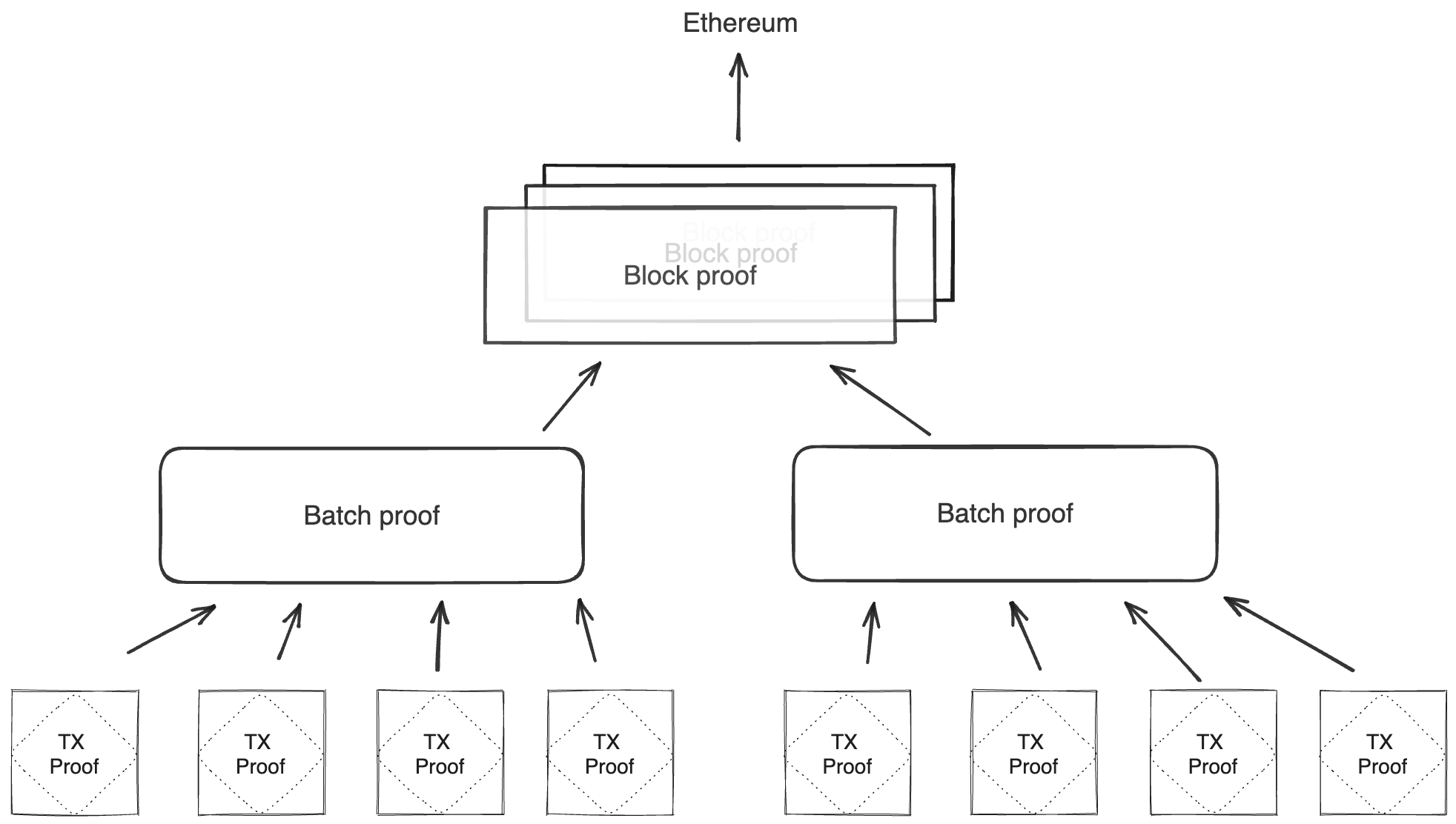
Batch production
To reduce the required space on the blockchain, transaction proofs are not directly put into blocks. First, they are batched together by verifying them in the batch producer. The purpose of the batch producer is to generate a single proof that some number of proven transactions have been verified. This involves recursively verifying individual transaction proofs inside the Miden VM. As with any program that runs in the Miden VM, there is a proof of correct execution running the Miden verifier to verify transaction proofs. This results into a single batch proof.
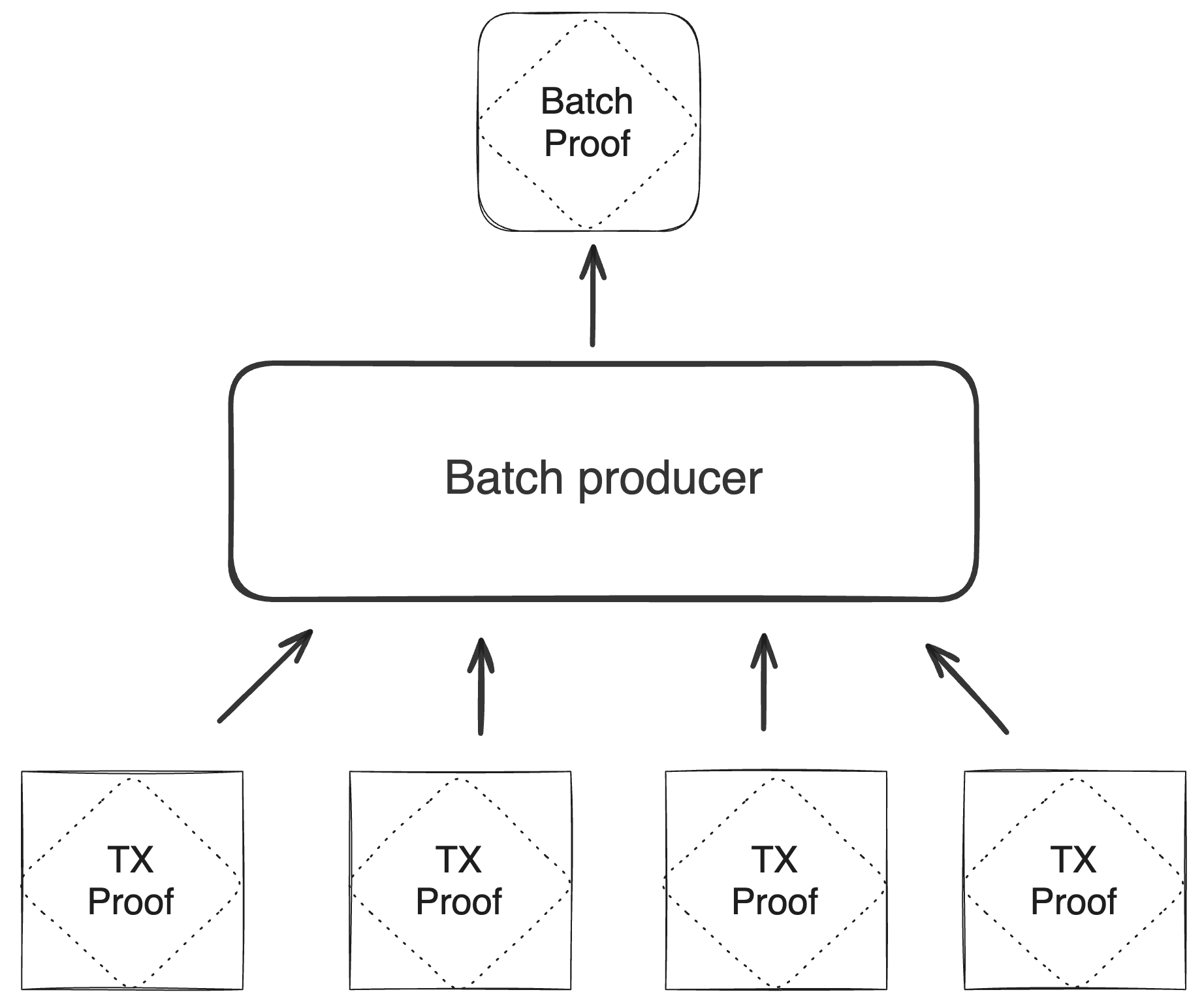
The batch producer aggregates transactions sequentially by verifying that their proofs and state transitions are correct. More specifically, the batch producer ensures:
- Ordering of transactions: If several transactions within the same batch affect a single account, the correct ordering must be enforced. For example, if
Tx1andTx2both describe state changes of accountA, then the batch kernel must verify them in the order:A -> Tx1 -> A' -> Tx2 -> A''. - Uniqueness of notes in a single batch: The batch producer must ensure the uniqueness of all notes across transactions in the batch. This will prevent the situation where duplicate notes, which would share identical nullifiers, are created. Only one such duplicate note could later be consumed, as the nullifier will be marked as spent after the first consumption. It also checks for double spends in the set of consumed notes, even though the real double spent check only happens at the block production level.
- Expiration windows: It is possible to set an expiration window for transactions, which in turn sets an expiration window for the entire batch. For instance, if transaction
Tx1expires at block8and transactionTx2expires at block5, then the batch expiration will be set to the minimum of all transaction expirations, which is5. - Note erasure of erasable notes: Erasable notes don't exist in the Notes DB. They are unauthenticated. Accounts can still consume unauthenticated notes to consume those notes faster, they don't have to wait for notes being included into a block. If creation and consumption of an erasable note happens in the same batch, the batch producer erases this note.
Block production
To create a Block, multiple batches and their respective proofs are aggregated. Block production is not parallelizable and must be performed by the Miden operator. In the future, several Miden operators may compete for Block production. The schema used for Block production is similar to that in batch production—recursive verification. Multiple batch proofs are aggregated into a single Block proof.
The block producer ensures:
- Account DB integrity: The Block
N+1Account DB commitment must be authenticated against all previous and resulting account commitments across transactions, ensuring valid state transitions and preventing execution on stale states. - Nullifier DB integrity: Nullifiers of newly created notes are added to the Nullifier DB. The Block
N+1Nullifier DB commitment must be authenticated against all new nullifiers to guarantee completeness. - Block hash references: Check that all block hashes references by batches are in the chain.
- Double-spend prevention: Each consumed note’s nullifier is checked against prior consumption. The Block
NNullifier DB commitment is authenticated against all provided nullifiers for consumed notes, ensuring no nullifier is reused. - Global note uniqueness: All created and consumed notes must be unique across batches.
- Batch expiration: The block height of the created block must be smaller or equal than the lowest batch expiration.
- Block time increase: The block timestamp must increase monotonically from the previous block.
- Note erasure of erasable notes: If an erasable note is created and consumed in different batches, it is erased now. If, however, an erasable note is consumed but not created within the block, the batch it contains is rejected. The Miden operator's mempool should preemptively filter such transactions.
In final Block contains:
- The commitments to the current global state.
- The newly created nullifiers.
- The commitments to newly created notes.
- The new state commitments for affected private accounts.
- The full states for all affected public accounts and newly created notes.
The Block proof attests to the correct state transition from the previous Block commitment to the next, and therefore to the change in Miden's global state.
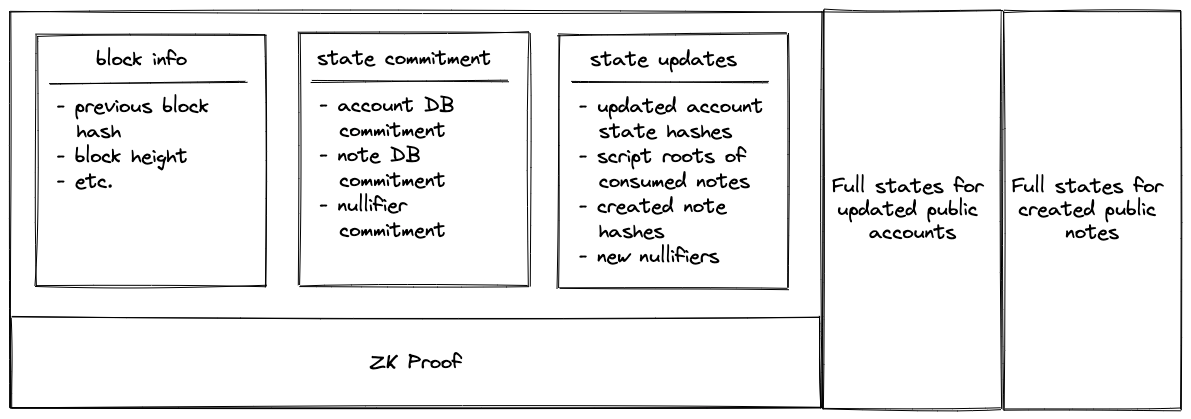
tip
Block Contents:
- State updates: Contains only the hashes of updated elements. For example, for each updated account, a tuple is recorded as
([account id], [new account hash]). - ZK Proof: This proof attests that, given a state commitment from the previous
Block, a set of valid batches was executed that resulted in the new state commitment. - The
Blockalso includes the full account and note data for public accounts and notes. For example, if account123is a public account that has been updated, you would see a record in the state updates section as(123, 0x456..), and the full new state of this account (which should hash to0x456..) would be included in a separate section.
Verifying blocks
To verify that a Block corresponds to a valid global state transition, the following steps must be performed:
- Compute the hashes of public accounts and note states.
- Ensure that these hashes match the records in the state updates section.
- Verify the included
Blockproof using the following public inputs and output:- Input: Previous
Blockcommitment. - Input: Set of batch commitments.
- Output: Current
Blockcommitment.
- Input: Previous
These steps can be performed by any verifier (e.g., a contract on Ethereum, Polygon AggLayer, or a decentralized network of Miden nodes).
Syncing from genesis
Nodes can sync efficiently from genesis to the tip of the chain through a multi-step process:
- Download historical
Blocks from genesis to the present. - Verify zero-knowledge proofs for all
Blocks. - Retrieve current state data (accounts, notes, and nullifiers).
- Validate that the downloaded state matches the latest
Block's state commitment.
This approach enables fast blockchain syncing by verifying Block proofs rather than re-executing individual transactions, resulting in exponentially faster performance. Consequently, state sync is dominated by the time needed to download the data.
Consensus and decentralization
Miden will start as a centralized L2 on the Ethereum network. Over time, Miden will decentralize, but this part of the protocol, especially consensus is not yet set.
Introduction
Basic tutorials and examples of how to build applications on Miden.
The goal is to make getting up to speed with building on Miden as quick and simple as possible.
All of the following tutorials are accompanied by code examples in Rust and TypeScript, which can be found in the Miden Tutorials repository.
Miden Node Setup Tutorial
To run the Miden tutorial examples, you will need to set up a test enviorment and connect to a Miden node.
There are two ways to connect to a Miden node:
- Run the Miden node locally
- Connect to the Miden testnet
Prerequisites
To run miden-node locally, you need to:
- Install the
miden-nodecrate. - Provide a
genesis.tomlfile. - Provide a
miden-node.tomlfile.
Example genesis.toml and miden-node.toml files can be found in the miden-tutorials repository:
- The
genesis.tomlfile defines the start timestamp for themiden-nodetestnet and allows you to pre-deploy accounts and funding faucets. - The
miden-node.tomlfile configures the RPC endpoint and other settings for themiden-node.
Running the Miden node locally
Step 1: Clone the miden-tutorials repository
In a terminal window, clone the miden-tutorials repository and navigate to the root of the repository using this command:
git clone git@github.com:0xPolygonMiden/miden-tutorials.git
cd miden-tutorials
Step 2: Install the Miden node
Next, install the miden-node crate using this command:
cargo install miden-node --locked
Step 3: Initializing the node
To start the node, we first need to generate the genesis file. To do so, navigate to the /node directory and create the genesis file using this command:
cd node
miden-node make-genesis \
--inputs-path config/genesis.toml \
--output-path storage/genesis.dat
Expected output:
Genesis input file: config/genesis.toml has successfully been loaded.
Creating fungible faucet account...
Account "faucet" has successfully been saved to: storage/accounts/faucet.mac
Miden node genesis successful: storage/genesis.dat has been created
Step 4: Starting the node
Now, to start the node, navigate to the storage directory and run this command:
cd storage
miden-node start \
--config node/config/miden-node.toml \
node
Expected output:
2025-01-17T12:14:55.432445Z INFO try_build_batches: miden-block-producer: /Users/username/.cargo/registry/src/index.crates.io-6f17d22bba15001f/miden-node-block-producer-0.6.0/src/txqueue/mod.rs:85: close, time.busy: 8.88µs, time.idle: 103µs
2025-01-17T12:14:57.433162Z INFO try_build_batches: miden-block-producer: /Users/username/.cargo/registry/src/index.crates.io-6f17d22bba15001f/miden-node-block-producer-0.6.0/src/txqueue/mod.rs:85: new
2025-01-17T12:14:57.433256Z INFO try_build_batches: miden-block-producer: /Users/username/.cargo/registry/src/index.crates.io-6f17d22bba15001f/miden-node-block-producer-0.6.0/src/txqueue/mod.rs:85: close, time.busy: 6.46µs, time.idle: 94.0µs
Congratulations, you now have a Miden node running locally. Now we can start creating a testing environment for building applications on Miden!
The endpoint of the Miden node running locally is:
http://localhost:57291
Reseting the node
If you need to reset the local state of the node and the rust-client, navigate to the root of the miden-tutorials repository and run this command:
rm -rf rust-client/store.sqlite3
rm -rf node/storage/accounts
rm -rf node/storage/blocks
Connecting to the Miden testnet
To run the tutorial examples using the Miden testnet, use this endpoint:
https://rpc.testnet.miden.io:443
Rust Client
Rust library, which can be used to programmatically interact with the Miden rollup.
The Miden Rust client can be used for a variety of things, including:
- Deploying, testing, and creating transactions to interact with accounts and notes on Miden.
- Storing the state of accounts and notes locally.
- Generating and submitting proofs of transactions.
This section of the docs is an overview of the different things one can achieve using the Rust client, and how to implement them.
Keep in mind that both the Rust client and the documentation are works-in-progress!
Creating Accounts and Faucets
Using the Miden client in Rust to create accounts and deploy faucets
Overview
In this tutorial, we will create a Miden account for Alice and deploy a fungible faucet. In the next section, we will mint tokens from the faucet to fund her account and transfer tokens from Alice's account to other Miden accounts.
What we'll cover
- Understanding the differences between public and private accounts & notes
- Instantiating the Miden client
- Creating new accounts (public or private)
- Deploying a faucet to fund an account
Prerequisites
Before you begin, ensure that a Miden node is running locally in a separate terminal window. To get the Miden node running locally, you can follow the instructions on the Miden Node Setup page.
Public vs. private accounts & notes
Before diving into coding, let's clarify the concepts of public and private accounts & notes on Miden:
- Public accounts: The account's data and code are stored on-chain and are openly visible, including its assets.
- Private accounts: The account's state and logic are off-chain, only known to its owner.
- Public notes: The note's state is visible to anyone - perfect for scenarios where transparency is desired.
- Private notes: The note's state is stored off-chain, you will need to share the note data with the relevant parties (via email or Telegram) for them to be able to consume the note.
Note: The term "account" can be used interchangeably with the term "smart contract" since account abstraction on Miden is handled natively.
It is useful to think of notes on Miden as "cryptographic cashier's checks" that allow users to send tokens. If the note is private, the note transfer is only known to the sender and receiver.
Step 1: Initialize your repository
Create a new Rust repository for your Miden project and navigate to it with the following command:
cargo new miden-rust-client
cd miden-rust-client
Add the following dependencies to your Cargo.toml file:
[dependencies]
miden-client = { version = "0.7", features = ["testing", "concurrent", "tonic", "sqlite"] }
miden-lib = { version = "0.7", default-features = false }
miden-objects = { version = "0.7.2", default-features = false }
miden-crypto = { version = "0.13.2", features = ["executable"] }
rand = { version = "0.8" }
serde = { version = "1", features = ["derive"] }
serde_json = { version = "1.0", features = ["raw_value"] }
tokio = { version = "1.40", features = ["rt-multi-thread", "net", "macros"] }
rand_chacha = "0.3.1"
Step 2: Initialize the client
Before interacting with the Miden network, we must instantiate the client. In this step, we specify several parameters:
- RPC endpoint - The URL of the Miden node you will connect to.
- Client RNG - The random number generator used by the client, ensuring that the serial number of newly created notes are unique.
- SQLite Store – An SQL database used by the client to store account and note data.
- Authenticator - The component responsible for generating transaction signatures.
Copy and paste the following code into your src/main.rs file.
use miden_client::{
account::{
component::{BasicFungibleFaucet, BasicWallet, RpoFalcon512},
AccountBuilder, AccountId, AccountStorageMode, AccountType,
},
asset::{FungibleAsset, TokenSymbol},
auth::AuthSecretKey,
crypto::{RpoRandomCoin, SecretKey},
note::NoteType,
rpc::{Endpoint, TonicRpcClient},
store::{sqlite_store::SqliteStore, StoreAuthenticator},
transaction::{OutputNote, PaymentTransactionData, TransactionRequestBuilder},
Client, ClientError, Felt,
};
use miden_lib::note::create_p2id_note;
use miden_objects::account::AccountIdVersion;
use rand::Rng;
use std::sync::Arc;
use tokio::time::Duration;
pub async fn initialize_client() -> Result<Client<RpoRandomCoin>, ClientError> {
// RPC endpoint and timeout
let endpoint = Endpoint::new("http".to_string(), "localhost".to_string(), Some(57291));
let timeout_ms = 10_000;
// Build RPC client
let rpc_api = Box::new(TonicRpcClient::new(endpoint, timeout_ms));
// Seed RNG
let mut seed_rng = rand::thread_rng();
let coin_seed: [u64; 4] = seed_rng.gen();
// Create random coin instance
let rng = RpoRandomCoin::new(coin_seed.map(Felt::new));
// SQLite path
let store_path = "store.sqlite3";
// Initialize SQLite store
let store = SqliteStore::new(store_path.into())
.await
.map_err(ClientError::StoreError)?;
let arc_store = Arc::new(store);
// Create authenticator referencing the same store and RNG
let authenticator = StoreAuthenticator::new_with_rng(arc_store.clone(), rng);
// Instantiate the client. Toggle `in_debug_mode` as needed
let client = Client::new(rpc_api, rng, arc_store, Arc::new(authenticator), true);
Ok(client)
}
#[tokio::main]
async fn main() -> Result<(), ClientError> {
let mut client = initialize_client().await?;
println!("Client initialized successfully.");
let sync_summary = client.sync_state().await.unwrap();
let block_number = sync_summary.block_num;
println!("Latest block number: {}", block_number);
Ok(())
}
When running the code above, there will be some unused imports, however, we will use these imports later on in the tutorial.
In this step, we will initialize a Miden client capable of syncing with the blockchain (in this case, our local node). Run the following command to execute src/main.rs:
cargo run --release
After the program executes, you should see the latest block number printed to the terminal, for example:
Latest block number: 3855
Step 3: Creating a wallet
Now that we've initialized the client, we can create a wallet for Alice.
To create a wallet for Alice using the Miden client, we define the account type as mutable or immutable and specify whether it is public or private. A mutable wallet means you can change the account code after deployment. A wallet on Miden is simply an account with standardized code.
In the example below we create a mutable public account for Alice.
Add this snippet to the end of your file in the main() function:
Step 4: Deploying a fungible faucet
To provide Alice with testnet assets, we must first deploy a faucet. A faucet account on Miden mints fungible tokens.
We'll create a public faucet with a token symbol, decimals, and a max supply. We will use this faucet to mint tokens to Alice's account in the next section.
Add this snippet to the end of your file in the main() function:
When tokens are minted from this faucet, each token batch is represented as a "note" (UTXO). You can think of a Miden Note as a cryptographic cashier's check that has certain spend conditions attached to it.
Summary
Your updated main() function in src/main.rs should look like this:
#[tokio::main]
async fn main() -> Result<(), ClientError> {
let mut client = initialize_client().await?;
println!("Client initialized successfully.");
let sync_summary = client.sync_state().await.unwrap();
let block_number = sync_summary.block_num;
println!("Latest block number: {}", block_number);
//------------------------------------------------------------
// STEP 1: Create a basic wallet for Alice
//------------------------------------------------------------
println!("\n[STEP 1] Creating a new account for Alice");
// Account seed
let mut init_seed = [0u8; 32];
client.rng().fill_bytes(&mut init_seed);
// Generate key pair
let key_pair = SecretKey::with_rng(client.rng());
// Anchor block
let anchor_block = client.get_latest_epoch_block().await.unwrap();
// Build the account
let builder = AccountBuilder::new(init_seed)
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::RegularAccountUpdatableCode)
.storage_mode(AccountStorageMode::Public)
.with_component(RpoFalcon512::new(key_pair.public_key()))
.with_component(BasicWallet);
let (alice_account, seed) = builder.build().unwrap();
// Add the account to the client
client
.add_account(
&alice_account,
Some(seed),
&AuthSecretKey::RpoFalcon512(key_pair),
false,
)
.await?;
println!("Alice's account ID: {:?}", alice_account.id().to_hex());
//------------------------------------------------------------
// STEP 2: Deploy a fungible faucet
//------------------------------------------------------------
println!("\n[STEP 2] Deploying a new fungible faucet.");
// Faucet seed
let mut init_seed = [0u8; 32];
client.rng().fill_bytes(&mut init_seed);
// Faucet parameters
let symbol = TokenSymbol::new("MID").unwrap();
let decimals = 8;
let max_supply = Felt::new(1_000_000);
// Generate key pair
let key_pair = SecretKey::with_rng(client.rng());
// Build the account
let builder = AccountBuilder::new(init_seed)
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::FungibleFaucet)
.storage_mode(AccountStorageMode::Public)
.with_component(RpoFalcon512::new(key_pair.public_key()))
.with_component(BasicFungibleFaucet::new(symbol, decimals, max_supply).unwrap());
let (faucet_account, seed) = builder.build().unwrap();
// Add the faucet to the client
client
.add_account(
&faucet_account,
Some(seed),
&AuthSecretKey::RpoFalcon512(key_pair),
false,
)
.await?;
println!("Faucet account ID: {:?}", faucet_account.id().to_hex());
// Resync to show newly deployed faucet
client.sync_state().await?;
Ok(())
}
Let's run the src/main.rs program again:
cargo run --release
The output will look like this:
[STEP 1] Creating a new account for Alice
Alice's account ID: "0x715abc291819b1100000e7cd88cf3e"
[STEP 2] Deploying a new fungible faucet.
Faucet account ID: "0xab5fb36dd552982000009c440264ce"
In this section we explained how to instantiate the Miden client, create a wallet account, and deploy a faucet.
In the next section we will cover how to mint tokens from the faucet, consume notes, and send tokens to other accounts.
Running the example
To run a full working example navigate to the rust-client directory in the miden-tutorials repository and run this command:
cd rust-client
cargo run --release --bin create_mint_consume_send
Continue learning
Next tutorial: Mint, Consume, and Create Notes
Mint, Consume, and Create Notes
Using the Miden client in Rust to mint, consume, and create notes
Overview
In the previous section, we initialized our repository and covered how to create an account and deploy a faucet. In this section, we will mint tokens from the faucet for Alice, consume the newly created notes, and demonstrate how to send assets to other accounts.
What we'll cover
- Minting tokens from a faucet
- Consuming notes to fund an account
- Sending tokens to other users
Step 1: Minting tokens from the faucet
To mint notes with tokens from the faucet we created, Alice needs to call the faucet with a mint transaction request.
In essence, a transaction request is a structured template that outlines the data required to generate a zero-knowledge proof of a state change of an account. It specifies which input notes (if any) will be consumed, includes an optional transaction script to execute, and enumerates the set of notes expected to be created (if any).
Below is an example of a transaction request minting tokens from the faucet for Alice. This code snippet will create 5 transaction mint transaction requests.
Add this snippet to the end of your file in the main() function that we created in the previous chapter:
Step 2: Identifying consumable notes
Once Alice has minted a note from the faucet, she will eventually want to spend the tokens that she received in the note created by the mint transaction.
Minting a note from a faucet on Miden means a faucet account creates a new note targeted to the requesting account. The requesting account needs to consume this new note to have the assets appear in their account.
To identify consumable notes, the Miden client provides the get_consumable_notes function. Before calling it, ensure that the client state is synced.
Tip: If you know how many notes to expect after a transaction, use an await or loop condition to check how many notes of the type you expect are available for consumption instead of using a set timeout before calling get_consumable_notes. This ensures your application isn't idle for longer than necessary.
Identifying which notes are available:
Step 3: Consuming multiple notes in a single transaction:
Now that we know how to identify notes ready to consume, let's consume the notes created by the faucet in a single transaction. After consuming the notes, Alice's wallet balance will be updated.
The following code snippet identifies consumable notes and consumes them in a single transaction.
Add this snippet to the end of your file in the main() function:
//------------------------------------------------------------
// STEP 4: Alice consumes all her notes
//------------------------------------------------------------
println!("\n[STEP 4] Alice will now consume all of her notes to consolidate them.");
// Consume all minted notes in a single transaction
loop {
// Resync to get the latest data
client.sync_state().await?;
let consumable_notes = client
.get_consumable_notes(Some(alice_account.id()))
.await?;
let list_of_note_ids: Vec<_> = consumable_notes.iter().map(|(note, _)| note.id()).collect();
if list_of_note_ids.len() == 5 {
println!("Found 5 consumable notes for Alice. Consuming them now...");
let transaction_request =
TransactionRequestBuilder::consume_notes(list_of_note_ids).build();
let tx_execution_result = client
.new_transaction(alice_account.id(), transaction_request)
.await?;
client.submit_transaction(tx_execution_result).await?;
println!("All of Alice's notes consumed successfully.");
break;
} else {
println!(
"Currently, Alice has {} consumable notes. Waiting for 5...",
list_of_note_ids.len()
);
tokio::time::sleep(Duration::from_secs(3)).await;
}
}
Step 4: Sending tokens to other accounts
After consuming the notes, Alice has tokens in her wallet. Now, she wants to send tokens to her friends. She has two options: create a separate transaction for each transfer or batch multiple transfers into a single transaction.
The standard asset transfer note on Miden is the P2ID note (Pay to Id). There is also the P2IDR (Pay to Id Reclaimable) variant which allows the creator of the note to reclaim the note after a certain block height.
In our example, Alice will now send 50 tokens to 5 different accounts.
For the sake of the example, the first four P2ID transfers are handled in a single transaction, and the fifth transfer is a standard P2ID transfer.
Output multiple P2ID notes in a single transaction
To output multiple notes in a single transaction we need to create a list of our expected output notes. The expected output notes are the notes that we expect to create in our transaction request.
In the snippet below, we create an empty vector to store five P2ID output notes, loop over five iterations (using 0..=4) to create five unique dummy account IDs, build a P2ID note for each one, and push each note onto the vector. Finally, we build a transaction request using .with_own_output_notes()—passing in all five notes—and submit it to the node.
Add this snippet to the end of your file in the main() function:
//------------------------------------------------------------
// STEP 5: Alice sends 5 notes of 50 tokens to 5 users
//------------------------------------------------------------
println!("\n[STEP 5] Alice sends 5 notes of 50 tokens each to 5 different users.");
// Send 50 tokens to 4 accounts in one transaction
println!("Creating multiple P2ID notes for 4 target accounts in one transaction...");
let mut p2id_notes = vec![];
for _ in 1..=4 {
let init_seed = {
let mut seed = [0u8; 15];
rand::thread_rng().fill(&mut seed);
seed[0] = 99u8;
seed
};
let target_account_id = AccountId::dummy(
init_seed,
AccountIdVersion::Version0,
AccountType::RegularAccountUpdatableCode,
AccountStorageMode::Public,
);
let send_amount = 50;
let fungible_asset = FungibleAsset::new(faucet_account.id(), send_amount).unwrap();
let p2id_note = create_p2id_note(
alice_account.id(),
target_account_id,
vec![fungible_asset.into()],
NoteType::Public,
Felt::new(0),
client.rng(),
)?;
p2id_notes.push(p2id_note);
}
let output_notes: Vec<OutputNote> = p2id_notes.into_iter().map(OutputNote::Full).collect();
let transaction_request = TransactionRequestBuilder::new()
.with_own_output_notes(output_notes)
.unwrap()
.build();
let tx_execution_result = client
.new_transaction(alice_account.id(), transaction_request)
.await?;
client.submit_transaction(tx_execution_result).await?;
println!("Submitted a transaction with 4 P2ID notes.");
Basic P2ID transfer
Now as an example, Alice will send some tokens to an account in a single transaction.
Add this snippet to the end of your file in the main() function:
// Send 50 tokens to 1 more account as a single P2ID transaction
println!("Submitting one more single P2ID transaction...");
let init_seed = {
let mut seed = [0u8; 15];
rand::thread_rng().fill(&mut seed);
seed[0] = 99u8;
seed
};
let target_account_id = AccountId::dummy(
init_seed,
AccountIdVersion::Version0,
AccountType::RegularAccountUpdatableCode,
AccountStorageMode::Public,
);
let send_amount = 50;
let fungible_asset = FungibleAsset::new(faucet_account.id(), send_amount).unwrap();
let payment_transaction = PaymentTransactionData::new(
vec![fungible_asset.into()],
alice_account.id(),
target_account_id,
);
let transaction_request = TransactionRequestBuilder::pay_to_id(
payment_transaction,
None, // recall_height
NoteType::Public, // note type
client.rng(), // rng
)
.unwrap()
.build();
let tx_execution_result = client
.new_transaction(alice_account.id(), transaction_request)
.await?;
client.submit_transaction(tx_execution_result).await?;
Note: In a production environment do not use AccountId::new_dummy(), this is simply for the sake of the tutorial example.
Summary
Your src/main.rs function should now look like this:
use miden_client::{
account::{
component::{BasicFungibleFaucet, BasicWallet, RpoFalcon512},
AccountBuilder, AccountId, AccountStorageMode, AccountType,
},
asset::{FungibleAsset, TokenSymbol},
auth::AuthSecretKey,
crypto::{RpoRandomCoin, SecretKey},
note::NoteType,
rpc::{Endpoint, TonicRpcClient},
store::{sqlite_store::SqliteStore, StoreAuthenticator},
transaction::{OutputNote, PaymentTransactionData, TransactionRequestBuilder},
Client, ClientError, Felt,
};
use miden_lib::note::create_p2id_note;
use miden_objects::account::AccountIdVersion;
use rand::Rng;
use std::sync::Arc;
use tokio::time::Duration;
pub async fn initialize_client() -> Result<Client<RpoRandomCoin>, ClientError> {
// RPC endpoint and timeout
let endpoint = Endpoint::new("http".to_string(), "localhost".to_string(), Some(57291));
let timeout_ms = 10_000;
// Build RPC client
let rpc_api = Box::new(TonicRpcClient::new(endpoint, timeout_ms));
// Seed RNG
let mut seed_rng = rand::thread_rng();
let coin_seed: [u64; 4] = seed_rng.gen();
// Create random coin instance
let rng = RpoRandomCoin::new(coin_seed.map(Felt::new));
// SQLite path
let store_path = "store.sqlite3";
// Initialize SQLite store
let store = SqliteStore::new(store_path.into())
.await
.map_err(ClientError::StoreError)?;
let arc_store = Arc::new(store);
// Create authenticator referencing the same store and RNG
let authenticator = StoreAuthenticator::new_with_rng(arc_store.clone(), rng);
// Instantiate the client. Toggle `in_debug_mode` as needed
let client = Client::new(rpc_api, rng, arc_store, Arc::new(authenticator), true);
Ok(client)
}
#[tokio::main]
async fn main() -> Result<(), ClientError> {
let mut client = initialize_client().await?;
println!("Client initialized successfully.");
let sync_summary = client.sync_state().await.unwrap();
let block_number = sync_summary.block_num;
println!("Latest block number: {}", block_number);
//------------------------------------------------------------
// STEP 1: Create a basic wallet for Alice
//------------------------------------------------------------
println!("\n[STEP 1] Creating a new account for Alice");
// Account seed
let mut init_seed = [0u8; 32];
client.rng().fill_bytes(&mut init_seed);
// Generate key pair
let key_pair = SecretKey::with_rng(client.rng());
// Anchor block
let anchor_block = client.get_latest_epoch_block().await.unwrap();
// Build the account
let builder = AccountBuilder::new(init_seed)
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::RegularAccountUpdatableCode)
.storage_mode(AccountStorageMode::Public)
.with_component(RpoFalcon512::new(key_pair.public_key()))
.with_component(BasicWallet);
let (alice_account, seed) = builder.build().unwrap();
// Add the account to the client
client
.add_account(
&alice_account,
Some(seed),
&AuthSecretKey::RpoFalcon512(key_pair),
false,
)
.await?;
println!("Alice's account ID: {:?}", alice_account.id().to_hex());
//------------------------------------------------------------
// STEP 2: Deploy a fungible faucet
//------------------------------------------------------------
println!("\n[STEP 2] Deploying a new fungible faucet.");
// Faucet seed
let mut init_seed = [0u8; 32];
client.rng().fill_bytes(&mut init_seed);
// Faucet parameters
let symbol = TokenSymbol::new("MID").unwrap();
let decimals = 8;
let max_supply = Felt::new(1_000_000);
// Generate key pair
let key_pair = SecretKey::with_rng(client.rng());
// Build the account
let builder = AccountBuilder::new(init_seed)
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::FungibleFaucet)
.storage_mode(AccountStorageMode::Public)
.with_component(RpoFalcon512::new(key_pair.public_key()))
.with_component(BasicFungibleFaucet::new(symbol, decimals, max_supply).unwrap());
let (faucet_account, seed) = builder.build().unwrap();
// Add the faucet to the client
client
.add_account(
&faucet_account,
Some(seed),
&AuthSecretKey::RpoFalcon512(key_pair),
false,
)
.await?;
println!("Faucet account ID: {:?}", faucet_account.id().to_hex());
// Resync to show newly deployed faucet
client.sync_state().await?;
tokio::time::sleep(Duration::from_secs(2)).await;
//------------------------------------------------------------
// STEP 3: Mint 5 notes of 100 tokens for Alice
//------------------------------------------------------------
println!("\n[STEP 3] Minting 5 notes of 100 tokens each for Alice.");
let amount: u64 = 100;
let fungible_asset = FungibleAsset::new(faucet_account.id(), amount).unwrap();
for i in 1..=5 {
let transaction_request = TransactionRequestBuilder::mint_fungible_asset(
fungible_asset,
alice_account.id(),
NoteType::Public,
client.rng(),
)
.unwrap()
.build();
let tx_execution_result = client
.new_transaction(faucet_account.id(), transaction_request)
.await?;
client.submit_transaction(tx_execution_result).await?;
println!("Minted note #{} of {} tokens for Alice.", i, amount);
}
println!("All 5 notes minted for Alice successfully!");
// Re-sync so minted notes become visible
client.sync_state().await?;
//------------------------------------------------------------
// STEP 4: Alice consumes all her notes
//------------------------------------------------------------
println!("\n[STEP 4] Alice will now consume all of her notes to consolidate them.");
// Consume all minted notes in a single transaction
loop {
// Resync to get the latest data
client.sync_state().await?;
let consumable_notes = client
.get_consumable_notes(Some(alice_account.id()))
.await?;
let list_of_note_ids: Vec<_> = consumable_notes.iter().map(|(note, _)| note.id()).collect();
if list_of_note_ids.len() == 5 {
println!("Found 5 consumable notes for Alice. Consuming them now...");
let transaction_request =
TransactionRequestBuilder::consume_notes(list_of_note_ids).build();
let tx_execution_result = client
.new_transaction(alice_account.id(), transaction_request)
.await?;
client.submit_transaction(tx_execution_result).await?;
println!("All of Alice's notes consumed successfully.");
break;
} else {
println!(
"Currently, Alice has {} consumable notes. Waiting for 5...",
list_of_note_ids.len()
);
tokio::time::sleep(Duration::from_secs(3)).await;
}
}
//------------------------------------------------------------
// STEP 5: Alice sends 5 notes of 50 tokens to 5 users
//------------------------------------------------------------
println!("\n[STEP 5] Alice sends 5 notes of 50 tokens each to 5 different users.");
// Send 50 tokens to 4 accounts in one transaction
println!("Creating multiple P2ID notes for 4 target accounts in one transaction...");
let mut p2id_notes = vec![];
for _ in 1..=4 {
let init_seed = {
let mut seed = [0u8; 15];
rand::thread_rng().fill(&mut seed);
seed[0] = 99u8;
seed
};
let target_account_id = AccountId::dummy(
init_seed,
AccountIdVersion::Version0,
AccountType::RegularAccountUpdatableCode,
AccountStorageMode::Public,
);
let send_amount = 50;
let fungible_asset = FungibleAsset::new(faucet_account.id(), send_amount).unwrap();
let p2id_note = create_p2id_note(
alice_account.id(),
target_account_id,
vec![fungible_asset.into()],
NoteType::Public,
Felt::new(0),
client.rng(),
)?;
p2id_notes.push(p2id_note);
}
let output_notes: Vec<OutputNote> = p2id_notes.into_iter().map(OutputNote::Full).collect();
let transaction_request = TransactionRequestBuilder::new()
.with_own_output_notes(output_notes)
.unwrap()
.build();
let tx_execution_result = client
.new_transaction(alice_account.id(), transaction_request)
.await?;
client.submit_transaction(tx_execution_result).await?;
println!("Submitted a transaction with 4 P2ID notes.");
// Send 50 tokens to 1 more account as a single P2ID transaction
println!("Submitting one more single P2ID transaction...");
let init_seed = {
let mut seed = [0u8; 15];
rand::thread_rng().fill(&mut seed);
seed[0] = 99u8;
seed
};
let target_account_id = AccountId::dummy(
init_seed,
AccountIdVersion::Version0,
AccountType::RegularAccountUpdatableCode,
AccountStorageMode::Public,
);
let send_amount = 50;
let fungible_asset = FungibleAsset::new(faucet_account.id(), send_amount).unwrap();
let payment_transaction = PaymentTransactionData::new(
vec![fungible_asset.into()],
alice_account.id(),
target_account_id,
);
let transaction_request = TransactionRequestBuilder::pay_to_id(
payment_transaction,
None, // recall_height
NoteType::Public, // note type
client.rng(), // rng
)
.unwrap()
.build();
let tx_execution_result = client
.new_transaction(alice_account.id(), transaction_request)
.await?;
client.submit_transaction(tx_execution_result).await?;
println!("\nAll steps completed successfully!");
println!("Alice created a wallet, a faucet was deployed,");
println!("5 notes of 100 tokens were minted to Alice, those notes were consumed,");
println!("and then Alice sent 5 separate 50-token notes to 5 different users.");
Ok(())
}
Let's run the src/main.rs program again:
cargo run --release
The output will look like this:
Client initialized successfully.
Latest block number: 1519
[STEP 1] Creating a new account for Alice
Alice's account ID: "0xd0e8ba5acf2e83100000887188d2b9"
[STEP 2] Deploying a new fungible faucet.
Faucet account ID: "0xcdf877e221333a2000002e2b7ff0b2"
[STEP 3] Minting 5 notes of 100 tokens each for Alice.
Minted note #1 of 100 tokens for Alice.
Minted note #2 of 100 tokens for Alice.
Minted note #3 of 100 tokens for Alice.
Minted note #4 of 100 tokens for Alice.
Minted note #5 of 100 tokens for Alice.
All 5 notes minted for Alice successfully!
[STEP 4] Alice will now consume all of her notes to consolidate them.
Currently, Alice has 1 consumable notes. Waiting for 5...
Currently, Alice has 4 consumable notes. Waiting for 5...
Found 5 consumable notes for Alice. Consuming them now...
one or more warnings were emitted
All of Alice's notes consumed successfully.
[STEP 5] Alice sends 5 notes of 50 tokens each to 5 different users.
Creating multiple P2ID notes for 4 target accounts in one transaction...
Submitted a transaction with 4 P2ID notes.
Submitting one more single P2ID transaction...
All steps completed successfully!
Alice created a wallet, a faucet was deployed,
5 notes of 100 tokens were minted to Alice, those notes were consumed,
and then Alice sent 5 separate 50-token notes to 5 different users.
Running the example
To run a full working example navigate to the rust-client directory in the miden-tutorials repository and run this command:
cd rust-client
cargo run --release --bin create_mint_consume_send
Continue learning
Next tutorial: Deploying a Counter Contract
Deploying a Counter Contract
Using the Miden client in Rust to deploy and interact with a custom smart contract on Miden
Overview
In this tutorial, we will build a simple counter smart contract that maintains a count, deploy it to the Miden testnet, and interact with it by incrementing the count. You can also deploy the counter contract on a locally running Miden node, similar to previous tutorials.
Using a script, we will invoke the increment function within the counter contract to update the count. This tutorial provides a foundational understanding of developing and deploying custom smart contracts on Miden.
What we'll cover
- Deploying a custom smart contract on Miden
- Getting up to speed with the basics of Miden assembly
- Calling procedures in an account
- Pure vs state changing procedures
Prerequisites
This tutorial assumes you have a basic understanding of Miden assembly. To quickly get up to speed with Miden assembly (MASM), please play around with running Miden programs in the Miden playground.
Step 1: Initialize your repository
Create a new Rust repository for your Miden project and navigate to it with the following command:
cargo new miden-counter-contract
cd miden-counter-contract
Add the following dependencies to your Cargo.toml file:
[dependencies]
miden-client = { version = "0.7", features = ["testing", "concurrent", "tonic", "sqlite"] }
miden-lib = { version = "0.7", default-features = false }
miden-objects = { version = "0.7.2", default-features = false }
miden-crypto = { version = "0.13.2", features = ["executable"] }
rand = { version = "0.8" }
serde = { version = "1", features = ["derive"] }
serde_json = { version = "1.0", features = ["raw_value"] }
tokio = { version = "1.40", features = ["rt-multi-thread", "net", "macros"] }
rand_chacha = "0.3.1"
Set up your src/main.rs file
In the previous section, we explained how to instantiate the Miden client. We can reuse the same initialize_client function for our counter contract.
Copy and paste the following code into your src/main.rs file:
use std::{fs, path::Path, sync::Arc};
use rand::Rng;
use rand_chacha::rand_core::SeedableRng;
use rand_chacha::ChaCha20Rng;
use tokio::time::Duration;
use miden_client::{
account::{AccountStorageMode, AccountType},
crypto::RpoRandomCoin,
rpc::{Endpoint, TonicRpcClient},
store::{sqlite_store::SqliteStore, StoreAuthenticator},
transaction::{TransactionKernel, TransactionRequestBuilder},
Client, ClientError, Felt,
};
use miden_objects::{
account::{AccountBuilder, AccountComponent, AuthSecretKey, StorageSlot},
assembly::Assembler,
crypto::{dsa::rpo_falcon512::SecretKey, hash::rpo::RpoDigest},
Word,
};
pub async fn initialize_client() -> Result<Client<RpoRandomCoin>, ClientError> {
// RPC endpoint and timeout
let endpoint = Endpoint::new(
"https".to_string(),
"rpc.testnet.miden.io".to_string(),
Some(443),
);
let timeout_ms = 10_000;
// Build RPC client
let rpc_api = Box::new(TonicRpcClient::new(endpoint, timeout_ms));
// Seed RNG
let mut seed_rng = rand::thread_rng();
let coin_seed: [u64; 4] = seed_rng.gen();
// Create random coin instance
let rng = RpoRandomCoin::new(coin_seed.map(Felt::new));
// SQLite path
let store_path = "store.sqlite3";
// Initialize SQLite store
let store = SqliteStore::new(store_path.into())
.await
.map_err(ClientError::StoreError)?;
let arc_store = Arc::new(store);
// Create authenticator referencing the store and RNG
let authenticator = StoreAuthenticator::new_with_rng(arc_store.clone(), rng);
// Instantiate client (toggle debug mode as needed)
let client = Client::new(rpc_api, rng, arc_store, Arc::new(authenticator), true);
Ok(client)
}
pub fn get_new_pk_and_authenticator() -> (Word, AuthSecretKey) {
// Create a deterministic RNG with zeroed seed
let seed = [0_u8; 32];
let mut rng = ChaCha20Rng::from_seed(seed);
// Generate Falcon-512 secret key
let sec_key = SecretKey::with_rng(&mut rng);
// Convert public key to `Word` (4xFelt)
let pub_key: Word = sec_key.public_key().into();
// Wrap secret key in `AuthSecretKey`
let auth_secret_key = AuthSecretKey::RpoFalcon512(sec_key);
(pub_key, auth_secret_key)
}
#[tokio::main]
async fn main() -> Result<(), ClientError> {
let mut client = initialize_client().await?;
println!("Client initialized successfully.");
let sync_summary = client.sync_state().await.unwrap();
println!("Latest block: {}", sync_summary.block_num);
Ok(())
}
When running the code above, there will be some unused imports, however, we will use these imports later on in the tutorial.
Step 2: Build the counter contract
For better code organization, we will separate the Miden assembly code from our Rust code.
Create a directory named masm at the root of your miden-counter-contract directory. This will contain our contract and script masm code.
Initialize the masm directory:
mkdir -p masm/accounts masm/scripts
This will create:
masm/
├── accounts/
└── scripts/
Custom Miden smart contract
Below is our counter contract. It has a two exported procedures: get_count and increment_count.
At the beginning of the MASM file, we define our imports. In this case, we import miden::account and std::sys.
The import miden::account contains useful procedures for interacting with a smart contract's state.
The import std::sys contains a useful procedure for truncating the operand stack at the end of a procedure.
Here's a breakdown of what the get_count procedure does:
- Pushes
0onto the stack, representing the index of the storage slot to read. - Calls
account::get_itemwith the index of0. - Calls
sys::truncate_stackto truncate the stack to size 16. - The value returned from
account::get_itemis still on the stack and will be returned when this procedure is called.
Here's a breakdown of what the increment_count procedure does:
- Pushes
0onto the stack, representing the index of the storage slot to read. - Calls
account::get_itemwith the index of0. - Pushes
1onto the stack. - Adds
1to the count value returned fromaccount::get_item. - For demonstration purposes, calls
debug.stackto see the state of the stack - Pushes
0onto the stack, which is the index of the storage slot we want to write to. - Calls
account::set_itemwhich saves the incremented count to storage at index0 - Calls
sys::truncate_stackto truncate the stack to size 16.
Inside of the masm/accounts/ directory, create the counter.masm file:
use.miden::account
use.std::sys
export.get_count
# => []
push.0
# => [index]
exec.account::get_item
# => [count]
exec.sys::truncate_stack
end
export.increment_count
# => []
push.0
# => [index]
exec.account::get_item
# => [count]
push.1 add
# debug statement with client
debug.stack
# => [count+1]
push.0
# [index, count+1]
exec.account::set_item
# => []
push.1 exec.account::incr_nonce
# => []
exec.sys::truncate_stack
end
Note: It's a good habit to add comments above each line of MASM code with the expected stack state. This improves readability and helps with debugging.
Concept of function visibility and modifiers in Miden smart contracts
The increment_count function in our Miden smart contract behaves like an "external" Solidity function without a modifier, meaning any user can call it to increment the contract's count. This is because it calls account::incr_nonce during execution.
If the increment_count procedure did not call the account::incr_nonce procedure during its execution, only the deployer of the counter contract would be able to increment the count of the smart contract (if the RpoFalcon512 component was added to the account, in this case we didn't add it).
In essence, if a procedure performs a state change in the Miden smart contract, and does not call account::incr_nonce at some point during its execution, this function can be equated to having an onlyOwner Solidity modifer, meaning only the user with knowledge of the private key of the account can execute transactions that result in a state change.
Note: Adding the account::incr_nonce to a state changing procedure allows any user to call the procedure.
Custom script
This is a Miden assembly script that will call the increment_count procedure during the transaction.
The string {increment_count} will be replaced with the hash of the increment_count procedure in our rust program.
Inside of the masm/scripts/ directory, create the counter_script.masm file:
begin
# => []
call.{increment_count}
end
Step 3: Build the counter smart contract in Rust
To build the counter contract copy and paste the following code at the end of your src/main.rs file:
Run the following command to execute src/main.rs:
cargo run --release
After the program executes, you should see the counter contract hash and contract id printed to the terminal, for example:
counter_contract hash: "0xd693494753f51cb73a436916077c7b71c680a6dddc64dc364c1fe68f16f0c087"
contract id: "0x082ed14c8ad9a866"
Step 4: Computing the prodedure hashes
Each Miden assembly procedure has an associated hash. When calling a procedure in a smart contract, we need to know the hash of the procedure. The hashes of the procedures form a Merkelized Abstract Syntax Tree (MAST).
To get the hash of the increment_count procedure, add this code snippet to the end of your main() function:
Run the following command to execute src/main.rs:
cargo run --release
After the program executes, you should see the procedure hashes printed to the terminal, for example:
increment_count procedure hash: "0xecd7eb223a5524af0cc78580d96357b298bb0b3d33fe95aeb175d6dab9de2e54"
This is the hash of the increment_count procedure.
Step 4: Incrementing the count
Now that we know the hash of the increment_count procedure, we can call the procedure in the counter contract. In the Rust code below, we replace the {increment_count} string with the hash of the increment_count procedure.
Then we create a new transaction request with our custom script, and then pass the transaction request to the client.
Paste the following code at the end of your src/main.rs file:
Note: Once our counter contract is deployed, other users can increment the count of the smart contract simply by knowing the account id of the contract and the procedure hash of the increment_count procedure.
Summary
The final src/main.rs file should look like this:
use std::{fs, path::Path, sync::Arc};
use rand::Rng;
use rand_chacha::rand_core::SeedableRng;
use rand_chacha::ChaCha20Rng;
use tokio::time::Duration;
use miden_client::{
account::{AccountStorageMode, AccountType},
crypto::RpoRandomCoin,
rpc::{Endpoint, TonicRpcClient},
store::{sqlite_store::SqliteStore, StoreAuthenticator},
transaction::{TransactionKernel, TransactionRequestBuilder},
Client, ClientError, Felt,
};
use miden_objects::{
account::{AccountBuilder, AccountComponent, AuthSecretKey, StorageSlot},
assembly::Assembler,
crypto::dsa::rpo_falcon512::SecretKey,
Word,
};
pub async fn initialize_client() -> Result<Client<RpoRandomCoin>, ClientError> {
// RPC endpoint and timeout
let endpoint = Endpoint::new(
"https".to_string(),
"rpc.testnet.miden.io".to_string(),
Some(443),
);
let timeout_ms = 10_000;
// Build RPC client
let rpc_api = Box::new(TonicRpcClient::new(endpoint, timeout_ms));
// Seed RNG
let mut seed_rng = rand::thread_rng();
let coin_seed: [u64; 4] = seed_rng.gen();
// Create random coin instance
let rng = RpoRandomCoin::new(coin_seed.map(Felt::new));
// SQLite path
let store_path = "store.sqlite3";
// Initialize SQLite store
let store = SqliteStore::new(store_path.into())
.await
.map_err(ClientError::StoreError)?;
let arc_store = Arc::new(store);
// Create authenticator referencing the store and RNG
let authenticator = StoreAuthenticator::new_with_rng(arc_store.clone(), rng);
// Instantiate client (toggle debug mode as needed)
let client = Client::new(rpc_api, rng, arc_store, Arc::new(authenticator), true);
Ok(client)
}
pub fn get_new_pk_and_authenticator() -> (Word, AuthSecretKey) {
// Create a deterministic RNG with zeroed seed
let seed = [0_u8; 32];
let mut rng = ChaCha20Rng::from_seed(seed);
// Generate Falcon-512 secret key
let sec_key = SecretKey::with_rng(&mut rng);
// Convert public key to `Word` (4xFelt)
let pub_key: Word = sec_key.public_key().into();
// Wrap secret key in `AuthSecretKey`
let auth_secret_key = AuthSecretKey::RpoFalcon512(sec_key);
(pub_key, auth_secret_key)
}
#[tokio::main]
async fn main() -> Result<(), ClientError> {
// Initialize client
let mut client = initialize_client().await?;
println!("Client initialized successfully.");
// Fetch latest block from node
let sync_summary = client.sync_state().await.unwrap();
println!("Latest block: {}", sync_summary.block_num);
// -------------------------------------------------------------------------
// STEP 1: Create a basic counter contract
// -------------------------------------------------------------------------
println!("\n[STEP 1] Creating counter contract.");
// Load the MASM file for the counter contract
let file_path = Path::new("./masm/accounts/counter.masm");
let account_code = fs::read_to_string(file_path).unwrap();
// Prepare assembler (debug mode = true)
let assembler: Assembler = TransactionKernel::assembler().with_debug_mode(true);
// Compile the account code into `AccountComponent` with one storage slot
let counter_component = AccountComponent::compile(
account_code,
assembler,
vec![StorageSlot::Value([
Felt::new(0),
Felt::new(0),
Felt::new(0),
Felt::new(0),
])],
)
.unwrap()
.with_supports_all_types();
// Init seed for the counter contract
let init_seed = ChaCha20Rng::from_entropy().gen();
// Anchor block of the account
let anchor_block = client.get_latest_epoch_block().await.unwrap();
// Build the new `Account` with the component
let (counter_contract, counter_seed) = AccountBuilder::new(init_seed)
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::RegularAccountImmutableCode)
.storage_mode(AccountStorageMode::Public)
.with_component(counter_component.clone())
.build()
.unwrap();
println!(
"counter_contract hash: {:?}",
counter_contract.hash().to_hex()
);
println!("contract id: {:?}", counter_contract.id().to_hex());
println!("account_storage: {:?}", counter_contract.storage());
// Since anyone should be able to write to the counter contract, auth_secret_key is not required.
// However, to import to the client, we must generate a random value.
let (_counter_pub_key, auth_secret_key) = get_new_pk_and_authenticator();
client
.add_account(
&counter_contract.clone(),
Some(counter_seed),
&auth_secret_key,
false,
)
.await
.unwrap();
// Print the procedure hash
let get_increment_export = counter_component
.library()
.exports()
.find(|export| export.name.as_str() == "increment_count")
.unwrap();
let get_increment_count_mast_id = counter_component
.library()
.get_export_node_id(get_increment_export);
let increment_count_hash = counter_component
.library()
.mast_forest()
.get_node_by_id(get_increment_count_mast_id)
.unwrap()
.digest()
.to_hex();
println!("increment_count procedure hash: {:?}", increment_count_hash);
// -------------------------------------------------------------------------
// STEP 2: Call the Counter Contract with a script
// -------------------------------------------------------------------------
println!("\n[STEP 2] Call Counter Contract With Script");
// Load the MASM script referencing the increment procedure
let file_path = Path::new("./masm/scripts/counter_script.masm");
let original_code = fs::read_to_string(file_path).unwrap();
// Replace the placeholder with the actual procedure call
let replaced_code = original_code.replace("{increment_count}", &increment_count_hash);
println!("Final script:\n{}", replaced_code);
// Compile the script referencing our procedure
let tx_script = client.compile_tx_script(vec![], &replaced_code).unwrap();
// Build a transaction request with the custom script
let tx_increment_request = TransactionRequestBuilder::new()
.with_custom_script(tx_script)
.unwrap()
.build();
// Execute the transaction locally
let tx_result = client
.new_transaction(counter_contract.id(), tx_increment_request)
.await
.unwrap();
let tx_id = tx_result.executed_transaction().id();
println!(
"View transaction on MidenScan: https://testnet.midenscan.com/tx/{:?}",
tx_id
);
// Submit transaction to the network
let _ = client.submit_transaction(tx_result).await;
// Wait, then re-sync
tokio::time::sleep(Duration::from_secs(3)).await;
client.sync_state().await.unwrap();
// Retrieve updated contract data to see the incremented counter
let account = client.get_account(counter_contract.id()).await.unwrap();
println!(
"counter contract storage: {:?}",
account.unwrap().account().storage().get_item(0)
);
Ok(())
}
The output of our program will look something like this:
Client initialized successfully.
Latest block: 118178
[STEP 1] Creating counter contract.
counter_contract hash: "0xa1802c8cfba2bd9c1c0f0b10b875795445566bd61864a05103bdaff167775293"
contract id: "0x4eedb9db1bdcf90000036bcebfe53a"
account_storage: AccountStorage { slots: [Value([0, 0, 0, 0])] }
increment_count procedure hash: "0xecd7eb223a5524af0cc78580d96357b298bb0b3d33fe95aeb175d6dab9de2e54"
[STEP 2] Call Counter Contract With Script
Final script:
begin
# => []
call.0xecd7eb223a5524af0cc78580d96357b298bb0b3d33fe95aeb175d6dab9de2e54
end
Stack state before step 2384:
├── 0: 1
├── 1: 0
├── 2: 0
├── 3: 0
├── 4: 0
├── 5: 0
├── 6: 0
├── 7: 0
├── 8: 0
├── 9: 0
├── 10: 0
├── 11: 0
├── 12: 0
├── 13: 0
├── 14: 0
├── 15: 0
├── 16: 0
├── 17: 0
├── 18: 0
└── 19: 0
View transaction on MidenScan: https://testnet.midenscan.com/tx/0x4384619bba7e6c959a31769a52ce8c6c081ffab00be33e85f58f62cccfd32c21
counter contract storage: Ok(RpoDigest([0, 0, 0, 1]))
The line in the output Stack state before step 2384 ouputs the stack state when we call "debug.stack" in the counter.masm file.
To increment the count of the counter contract all you need is to know the account id of the counter and the procedure hash of the increment_count procedure. To increment the count without deploying the counter each time, you can modify the program above to hardcode the account id of the counter and the procedure hash of the increment_count prodedure in the masm script.
Running the example
To run the full example, navigate to the rust-client directory in the miden-tutorials repository and run this command:
cd rust-client
cargo run --release --bin counter_contract_deploy
Continue learning
Next tutorial: Interacting with Public Smart Contracts
Interacting with Public Smart Contracts
Using the Miden client in Rust to interact with public smart contracts on Miden
Overview
In the previous tutorial, we built a simple counter contract and deployed it to the Miden testnet. However, we only covered how the contract’s deployer could interact with it. Now, let’s explore how anyone can interact with a public smart contract on Miden.
We’ll retrieve the counter contract’s state from the chain and rebuild it locally so a local transaction can be executed against it. In the near future, Miden will support network transactions, making the process of submitting transactions to public smart contracts much more like traditional blockchains.
Just like in the previous tutorial, we will use a script to invoke the increment function within the counter contract to update the count. However, this tutorial demonstrates how to call a procedure in a smart contract that was deployed by a different user on Miden.
What we'll cover
- Reading state from a public smart contract
- Interacting with public smart contracts on Miden
Prerequisites
This tutorial assumes you have a basic understanding of Miden assembly and completed the previous tutorial on deploying the counter contract. Although not a requirement, it is recommended to complete the counter contract deployment tutorial before starting this tutorial.
Step 1: Initialize your repository
Create a new Rust repository for your Miden project and navigate to it with the following command:
cargo new miden-counter-contract
cd miden-counter-contract
Add the following dependencies to your Cargo.toml file:
[dependencies]
miden-client = { version = "0.7", features = ["testing", "concurrent", "tonic", "sqlite"] }
miden-lib = { version = "0.7", default-features = false }
miden-objects = { version = "0.7.2", default-features = false }
miden-crypto = { version = "0.13.2", features = ["executable"] }
rand = { version = "0.8" }
serde = { version = "1", features = ["derive"] }
serde_json = { version = "1.0", features = ["raw_value"] }
tokio = { version = "1.40", features = ["rt-multi-thread", "net", "macros"] }
rand_chacha = "0.3.1"
Step 2: Build the counter contract
For better code organization, we will separate the Miden assembly code from our Rust code.
Create a directory named masm at the root of your miden-counter-contract directory. This will contain our contract and script masm code.
Initialize the masm directory:
mkdir -p masm/accounts masm/scripts
This will create:
masm/
├── accounts/
└── scripts/
Inside of the masm/accounts/ directory, create the counter.masm file:
use.miden::account
use.std::sys
export.get_count
# => []
push.0
# => [index]
exec.account::get_item
# => [count]
exec.sys::truncate_stack
end
export.increment_count
# => []
push.0
# => [index]
exec.account::get_item
# => [count]
push.1 add
# debug statement with client
debug.stack
# => [count+1]
push.0
# [index, count+1]
exec.account::set_item
# => []
push.1 exec.account::incr_nonce
# => []
exec.sys::truncate_stack
end
Inside of the masm/scripts/ directory, create the counter_script.masm file:
begin
# => []
call.{increment_count}
end
Note: We explained in the previous counter contract tutorial what exactly happens at each step in the increment_count procedure.
Step 3: Set up your src/main.rs file
Copy and paste the following code into your src/main.rs file:
use std::{fs, path::Path, sync::Arc};
use rand::Rng;
use rand_chacha::rand_core::SeedableRng;
use rand_chacha::ChaCha20Rng;
use tokio::time::Duration;
use miden_client::{
account::{Account, AccountCode, AccountId, AccountType},
asset::AssetVault,
crypto::RpoRandomCoin,
rpc::{domain::account::AccountDetails, Endpoint, TonicRpcClient},
store::{sqlite_store::SqliteStore, StoreAuthenticator},
transaction::{TransactionKernel, TransactionRequestBuilder},
Client, ClientError, Felt,
};
use miden_objects::{
account::{AccountComponent, AccountStorage, AuthSecretKey, StorageSlot},
assembly::Assembler,
crypto::dsa::rpo_falcon512::SecretKey,
Word,
};
pub async fn initialize_client() -> Result<Client<RpoRandomCoin>, ClientError> {
// RPC endpoint and timeout
let endpoint = Endpoint::new(
"https".to_string(),
"rpc.testnet.miden.io".to_string(),
Some(443),
);
let timeout_ms = 10_000;
// Build RPC client
let rpc_api = Box::new(TonicRpcClient::new(endpoint, timeout_ms));
// Seed RNG
let mut seed_rng = rand::thread_rng();
let coin_seed: [u64; 4] = seed_rng.gen();
// Create random coin instance
let rng = RpoRandomCoin::new(coin_seed.map(Felt::new));
// SQLite path
let store_path = "store.sqlite3";
// Initialize SQLite store
let store = SqliteStore::new(store_path.into())
.await
.map_err(ClientError::StoreError)?;
let arc_store = Arc::new(store);
// Create authenticator referencing the store and RNG
let authenticator = StoreAuthenticator::new_with_rng(arc_store.clone(), rng);
// Instantiate client (toggle debug mode as needed)
let client = Client::new(rpc_api, rng, arc_store, Arc::new(authenticator), true);
Ok(client)
}
pub fn get_new_pk_and_authenticator() -> (Word, AuthSecretKey) {
// Create a deterministic RNG with zeroed seed
let seed = [0_u8; 32];
let mut rng = ChaCha20Rng::from_seed(seed);
// Generate Falcon-512 secret key
let sec_key = SecretKey::with_rng(&mut rng);
// Convert public key to `Word` (4xFelt)
let pub_key: Word = sec_key.public_key().into();
// Wrap secret key in `AuthSecretKey`
let auth_secret_key = AuthSecretKey::RpoFalcon512(sec_key);
(pub_key, auth_secret_key)
}
#[tokio::main]
async fn main() -> Result<(), ClientError> {
// Initialize client
let mut client = initialize_client().await?;
println!("Client initialized successfully.");
// Fetch latest block from node
let sync_summary = client.sync_state().await.unwrap();
println!("Latest block: {}", sync_summary.block_num);
Ok(())
}
Step 4: Reading public state from a smart contract
To read the public storage state of a smart contract on Miden we either instantiate the TonicRpcClient by itself, or use the test_rpc_api() method on the Client instance. In this example, we will be using the test_rpc_api() method.
We will be reading the public storage state of the counter contract deployed on the testnet at address 0x303dd027d27adc0000012b07dbf1b4.
Add the following code snippet to the end of your src/main.rs function:
Run the following command to execute src/main.rs:
cargo run --release
After the program executes, you should see the counter contract count value and nonce printed to the terminal, for example:
count val: [0, 0, 0, 5]
counter nonce: 5
Step 5: Building an account from parts
Now that we know the storage state of the counter contract and its nonce, we can build the account from its parts. We know the account ID, asset vault value, the storage layout, account code, and nonce. We need the full account data to interact with it locally. From these values, we can build the counter contract from scratch.
Add the following code snippet to the end of your src/main.rs function:
Step 6: Incrementing the count
This step is exactly the same as in the counter contract deploy tutorial, the only change being that we hardcode the increment_count procedure hash since this value will not change.
Add the following code snippet to the end of your src/main.rs function:
Summary
The final src/main.rs file should look like this:
use std::{fs, path::Path, sync::Arc};
use rand::Rng;
use rand_chacha::rand_core::SeedableRng;
use rand_chacha::ChaCha20Rng;
use tokio::time::Duration;
use miden_client::{
account::{Account, AccountCode, AccountId, AccountType},
asset::AssetVault,
crypto::RpoRandomCoin,
rpc::{domain::account::AccountDetails, Endpoint, TonicRpcClient},
store::{sqlite_store::SqliteStore, StoreAuthenticator},
transaction::{TransactionKernel, TransactionRequestBuilder},
Client, ClientError, Felt,
};
use miden_objects::{
account::{AccountComponent, AccountStorage, AuthSecretKey, StorageSlot},
assembly::Assembler,
crypto::dsa::rpo_falcon512::SecretKey,
Word,
};
pub async fn initialize_client() -> Result<Client<RpoRandomCoin>, ClientError> {
// RPC endpoint and timeout
let endpoint = Endpoint::new(
"https".to_string(),
"rpc.testnet.miden.io".to_string(),
Some(443),
);
let timeout_ms = 10_000;
// Build RPC client
let rpc_api = Box::new(TonicRpcClient::new(endpoint, timeout_ms));
// Seed RNG
let mut seed_rng = rand::thread_rng();
let coin_seed: [u64; 4] = seed_rng.gen();
// Create random coin instance
let rng = RpoRandomCoin::new(coin_seed.map(Felt::new));
// SQLite path
let store_path = "store.sqlite3";
// Initialize SQLite store
let store = SqliteStore::new(store_path.into())
.await
.map_err(ClientError::StoreError)?;
let arc_store = Arc::new(store);
// Create authenticator referencing the store and RNG
let authenticator = StoreAuthenticator::new_with_rng(arc_store.clone(), rng);
// Instantiate client (toggle debug mode as needed)
let client = Client::new(rpc_api, rng, arc_store, Arc::new(authenticator), true);
Ok(client)
}
pub fn get_new_pk_and_authenticator() -> (Word, AuthSecretKey) {
// Create a deterministic RNG with zeroed seed
let seed = [0_u8; 32];
let mut rng = ChaCha20Rng::from_seed(seed);
// Generate Falcon-512 secret key
let sec_key = SecretKey::with_rng(&mut rng);
// Convert public key to `Word` (4xFelt)
let pub_key: Word = sec_key.public_key().into();
// Wrap secret key in `AuthSecretKey`
let auth_secret_key = AuthSecretKey::RpoFalcon512(sec_key);
(pub_key, auth_secret_key)
}
#[tokio::main]
async fn main() -> Result<(), ClientError> {
// Initialize client
let mut client = initialize_client().await?;
println!("Client initialized successfully.");
// Fetch latest block from node
let sync_summary = client.sync_state().await.unwrap();
println!("Latest block: {}", sync_summary.block_num);
// -------------------------------------------------------------------------
// STEP 1: Read the Public State of the Counter Contract
// -------------------------------------------------------------------------
println!("\n[STEP 1] Reading data from public state");
// Define the Counter Contract account id from counter contract deploy
let counter_contract_id = AccountId::from_hex("0x4eedb9db1bdcf90000036bcebfe53a").unwrap();
let account_details = client
.test_rpc_api()
.get_account_update(counter_contract_id)
.await
.unwrap();
let AccountDetails::Public(counter_contract_details, _) = account_details else {
panic!("counter contract must be public");
};
// Getting the value of the count from slot 0 and the nonce of the counter contract
let count_value = counter_contract_details.storage().slots().first().unwrap();
let counter_nonce = counter_contract_details.nonce();
println!("count val: {:?}", count_value.value());
println!("counter nonce: {:?}", counter_nonce);
// -------------------------------------------------------------------------
// STEP 2: Build the Counter Contract
// -------------------------------------------------------------------------
println!("\n[STEP 2] Building the counter contract");
// Load the MASM file for the counter contract
let file_path = Path::new("./masm/accounts/counter.masm");
let account_code = fs::read_to_string(file_path).unwrap();
// Prepare assembler (debug mode = true)
let assembler: Assembler = TransactionKernel::assembler().with_debug_mode(true);
// Compile the account code into `AccountComponent` with the count value returned by the node
let account_component = AccountComponent::compile(
account_code,
assembler,
vec![StorageSlot::Value(count_value.value())],
)
.unwrap()
.with_supports_all_types();
// Initialize the AccountStorage with the count value returned by the node
let account_storage =
AccountStorage::new(vec![StorageSlot::Value(count_value.value())]).unwrap();
// Build AccountCode from components
let account_code = AccountCode::from_components(
&[account_component],
AccountType::RegularAccountImmutableCode,
)
.unwrap();
// The counter contract doesn't have any assets so we pass an empty vector
let vault = AssetVault::new(&[]).unwrap();
// Build the counter contract from parts
let counter_contract = Account::from_parts(
counter_contract_id,
vault,
account_storage,
account_code,
counter_nonce,
);
// Since anyone should be able to write to the counter contract, auth_secret_key is not required.
// However, to import to the client, we must generate a random value.
let (_, _auth_secret_key) = get_new_pk_and_authenticator();
client
.add_account(&counter_contract.clone(), None, &_auth_secret_key, true)
.await
.unwrap();
// -------------------------------------------------------------------------
// STEP 3: Call the Counter Contract with a script
// -------------------------------------------------------------------------
println!("\n[STEP 3] Call the increment_count procedure in the counter contract");
// The increment_count procedure hash is constant
let increment_procedure = "0xecd7eb223a5524af0cc78580d96357b298bb0b3d33fe95aeb175d6dab9de2e54";
// Load the MASM script referencing the increment procedure
let file_path = Path::new("./masm/scripts/counter_script.masm");
let original_code = fs::read_to_string(file_path).unwrap();
// Replace the placeholder with the actual procedure call
let replaced_code = original_code.replace("{increment_count}", increment_procedure);
println!("Final script:\n{}", replaced_code);
// Compile the script
let tx_script = client.compile_tx_script(vec![], &replaced_code).unwrap();
// Build a transaction request with the custom script
let tx_increment_request = TransactionRequestBuilder::new()
.with_custom_script(tx_script)
.unwrap()
.build();
// Execute the transaction locally
let tx_result = client
.new_transaction(counter_contract.id(), tx_increment_request)
.await
.unwrap();
let tx_id = tx_result.executed_transaction().id();
println!(
"View transaction on MidenScan: https://testnet.midenscan.com/tx/{:?}",
tx_id
);
// Submit transaction to the network
let _ = client.submit_transaction(tx_result).await;
// Wait, then re-sync
tokio::time::sleep(Duration::from_secs(3)).await;
client.sync_state().await.unwrap();
// Retrieve updated contract data to see the incremented counter
let account = client.get_account(counter_contract.id()).await.unwrap();
println!(
"counter contract storage: {:?}",
account.unwrap().account().storage().get_item(0)
);
Ok(())
}
Run the following command to execute src/main.rs:
cargo run --release
The output of our program will look something like this depending on the current count value in the smart contract:
Client initialized successfully.
Latest block: 242342
[STEP 1] Building counter contract from public state
count val: [0, 0, 0, 1]
counter nonce: 1
[STEP 2] Call the increment_count procedure in the counter contract
Procedure 1: "0x92495ca54d519eb5e4ba22350f837904d3895e48d74d8079450f19574bb84cb6"
Procedure 2: "0xecd7eb223a5524af0cc78580d96357b298bb0b3d33fe95aeb175d6dab9de2e54"
number of procedures: 2
Final script:
begin
# => []
call.0xecd7eb223a5524af0cc78580d96357b298bb0b3d33fe95aeb175d6dab9de2e54
end
Stack state before step 1812:
├── 0: 2
├── 1: 0
├── 2: 0
├── 3: 0
├── 4: 0
├── 5: 0
├── 6: 0
├── 7: 0
├── 8: 0
├── 9: 0
├── 10: 0
├── 11: 0
├── 12: 0
├── 13: 0
├── 14: 0
├── 15: 0
├── 16: 0
├── 17: 0
├── 18: 0
└── 19: 0
View transaction on MidenScan: https://testnet.midenscan.com/tx/0x8183aed150f20b9c26d4cb7840bfc92571ea45ece31116170b11cdff2649eb5c
counter contract storage: Ok(RpoDigest([0, 0, 0, 2]))
Running the example
To run the full example, navigate to the rust-client directory in the miden-tutorials repository and run this command:
cd rust-client
cargo run --release --bin counter_contract_increment
Continue learning
Next tutorial: Foreign Procedure Invocation
How to Create a Custom Note
Creating notes with custom logic
Overview
In this guide, we will create a custom note on Miden that can only be consumed by someone who knows the preimage of the hash stored in the note. This approach securely embeds assets into the note and restricts spending to those who possess the correct secret number.
By following the steps below and using the Miden Assembly code and Rust example, you will learn how to:
- Create a note with custom logic.
- Leverage Miden’s privacy features to keep certain transaction details private.
Unlike Ethereum, where all pending transactions are publicly visible in the mempool, Miden enables you to partially or completely hide transaction details.
What we'll cover
- Writing Miden assembly for a note
- Consuming notes
Step-by-step process
1. Creating two accounts: Alice & Bob
First, we create two basic accounts for the two users:
- Alice: The account that creates and funds the custom note.
- Bob: The account that will consume the note if they know the correct secret.
2. Hashing the secret number
The security of the custom note hinges on a secret number. Here, we will:
- Choose a secret number (for example, an array of four integers).
- For simplicity, we're only hashing 4 elements. Therefore, we prepend an empty word—consisting of 4 zero integers—as a placeholder. This is required by the RPO hashing algorithm to ensure the input has the correct structure and length for proper processing.
- Compute the hash of the secret. The resulting hash will serve as the note’s input, meaning that the note can only be consumed if the secret number’s hash preimage is provided during consumption.
3. Creating the custom note
Now, combine the minted asset and the secret hash to build the custom note. The note is created using the following key steps:
-
Note Inputs:
- The note is set up with the asset and the hash of the secret number as its input.
-
Miden Assembly Code:
- The Miden assembly note script ensures that the note can only be consumed if the provided secret, when hashed, matches the hash stored in the note input.
Below is the Miden Assembly code for the note:
use.miden::note
use.miden::contracts::wallets::basic->wallet
# => [HASH_PREIMAGE_SECRET]
begin
# Hashing the secret number
hperm
# => [F,E,D]
# E is digest
dropw swapw dropw
# => [DIGEST]
# Writing the note inputs to memory
push.0 exec.note::get_inputs drop drop
# => [DIGEST]
# Pad stack and load note inputs from memory
padw push.0 mem_loadw
# => [INPUTS, DIGEST]
# Assert that the note input matches the digest
# Will fail if the two hashes do not match
assert_eqw
# => []
# Write the asset in note to memory address 0
push.0 exec.note::get_assets
# => [num_assets, dest_ptr]
drop
# => [dest_ptr]
# Load asset from memory
mem_loadw
# => [ASSET]
# Call receive asset in wallet
call.wallet::receive_asset
# => []
end
How the assembly code works:
-
Passing the Secret:
The secret number is passed asNote Argumentsinto the note. -
Hashing the Secret:
Thehperminstruction applies a hash permutation to the secret number, resulting in a hash that takes up four stack elements. -
Stack Cleanup and Comparison:
The assembly code extracts the digest, loads the note inputs from memory and checks if the computed hash matches the note’s stored hash. -
Asset Transfer:
If the hash of the number passed in asNote Argumentsmatches the hash stored in the note inputs, the script continues, and the asset stored in the note is loaded from memory and passed to Bob’s wallet via thewallet::receive_assetfunction.
5. Consuming the note
With the note created, Bob can now consume it—but only if he provides the correct secret. When Bob initiates the transaction to consume the note, he must supply the same secret number used when Alice created the note. The custom note’s logic will hash the secret and compare it with its stored hash. If they match, Bob’s wallet receives the asset.
Full Rust code example
The following Rust code demonstrates how to implement the steps outlined above using the Miden client library:
use rand::Rng;
use rand_chacha::{rand_core::SeedableRng, ChaCha20Rng};
use std::{fs, path::Path, sync::Arc};
use tokio::time::{sleep, Duration};
use miden_client::{
account::{
component::{BasicFungibleFaucet, BasicWallet, RpoFalcon512},
AccountBuilder, AccountStorageMode, AccountType,
},
asset::{FungibleAsset, TokenSymbol},
crypto::RpoRandomCoin,
note::{
Note, NoteAssets, NoteExecutionHint, NoteExecutionMode, NoteInputs, NoteMetadata,
NoteRecipient, NoteScript, NoteTag, NoteType,
},
rpc::{Endpoint, TonicRpcClient},
store::{sqlite_store::SqliteStore, StoreAuthenticator},
transaction::{OutputNote, TransactionKernel, TransactionRequestBuilder},
Client, ClientError, Felt,
};
use miden_crypto::{hash::rpo::Rpo256 as Hasher, rand::FeltRng};
use miden_objects::{account::AuthSecretKey, crypto::dsa::rpo_falcon512::SecretKey, Word};
// Initialize client helper
pub async fn initialize_client() -> Result<Client<RpoRandomCoin>, ClientError> {
let endpoint = Endpoint::new("https".into(), "rpc.testnet.miden.io".into(), Some(443));
let rpc_api = Box::new(TonicRpcClient::new(endpoint, 10_000));
let coin_seed: [u64; 4] = rand::thread_rng().gen();
let rng = RpoRandomCoin::new(coin_seed.map(Felt::new));
let store = SqliteStore::new("store.sqlite3".into())
.await
.map_err(ClientError::StoreError)?;
let arc_store = Arc::new(store);
let authenticator = StoreAuthenticator::new_with_rng(arc_store.clone(), rng);
Ok(Client::new(
rpc_api,
rng,
arc_store,
Arc::new(authenticator),
true,
))
}
// Helper to create keys & authenticator
pub fn get_new_pk_and_authenticator() -> (Word, AuthSecretKey) {
let seed = [0_u8; 32];
let mut rng = ChaCha20Rng::from_seed(seed);
let sec_key = SecretKey::with_rng(&mut rng);
(
sec_key.public_key().into(),
AuthSecretKey::RpoFalcon512(sec_key),
)
}
// Helper to create a basic account
async fn create_basic_account(
client: &mut Client<RpoRandomCoin>,
) -> Result<miden_client::account::Account, ClientError> {
let mut init_seed = [0u8; 32];
client.rng().fill_bytes(&mut init_seed);
let key_pair = SecretKey::with_rng(client.rng());
let anchor_block = client.get_latest_epoch_block().await.unwrap();
let builder = AccountBuilder::new(init_seed)
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::RegularAccountUpdatableCode)
.storage_mode(AccountStorageMode::Public)
.with_component(RpoFalcon512::new(key_pair.public_key()))
.with_component(BasicWallet);
let (account, seed) = builder.build().unwrap();
client
.add_account(
&account,
Some(seed),
&AuthSecretKey::RpoFalcon512(key_pair),
false,
)
.await?;
Ok(account)
}
async fn create_basic_faucet(
client: &mut Client<RpoRandomCoin>,
) -> Result<miden_client::account::Account, ClientError> {
let mut init_seed = [0u8; 32];
client.rng().fill_bytes(&mut init_seed);
let key_pair = SecretKey::with_rng(client.rng());
let anchor_block = client.get_latest_epoch_block().await.unwrap();
let symbol = TokenSymbol::new("MID").unwrap();
let decimals = 8;
let max_supply = Felt::new(1_000_000);
let builder = AccountBuilder::new(init_seed)
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::FungibleFaucet)
.storage_mode(AccountStorageMode::Public)
.with_component(RpoFalcon512::new(key_pair.public_key()))
.with_component(BasicFungibleFaucet::new(symbol, decimals, max_supply).unwrap());
let (account, seed) = builder.build().unwrap();
client
.add_account(
&account,
Some(seed),
&AuthSecretKey::RpoFalcon512(key_pair),
false,
)
.await?;
Ok(account)
}
// Helper to wait until an account has the expected number of consumable notes
async fn wait_for_notes(
client: &mut Client<RpoRandomCoin>,
account_id: &miden_client::account::Account,
expected: usize,
) -> Result<(), ClientError> {
loop {
client.sync_state().await?;
let notes = client.get_consumable_notes(Some(account_id.id())).await?;
if notes.len() >= expected {
break;
}
println!(
"{} consumable notes found for account {}. Waiting...",
notes.len(),
account_id.id().to_hex()
);
sleep(Duration::from_secs(3)).await;
}
Ok(())
}
#[tokio::main]
async fn main() -> Result<(), ClientError> {
let mut client = initialize_client().await?;
println!(
"Client initialized successfully. Latest block: {}",
client.sync_state().await.unwrap().block_num
);
// -------------------------------------------------------------------------
// STEP 1: Create accounts and deploy faucet
// -------------------------------------------------------------------------
println!("\n[STEP 1] Creating new accounts");
let alice_account = create_basic_account(&mut client).await?;
println!("Alice's account ID: {:?}", alice_account.id().to_hex());
let bob_account = create_basic_account(&mut client).await?;
println!("Bob's account ID: {:?}", bob_account.id().to_hex());
println!("\nDeploying a new fungible faucet.");
let faucet = create_basic_faucet(&mut client).await?;
println!("Faucet account ID: {:?}", faucet.id().to_hex());
client.sync_state().await?;
// -------------------------------------------------------------------------
// STEP 2: Mint tokens with P2ID
// -------------------------------------------------------------------------
println!("\n[STEP 2] Mint tokens with P2ID");
let faucet_id = faucet.id();
let amount: u64 = 100;
let mint_amount = FungibleAsset::new(faucet_id, amount).unwrap();
let tx_req = TransactionRequestBuilder::mint_fungible_asset(
mint_amount.clone(),
alice_account.id(),
NoteType::Public,
client.rng(),
)
.unwrap()
.build();
let tx_exec = client.new_transaction(faucet.id(), tx_req).await?;
client.submit_transaction(tx_exec.clone()).await?;
let p2id_note = if let OutputNote::Full(note) = tx_exec.created_notes().get_note(0) {
note.clone()
} else {
panic!("Expected OutputNote::Full");
};
sleep(Duration::from_secs(3)).await;
wait_for_notes(&mut client, &alice_account, 1).await?;
let consume_req = TransactionRequestBuilder::new()
.with_authenticated_input_notes([(p2id_note.id(), None)])
.build();
let tx_exec = client
.new_transaction(alice_account.id(), consume_req)
.await?;
client.submit_transaction(tx_exec).await?;
client.sync_state().await?;
// -------------------------------------------------------------------------
// STEP 3: Create custom note
// -------------------------------------------------------------------------
println!("\n[STEP 3] Create custom note");
let mut secret_vals = vec![Felt::new(1), Felt::new(2), Felt::new(3), Felt::new(4)];
secret_vals.splice(0..0, Word::default().iter().cloned());
let digest = Hasher::hash_elements(&secret_vals);
println!("digest: {:?}", digest);
let assembler = TransactionKernel::assembler().with_debug_mode(true);
let code = fs::read_to_string(Path::new("../masm/notes/hash_preimage_note.masm")).unwrap();
let rng = client.rng();
let serial_num = rng.draw_word();
let note_script = NoteScript::compile(code, assembler).unwrap();
let note_inputs = NoteInputs::new(digest.to_vec()).unwrap();
let recipient = NoteRecipient::new(serial_num, note_script, note_inputs);
let tag = NoteTag::for_public_use_case(0, 0, NoteExecutionMode::Local).unwrap();
let metadata = NoteMetadata::new(
alice_account.id(),
NoteType::Public,
tag,
NoteExecutionHint::always(),
Felt::new(0),
)?;
let vault = NoteAssets::new(vec![mint_amount.clone().into()])?;
let custom_note = Note::new(vault, metadata, recipient);
println!("note hash: {:?}", custom_note.hash());
let note_req = TransactionRequestBuilder::new()
.with_own_output_notes(vec![OutputNote::Full(custom_note.clone())])
.unwrap()
.build();
let tx_result = client
.new_transaction(alice_account.id(), note_req)
.await
.unwrap();
println!(
"View transaction on MidenScan: https://testnet.midenscan.com/tx/{:?}",
tx_result.executed_transaction().id()
);
let _ = client.submit_transaction(tx_result).await;
client.sync_state().await?;
// -------------------------------------------------------------------------
// STEP 4: Consume the Custom Note
// -------------------------------------------------------------------------
wait_for_notes(&mut client, &bob_account, 1).await?;
println!("\n[STEP 4] Bob consumes the Custom Note with Correct Secret");
let secret = [Felt::new(1), Felt::new(2), Felt::new(3), Felt::new(4)];
let consume_custom_req = TransactionRequestBuilder::new()
.with_authenticated_input_notes([(custom_note.id(), Some(secret))])
.build();
let tx_result = client
.new_transaction(bob_account.id(), consume_custom_req)
.await
.unwrap();
println!(
"Consumed Note Tx on MidenScan: https://testnet.midenscan.com/tx/{:?}",
tx_result.executed_transaction().id()
);
println!("account delta: {:?}", tx_result.account_delta().vault());
let _ = client.submit_transaction(tx_result).await;
Ok(())
}
The output of our program will look something like this:
Client initialized successfully. Latest block: 712247
[STEP 1] Creating new accounts
Alice's account ID: "0x29b5fce5574c7610000aefa165f3dc"
Bob's account ID: "0x771d0942da4eaa10000abaf3cd9cbe"
Deploying a new fungible faucet.
Faucet account ID: "0xbdcf27380ed0a720000a475c9d245c"
[STEP 2] Mint tokens with P2ID
one or more warnings were emitted
[STEP 3] Create custom note
digest: RpoDigest([14371582251229115050, 1386930022051078873, 17689831064175867466, 9632123050519021080])
note hash: RpoDigest([8719495106795865315, 8421971501316867300, 4856711660892764009, 18308680045181895277])
View transaction on MidenScan: https://testnet.midenscan.com/tx/0x5937e82b3496d2059967cf01f9ddb7560eed7808f0543b507fa3a20a0705b037
0 consumable notes found for account 0x771d0942da4eaa10000abaf3cd9cbe. Waiting...
0 consumable notes found for account 0x771d0942da4eaa10000abaf3cd9cbe. Waiting...
[STEP 4] Bob consumes the Custom Note with Correct Secret
one or more warnings were emitted
Consumed Note Tx on MidenScan: https://testnet.midenscan.com/tx/0xf1be229416c77e7d7368de3dfffe0ac0ca8d2dceefbfcf9ba5641f1dce556d7a
account delta: AccountVaultDelta { fungible: FungibleAssetDelta({V0(AccountIdV0 { prefix: 13677193715067692832, suffix: 2893212866075648 }): 100}), non_fungible: NonFungibleAssetDelta({}) }
Conclusion
You have now seen how to create a custom note on Miden that requires a secret preimage to be consumed. We covered:
- Creating and funding accounts (Alice and Bob)
- Hashing a secret number
- Building a note with custom logic in Miden Assembly
- Consuming the note by providing the correct secret
By leveraging Miden’s privacy features, you can create customized logic for secure asset transfers that depend on keeping parts of the transaction private.
Running the example
To run the custom note example, navigate to the rust-client directory in the miden-tutorials repository and run this command:
cd rust-client
cargo run --release --bin hash_preimage_note
Foreign Procedure Invocation Tutorial
Using foreign procedure invocation to craft read-only cross-contract calls in the Miden VM
Overview
In previous tutorials we deployed a public counter contract and incremented the count from a different client instance.
In this tutorial we will cover the basics of "foreign procedure invocation" (FPI) in the Miden VM, by building a "Count Copy" smart contract that reads the count from our previously deployed counter contract and copies the count to its own local storage.
Foreign procedure invocation (FPI) is a powerful tool for building smart contracts in the Miden VM. FPI allows one smart contract to call "read-only" procedures in other smart contracts.
The term "foreign procedure invocation" might sound a bit verbose, but it is as simple as one smart contract calling a non-state modifying procedure in another smart contract. The "EVM equivalent" of foreign procedure invocation would be a smart contract calling a read-only function in another contract.
FPI is useful for developing smart contracts that extend the functionality of existing contracts on Miden. FPI is the core primitive used by price oracles on Miden.
What we'll cover
- Foreign Procedure Invocation (FPI)
- Building a "Count Copy" Smart Contract
Prerequisites
This tutorial assumes you have a basic understanding of Miden assembly and completed the previous tutorial on deploying the counter contract. We will be working within the same miden-counter-contract repository that we created in the Interacting with Public Smart Contracts tutorial.
Step 1: Set up your repository
We will be using the same repository used in the "Interacting with Public Smart Contracts" tutorial. To set up your repository for this tutorial, first follow up until step two here.
Step 2: Set up the "count reader" contract
Inside of the masm/accounts/ directory, create the count_reader.masm file. This is the smart contract that will read the "count" value from the counter contract.
masm/accounts/count_reader.masm:
use.miden::account
use.miden::tx
use.std::sys
# Reads the count from the counter contract
# and then copies the value to storage
export.copy_count
# => []
push.{get_count_proc_hash}
# => [GET_COUNT_HASH]
push.{account_id_suffix}
# => [account_id_suffix]
push.{account_id_prefix}
# => [account_id_prefix, account_id_suffix, GET_COUNT_HASH]
exec.tx::execute_foreign_procedure
# => [count]
debug.stack
# => [count]
push.0
# [index, count]
exec.account::set_item
# => []
push.1 exec.account::incr_nonce
# => []
exec.sys::truncate_stack
end
In the count reader smart contract we have a copy_count procedure that uses tx::execute_foreign_procedure to call the get_count procedure in the counter contract.
To call the get_count procedure, we push its hash along with the counter contract's ID suffix and prefix.
This is what the stack state should look like before we call tx::execute_foreign_procedure:
# => [account_id_prefix, account_id_suffix, GET_COUNT_HASH]
After calling the get_count procedure in the counter contract, we call debug.stack and then save the count of the counter contract to index 0 in storage.
Note: The bracket symbols used in the count copy contract are not valid MASM syntax. These are simply placeholder elements that we will replace with the actual values before compilation.
Inside the masm/scripts/ directory, create the reader_script.masm file:
begin
# => []
call.{copy_count}
end
Step 3: Set up your src/main.rs file:
use std::{fs, path::Path, sync::Arc};
use rand::Rng;
use rand_chacha::rand_core::SeedableRng;
use rand_chacha::ChaCha20Rng;
use tokio::time::Duration;
use miden_client::{
account::{Account, AccountCode, AccountId, AccountStorageMode, AccountType},
asset::AssetVault,
crypto::RpoRandomCoin,
rpc::{
domain::account::{AccountDetails, AccountStorageRequirements},
Endpoint, TonicRpcClient,
},
store::{sqlite_store::SqliteStore, StoreAuthenticator},
transaction::{ForeignAccount, TransactionKernel, TransactionRequestBuilder},
Client, ClientError, Felt,
};
use miden_objects::{
account::{AccountBuilder, AccountComponent, AccountStorage, AuthSecretKey, StorageSlot},
assembly::Assembler,
crypto::dsa::rpo_falcon512::SecretKey,
Word,
};
pub async fn initialize_client() -> Result<Client<RpoRandomCoin>, ClientError> {
// RPC endpoint and timeout
let endpoint = Endpoint::new(
"https".to_string(),
"rpc.testnet.miden.io".to_string(),
Some(443),
);
let timeout_ms = 10_000;
// Build RPC client
let rpc_api = Box::new(TonicRpcClient::new(endpoint, timeout_ms));
// Seed RNG
let mut seed_rng = rand::thread_rng();
let coin_seed: [u64; 4] = seed_rng.gen();
// Create random coin instance
let rng = RpoRandomCoin::new(coin_seed.map(Felt::new));
// SQLite path
let store_path = "store.sqlite3";
// Initialize SQLite store
let store = SqliteStore::new(store_path.into())
.await
.map_err(ClientError::StoreError)?;
let arc_store = Arc::new(store);
// Create authenticator referencing the store and RNG
let authenticator = StoreAuthenticator::new_with_rng(arc_store.clone(), rng);
// Instantiate client (toggle debug mode as needed)
let client = Client::new(rpc_api, rng, arc_store, Arc::new(authenticator), true);
Ok(client)
}
pub fn get_new_pk_and_authenticator() -> (Word, AuthSecretKey) {
// Create a deterministic RNG with zeroed seed
let seed = [0_u8; 32];
let mut rng = ChaCha20Rng::from_seed(seed);
// Generate Falcon-512 secret key
let sec_key = SecretKey::with_rng(&mut rng);
// Convert public key to `Word` (4xFelt)
let pub_key: Word = sec_key.public_key().into();
// Wrap secret key in `AuthSecretKey`
let auth_secret_key = AuthSecretKey::RpoFalcon512(sec_key);
(pub_key, auth_secret_key)
}
#[tokio::main]
async fn main() -> Result<(), ClientError> {
// Initialize client
let mut client = initialize_client().await?;
println!("Client initialized successfully.");
// Fetch latest block from node
let sync_summary = client.sync_state().await.unwrap();
println!("Latest block: {}", sync_summary.block_num);
// -------------------------------------------------------------------------
// STEP 1: Create the Count Reader Contract
// -------------------------------------------------------------------------
println!("\n[STEP 1] Creating count reader contract.");
// Load the MASM file for the counter contract
let file_path = Path::new("./masm/accounts/count_reader.masm");
let raw_account_code = fs::read_to_string(file_path).unwrap();
// Define the counter contract account id and `get_count` procedure hash
let counter_contract_id = AccountId::from_hex("0x4eedb9db1bdcf90000036bcebfe53a").unwrap();
let get_count_hash = "0x92495ca54d519eb5e4ba22350f837904d3895e48d74d8079450f19574bb84cb6";
let count_reader_code = raw_account_code
.replace("{get_count_proc_hash}", get_count_hash)
.replace(
"{account_id_prefix}",
&counter_contract_id.prefix().to_string(),
)
.replace(
"{account_id_suffix}",
&counter_contract_id.suffix().to_string(),
);
// Initialize assembler (debug mode = true)
let assembler: Assembler = TransactionKernel::assembler().with_debug_mode(true);
// Compile the account code into `AccountComponent` with one storage slot
let count_reader_component = AccountComponent::compile(
count_reader_code,
assembler,
vec![StorageSlot::Value(Word::default())],
)
.unwrap()
.with_supports_all_types();
// Init seed for the count reader contract
let init_seed = ChaCha20Rng::from_entropy().gen();
// Using latest block as the anchor block
let anchor_block = client.get_latest_epoch_block().await.unwrap();
// Build the count reader contract with the component
let (count_reader_contract, counter_seed) = AccountBuilder::new(init_seed)
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::RegularAccountImmutableCode)
.storage_mode(AccountStorageMode::Public)
.with_component(count_reader_component.clone())
.build()
.unwrap();
println!(
"count reader contract id: {:?}",
count_reader_contract.id().to_hex()
);
println!(
"count reader storage: {:?}",
count_reader_contract.storage()
);
// Since anyone should be able to write to the counter contract, auth_secret_key is not required.
// However, to import to the client, we must generate a random value.
let (_counter_pub_key, auth_secret_key) = get_new_pk_and_authenticator();
client
.add_account(
&count_reader_contract.clone(),
Some(counter_seed),
&auth_secret_key,
false,
)
.await
.unwrap();
// Getting the root hash of the `copy_count` procedure
let get_proc_export = count_reader_component
.library()
.exports()
.find(|export| export.name.as_str() == "copy_count")
.unwrap();
let get_proc_mast_id = count_reader_component
.library()
.get_export_node_id(get_proc_export);
let copy_count_proc_hash = count_reader_component
.library()
.mast_forest()
.get_node_by_id(get_proc_mast_id)
.unwrap()
.digest()
.to_hex();
println!("copy_count procedure hash: {:?}", copy_count_proc_hash);
Ok(())
}
Run the following command to execute src/main.rs:
cargo run --release
The output of our program will look something like this:
Client initialized successfully.
Latest block: 243826
[STEP 1] Creating count reader contract.
count reader contract id: "0xa47d7e5d8b1b90000003cd45a45a78"
count reader storage: AccountStorage { slots: [Value([0, 0, 0, 0])] }
copy_count procedure hash: "0xa2ab9f6a150e9c598699741187589d0c61de12c35c1bbe591d658950f44ab743"
Step 4: Build and read the state of the counter contract deployed on testnet
Add this snippet to the end of your file in the main() function that we created in the previous step:
This step uses the logic we explained in the Public Account Interaction Tutorial to read the state of the Counter contract and import it to the client locally.
Step 5: Call the counter contract via foreign procedure invocation
Add this snippet to the end of your file in the main() function:
The key here is the use of the .with_foreign_accounts() method on the TransactionRequestBuilder. Using this method, it is possible to create transactions with multiple foreign procedure calls.
Summary
In this tutorial created a smart contract that calls the get_count procedure in the counter contract using foreign procedure invocation, and then saves the returned value to its local storage.
The final src/main.rs file should look like this:
use std::{fs, path::Path, sync::Arc};
use rand::Rng;
use rand_chacha::rand_core::SeedableRng;
use rand_chacha::ChaCha20Rng;
use tokio::time::Duration;
use miden_client::{
account::{Account, AccountCode, AccountId, AccountStorageMode, AccountType},
asset::AssetVault,
crypto::RpoRandomCoin,
rpc::{
domain::account::{AccountDetails, AccountStorageRequirements},
Endpoint, TonicRpcClient,
},
store::{sqlite_store::SqliteStore, StoreAuthenticator},
transaction::{ForeignAccount, TransactionKernel, TransactionRequestBuilder},
Client, ClientError, Felt,
};
use miden_objects::{
account::{AccountBuilder, AccountComponent, AccountStorage, AuthSecretKey, StorageSlot},
assembly::Assembler,
crypto::dsa::rpo_falcon512::SecretKey,
Word,
};
pub async fn initialize_client() -> Result<Client<RpoRandomCoin>, ClientError> {
// RPC endpoint and timeout
let endpoint = Endpoint::new(
"https".to_string(),
"rpc.testnet.miden.io".to_string(),
Some(443),
);
let timeout_ms = 10_000;
// Build RPC client
let rpc_api = Box::new(TonicRpcClient::new(endpoint, timeout_ms));
// Seed RNG
let mut seed_rng = rand::thread_rng();
let coin_seed: [u64; 4] = seed_rng.gen();
// Create random coin instance
let rng = RpoRandomCoin::new(coin_seed.map(Felt::new));
// SQLite path
let store_path = "store.sqlite3";
// Initialize SQLite store
let store = SqliteStore::new(store_path.into())
.await
.map_err(ClientError::StoreError)?;
let arc_store = Arc::new(store);
// Create authenticator referencing the store and RNG
let authenticator = StoreAuthenticator::new_with_rng(arc_store.clone(), rng);
// Instantiate client (toggle debug mode as needed)
let client = Client::new(rpc_api, rng, arc_store, Arc::new(authenticator), true);
Ok(client)
}
pub fn get_new_pk_and_authenticator() -> (Word, AuthSecretKey) {
// Create a deterministic RNG with zeroed seed
let seed = [0_u8; 32];
let mut rng = ChaCha20Rng::from_seed(seed);
// Generate Falcon-512 secret key
let sec_key = SecretKey::with_rng(&mut rng);
// Convert public key to `Word` (4xFelt)
let pub_key: Word = sec_key.public_key().into();
// Wrap secret key in `AuthSecretKey`
let auth_secret_key = AuthSecretKey::RpoFalcon512(sec_key);
(pub_key, auth_secret_key)
}
#[tokio::main]
async fn main() -> Result<(), ClientError> {
// Initialize client
let mut client = initialize_client().await?;
println!("Client initialized successfully.");
// Fetch latest block from node
let sync_summary = client.sync_state().await.unwrap();
println!("Latest block: {}", sync_summary.block_num);
// -------------------------------------------------------------------------
// STEP 1: Create the Count Reader Contract
// -------------------------------------------------------------------------
println!("\n[STEP 1] Creating count reader contract.");
// Load the MASM file for the counter contract
let file_path = Path::new("./masm/accounts/count_reader.masm");
let raw_account_code = fs::read_to_string(file_path).unwrap();
// Define the counter contract account id and `get_count` procedure hash
let counter_contract_id = AccountId::from_hex("0x4eedb9db1bdcf90000036bcebfe53a").unwrap();
let get_count_hash = "0x92495ca54d519eb5e4ba22350f837904d3895e48d74d8079450f19574bb84cb6";
let count_reader_code = raw_account_code
.replace("{get_count_proc_hash}", get_count_hash)
.replace(
"{account_id_prefix}",
&counter_contract_id.prefix().to_string(),
)
.replace(
"{account_id_suffix}",
&counter_contract_id.suffix().to_string(),
);
// Initialize assembler (debug mode = true)
let assembler: Assembler = TransactionKernel::assembler().with_debug_mode(true);
// Compile the account code into `AccountComponent` with one storage slot
let count_reader_component = AccountComponent::compile(
count_reader_code,
assembler,
vec![StorageSlot::Value(Word::default())],
)
.unwrap()
.with_supports_all_types();
// Init seed for the count reader contract
let init_seed = ChaCha20Rng::from_entropy().gen();
// Using latest block as the anchor block
let anchor_block = client.get_latest_epoch_block().await.unwrap();
// Build the count reader contract with the component
let (count_reader_contract, counter_seed) = AccountBuilder::new(init_seed)
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::RegularAccountImmutableCode)
.storage_mode(AccountStorageMode::Public)
.with_component(count_reader_component.clone())
.build()
.unwrap();
println!(
"count reader contract id: {:?}",
count_reader_contract.id().to_hex()
);
println!(
"count reader storage: {:?}",
count_reader_contract.storage()
);
// Since anyone should be able to write to the counter contract, auth_secret_key is not required.
// However, to import to the client, we must generate a random value.
let (_counter_pub_key, auth_secret_key) = get_new_pk_and_authenticator();
client
.add_account(
&count_reader_contract.clone(),
Some(counter_seed),
&auth_secret_key,
false,
)
.await
.unwrap();
// Getting the root hash of the `copy_count` procedure
let get_proc_export = count_reader_component
.library()
.exports()
.find(|export| export.name.as_str() == "copy_count")
.unwrap();
let get_proc_mast_id = count_reader_component
.library()
.get_export_node_id(get_proc_export);
let copy_count_proc_hash = count_reader_component
.library()
.mast_forest()
.get_node_by_id(get_proc_mast_id)
.unwrap()
.digest()
.to_hex();
println!("copy_count procedure hash: {:?}", copy_count_proc_hash);
// -------------------------------------------------------------------------
// STEP 2: Build & Get State of the Counter Contract
// -------------------------------------------------------------------------
println!("\n[STEP 2] Building counter contract from public state");
// Define the Counter Contract account id from counter contract deploy
let account_details = client
.test_rpc_api()
.get_account_update(counter_contract_id)
.await
.unwrap();
let AccountDetails::Public(counter_contract_details, _) = account_details else {
panic!("counter contract must be public");
};
// Getting the value of the count from slot 0 and the nonce of the counter contract
let count_value = counter_contract_details.storage().slots().first().unwrap();
let counter_nonce = counter_contract_details.nonce();
println!("count val: {:?}", count_value.value());
println!("counter nonce: {:?}", counter_nonce);
// Load the MASM file for the counter contract
let file_path = Path::new("./masm/accounts/counter.masm");
let account_code = fs::read_to_string(file_path).unwrap();
// Prepare assembler (debug mode = true)
let assembler: Assembler = TransactionKernel::assembler().with_debug_mode(true);
// Compile the account code into `AccountComponent` with the count value returned by the node
let counter_component = AccountComponent::compile(
account_code,
assembler,
vec![StorageSlot::Value(count_value.value())],
)
.unwrap()
.with_supports_all_types();
// Initialize the AccountStorage with the count value returned by the node
let counter_storage =
AccountStorage::new(vec![StorageSlot::Value(count_value.value())]).unwrap();
// Build AccountCode from components
let counter_code = AccountCode::from_components(
&[counter_component.clone()],
AccountType::RegularAccountImmutableCode,
)
.unwrap();
// The counter contract doesn't have any assets so we pass an empty vector
let vault = AssetVault::new(&[]).unwrap();
// Build the counter contract from parts
let counter_contract = Account::from_parts(
counter_contract_id,
vault,
counter_storage,
counter_code,
counter_nonce,
);
// Since anyone should be able to write to the counter contract, auth_secret_key is not required.
// However, to import to the client, we must generate a random value.
let (_, auth_secret_key) = get_new_pk_and_authenticator();
client
.add_account(&counter_contract.clone(), None, &auth_secret_key, true)
.await
.unwrap();
// -------------------------------------------------------------------------
// STEP 3: Call the Counter Contract via Foreign Procedure Invocation (FPI)
// -------------------------------------------------------------------------
println!("\n[STEP 3] Call Counter Contract with FPI from Count Copy Contract");
// Load the MASM script referencing the increment procedure
let file_path = Path::new("./masm/scripts/reader_script.masm");
let original_code = fs::read_to_string(file_path).unwrap();
// Replace {get_count} and {account_id}
let replaced_code = original_code.replace("{copy_count}", ©_count_proc_hash);
// Compile the script referencing our procedure
let tx_script = client.compile_tx_script(vec![], &replaced_code).unwrap();
let foreign_account =
ForeignAccount::public(counter_contract_id, AccountStorageRequirements::default()).unwrap();
// Build a transaction request with the custom script
let tx_request = TransactionRequestBuilder::new()
.with_foreign_accounts([foreign_account])
.with_custom_script(tx_script)
.unwrap()
.build();
// Execute the transaction locally
let tx_result = client
.new_transaction(count_reader_contract.id(), tx_request)
.await
.unwrap();
let tx_id = tx_result.executed_transaction().id();
println!(
"View transaction on MidenScan: https://testnet.midenscan.com/tx/{:?}",
tx_id
);
// Submit transaction to the network
let _ = client.submit_transaction(tx_result).await;
// Wait, then re-sync
tokio::time::sleep(Duration::from_secs(3)).await;
client.sync_state().await.unwrap();
// Retrieve updated contract data to see the incremented counter
let account_1 = client.get_account(counter_contract.id()).await.unwrap();
println!(
"counter contract storage: {:?}",
account_1.unwrap().account().storage().get_item(0)
);
let account_2 = client
.get_account(count_reader_contract.id())
.await
.unwrap();
println!(
"count reader contract storage: {:?}",
account_2.unwrap().account().storage().get_item(0)
);
Ok(())
}
The output of our program will look something like this:
Client initialized successfully.
Latest block: 242367
[STEP 1] Creating count reader contract.
count reader contract id: "0x95b00b4f410f5000000383ca114c9a"
count reader storage: AccountStorage { slots: [Value([0, 0, 0, 0])] }
copy_count procedure hash: "0xa2ab9f6a150e9c598699741187589d0c61de12c35c1bbe591d658950f44ab743"
[STEP 2] Building counter contract from public state
count val: [0, 0, 0, 2]
counter nonce: 2
[STEP 3] Call Counter Contract with FPI from Count Copy Contract
Stack state before step 3351:
├── 0: 2
├── 1: 0
├── 2: 0
├── 3: 0
├── 4: 0
├── 5: 0
├── 6: 0
├── 7: 0
├── 8: 0
├── 9: 0
├── 10: 0
├── 11: 0
├── 12: 0
├── 13: 0
├── 14: 0
└── 15: 0
View transaction on MidenScan: https://testnet.midenscan.com/tx/0xe2fdb53926e7a11548863c2a85d81127094d6fe38f60509b4ef8ea38994f8cec
counter contract storage: Ok(RpoDigest([0, 0, 0, 2]))
count reader contract storage: Ok(RpoDigest([0, 0, 0, 2]))
Running the example
To run the full example, navigate to the rust-client directory in the miden-tutorials repository and run this command:
cd rust-client
cargo run --release --bin counter_contract_fpi
How to Use Ephemeral Notes
Using ephemeral notes for optimistic note consumption
Overview
In this guide, we will explore how to leverage ephemeral notes on Miden to settle transactions faster than the blocktime. Ephemeral notes are essentially UTXOs that have not yet been fully committed into a block. This feature allows the notes to be created and consumed within the same block.
We construct a chain of transactions using the unauthenticated notes method on the transaction builder. Ephemeral notes are also referred to as "unauthenticated notes" or "erasable notes". We also demonstrate how a note can be serialized and deserialized, highlighting the ability to transfer notes between client instances for asset transfers that can be settled faster than the blocktime.
For example, our demo creates a circle of ephemeral note transactions:
Alice ➡ Bob ➡ Charlie ➡ Dave ➡ Eve ➡ Frank ➡ ...
What we'll cover
- Introduction to Ephemeral Notes: Understand what ephemeral notes are and how they differ from standard notes.
- Serialization Example: See how to serialize and deserialize a note to demonstrate how notes can be propagated to client instances faster than the blocktime.
- Performance Insights: Observe how ephemeral notes can reduce transaction times dramatically.
Step-by-step process
-
Client Initialization:
- Set up an RPC client to connect with the Miden testnet.
- Initialize a random coin generator and a store for persisting account data.
-
Deploying a Fungible Faucet:
- Use a random seed to deploy a fungible faucet.
- Configure the faucet parameters (symbol, decimals, and max supply) and add it to the client.
-
Creating Wallet Accounts:
- Build multiple wallet accounts using a secure key generation process.
- Add these accounts to the client, making them ready for transactions.
-
Minting and Transacting with Ephemeral Notes:
- Mint tokens for one of the accounts (Alice) from the deployed faucet.
- Create a note representing the minted tokens.
- Build and submit a transaction that uses the ephemeral note via the "unauthenticated" method.
- Serialize the note to demonstrate how it could be transferred to another client instance.
- Consume the note in a subsequent transaction, effectively creating a chain of ephemeral transactions.
-
Performance Timing and Syncing:
- Measure the time taken for each transaction iteration.
- Sync the client state and print account balances to verify the transactions.
Full Rust code example
use rand::Rng;
use rand_chacha::rand_core::SeedableRng;
use rand_chacha::ChaCha20Rng;
use std::sync::Arc;
use std::time::Instant;
use tokio::time::Duration;
use miden_client::{
account::{
component::{BasicFungibleFaucet, BasicWallet, RpoFalcon512},
AccountBuilder, AccountStorageMode, AccountType,
},
asset::{FungibleAsset, TokenSymbol},
crypto::RpoRandomCoin,
note::{create_p2id_note, Note, NoteType},
rpc::{Endpoint, TonicRpcClient},
store::{sqlite_store::SqliteStore, StoreAuthenticator},
transaction::{OutputNote, TransactionRequestBuilder},
utils::{Deserializable, Serializable},
Client, ClientError, Felt,
};
use miden_objects::{account::AuthSecretKey, crypto::dsa::rpo_falcon512::SecretKey, Word};
pub async fn initialize_client() -> Result<Client<RpoRandomCoin>, ClientError> {
// RPC endpoint and timeout
let endpoint = Endpoint::new(
"https".to_string(),
"rpc.testnet.miden.io".to_string(),
Some(443),
);
let timeout_ms = 10_000;
let rpc_api = Box::new(TonicRpcClient::new(endpoint, timeout_ms));
let mut seed_rng = rand::thread_rng();
let coin_seed: [u64; 4] = seed_rng.gen();
let rng = RpoRandomCoin::new(coin_seed.map(Felt::new));
let store_path = "store.sqlite3";
let store = SqliteStore::new(store_path.into())
.await
.map_err(ClientError::StoreError)?;
let arc_store = Arc::new(store);
let authenticator = StoreAuthenticator::new_with_rng(arc_store.clone(), rng);
let client = Client::new(rpc_api, rng, arc_store, Arc::new(authenticator), true);
Ok(client)
}
pub fn get_new_pk_and_authenticator() -> (Word, AuthSecretKey) {
let mut seed_rng = rand::thread_rng();
let seed: [u8; 32] = seed_rng.gen();
let mut rng = ChaCha20Rng::from_seed(seed);
let sec_key = SecretKey::with_rng(&mut rng);
let pub_key: Word = sec_key.public_key().into();
let auth_secret_key = AuthSecretKey::RpoFalcon512(sec_key);
(pub_key, auth_secret_key)
}
#[tokio::main]
async fn main() -> Result<(), ClientError> {
// ===== Client Initialization =====
let mut client = initialize_client().await?;
println!("Client initialized successfully.");
// Fetch latest block from node
let sync_summary = client.sync_state().await.unwrap();
println!("Latest block: {}", sync_summary.block_num);
//------------------------------------------------------------
// STEP 1: Deploy a fungible faucet
//------------------------------------------------------------
println!("\n[STEP 1] Deploying a new fungible faucet.");
// Faucet seed
let mut init_seed = [0u8; 32];
client.rng().fill_bytes(&mut init_seed);
// Anchor block
let anchor_block = client.get_latest_epoch_block().await.unwrap();
// Faucet parameters
let symbol = TokenSymbol::new("MID").unwrap();
let decimals = 8;
let max_supply = Felt::new(1_000_000);
// Generate key pair
let key_pair = SecretKey::with_rng(client.rng());
// Build the account
let builder = AccountBuilder::new(init_seed)
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::FungibleFaucet)
.storage_mode(AccountStorageMode::Public)
.with_component(RpoFalcon512::new(key_pair.public_key()))
.with_component(BasicFungibleFaucet::new(symbol, decimals, max_supply).unwrap());
let (faucet_account, seed) = builder.build().unwrap();
// Add the faucet to the client
client
.add_account(
&faucet_account,
Some(seed),
&AuthSecretKey::RpoFalcon512(key_pair),
false,
)
.await?;
println!("Faucet account ID: {}", faucet_account.id().to_hex());
// Resync to show newly deployed faucet
tokio::time::sleep(Duration::from_secs(2)).await;
client.sync_state().await?;
//------------------------------------------------------------
// STEP 2: Create basic wallet accounts
//------------------------------------------------------------
println!("\n[STEP 2] Creating new accounts");
let mut accounts = vec![];
let number_of_accounts = 10;
for i in 0..number_of_accounts {
let init_seed = ChaCha20Rng::from_entropy().gen();
let key_pair = SecretKey::with_rng(client.rng());
let builder = AccountBuilder::new(init_seed)
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::RegularAccountUpdatableCode)
.storage_mode(AccountStorageMode::Public)
.with_component(RpoFalcon512::new(key_pair.public_key()))
.with_component(BasicWallet);
let (account, seed) = builder.build().unwrap();
accounts.push(account.clone());
println!("account id {:?}: {}", i, account.id().to_hex());
client
.add_account(
&account,
Some(seed),
&AuthSecretKey::RpoFalcon512(key_pair.clone()),
true,
)
.await?;
}
// For demo purposes, Alice is the first account.
let alice = &accounts[0];
//------------------------------------------------------------
// STEP 3: Mint and consume tokens for Alice
//------------------------------------------------------------
println!("\n[STEP 3] Mint tokens");
println!("Minting tokens for Alice...");
let amount: u64 = 100;
let fungible_asset_mint_amount = FungibleAsset::new(faucet_account.id(), amount).unwrap();
let transaction_request = TransactionRequestBuilder::mint_fungible_asset(
fungible_asset_mint_amount.clone(),
alice.id(),
NoteType::Public,
client.rng(),
)
.unwrap()
.build();
let tx_execution_result = client
.new_transaction(faucet_account.id(), transaction_request)
.await?;
client
.submit_transaction(tx_execution_result.clone())
.await?;
// The minted fungible asset is public so output is a `Full` note type
let p2id_note: Note =
if let OutputNote::Full(note) = tx_execution_result.created_notes().get_note(0) {
note.clone()
} else {
panic!("Expected Full note type");
};
let transaction_request = TransactionRequestBuilder::new()
.with_unauthenticated_input_notes([(p2id_note, None)])
.build();
let tx_execution_result = client
.new_transaction(alice.id(), transaction_request)
.await?;
client.submit_transaction(tx_execution_result).await?;
client.sync_state().await?;
//------------------------------------------------------------
// STEP 4: Create ephemeral note tx chain
//------------------------------------------------------------
println!("\n[STEP 4] Create ephemeral note tx chain");
let mut landed_blocks = vec![];
let start = Instant::now();
for i in 0..number_of_accounts - 1 {
let loop_start = Instant::now();
println!("\nephemeral tx {:?}", i + 1);
println!("sender: {}", accounts[i].id().to_hex());
println!("target: {}", accounts[i + 1].id().to_hex());
// Time the creation of the p2id note
let send_amount = 20;
let fungible_asset_send_amount =
FungibleAsset::new(faucet_account.id(), send_amount).unwrap();
// for demo purposes, ephemeral notes can be public or private
let note_type = if i % 2 == 0 {
NoteType::Private
} else {
NoteType::Public
};
let p2id_note = create_p2id_note(
accounts[i].id(),
accounts[i + 1].id(),
vec![fungible_asset_send_amount.into()],
note_type,
Felt::new(0),
client.rng(),
)
.unwrap();
let output_note = OutputNote::Full(p2id_note.clone());
// Time transaction request building
let transaction_request = TransactionRequestBuilder::new()
.with_own_output_notes(vec![output_note])
.unwrap()
.build();
let tx_execution_result = client
.new_transaction(accounts[i].id(), transaction_request)
.await?;
client.submit_transaction(tx_execution_result).await?;
// Note serialization/deserialization
// This demonstrates how you could send the serialized note to another client instance
let serialized = p2id_note.to_bytes();
let deserialized_p2id_note = Note::read_from_bytes(&serialized).unwrap();
// Time consume note request building
let consume_note_request =
TransactionRequestBuilder::consume_notes(vec![deserialized_p2id_note.id()])
.with_unauthenticated_input_notes([(deserialized_p2id_note, None)])
.build();
let tx_execution_result = client
.new_transaction(accounts[i + 1].id(), consume_note_request)
.await?;
landed_blocks.push(tx_execution_result.block_num());
client
.submit_transaction(tx_execution_result.clone())
.await?;
println!(
"Consumed Note Tx on MidenScan: https://testnet.midenscan.com/tx/{:?}",
tx_execution_result.executed_transaction().id()
);
println!(
"Total time for loop iteration {}: {:?}",
i,
loop_start.elapsed()
);
}
println!(
"\nTotal execution time for ephemeral note txs: {:?}",
start.elapsed()
);
println!("blocks: {:?}", landed_blocks);
// Final resync and display account balances
tokio::time::sleep(Duration::from_secs(3)).await;
client.sync_state().await?;
for account in accounts.clone() {
let new_account = client.get_account(account.id()).await.unwrap().unwrap();
let balance = new_account
.account()
.vault()
.get_balance(faucet_account.id())
.unwrap();
println!("Account: {} balance: {}", account.id().to_hex(), balance);
}
Ok(())
}
The output of our program will look something like this:
Client initialized successfully.
Latest block: 402875
[STEP 1] Deploying a new fungible faucet.
Faucet account ID: 0x86c03aeb90b2e3200006852488eb50
[STEP 2] Creating new accounts
account id 0: 0x71c184dcaae5ee1000064e93777b70
account id 1: 0x74f3b6cdee937110000655e334161b
account id 2: 0x698ca2e2f7fc7010000643863b9f1a
account id 3: 0x032dd4e8fad68c100006b82d9ca4db
account id 4: 0x5bcca043b5de62100006f8db1610ab
account id 5: 0x6717bbdf75239c10000687c33ce06f
account id 6: 0x752fe4cebebfeb100006e7f9a3129c
account id 7: 0xc8ee0c3e68d384100006aeab3b063d
account id 8: 0x65c8d4a279bf0a100006e1519eca84
account id 9: 0xac0e06f781ac2d1000067663c3aadf
[STEP 3] Mint tokens
Minting tokens for Alice...
one or more warnings were emitted
[STEP 4] Create ephemeral note tx chain
ephemeral tx 1
sender: 0x71c184dcaae5ee1000064e93777b70
target: 0x74f3b6cdee937110000655e334161b
one or more warnings were emitted
Total time for loop iteration 0: 2.990357s
Consumed Note Tx on MidenScan: https://testnet.midenscan.com/tx/0x11b361d0f0aaa1bbff909dcc0eaa5683afb0d2ad000e09a016a70e190bb8552f
ephemeral tx 2
sender: 0x74f3b6cdee937110000655e334161b
target: 0x698ca2e2f7fc7010000643863b9f1a
one or more warnings were emitted
Total time for loop iteration 1: 2.880536333s
Consumed Note Tx on MidenScan: https://testnet.midenscan.com/tx/0x64122981b3405a6b307748473f849b22ae9615706a76145786c553c60de11d31
ephemeral tx 3
sender: 0x698ca2e2f7fc7010000643863b9f1a
target: 0x032dd4e8fad68c100006b82d9ca4db
one or more warnings were emitted
Total time for loop iteration 2: 3.203270708s
Consumed Note Tx on MidenScan: https://testnet.midenscan.com/tx/0xcaeb762b744db5e2874ed33dd30333eb22a0f92117ba648c4894892e59425660
ephemeral tx 4
sender: 0x032dd4e8fad68c100006b82d9ca4db
target: 0x5bcca043b5de62100006f8db1610ab
one or more warnings were emitted
Total time for loop iteration 3: 3.189577792s
Consumed Note Tx on MidenScan: https://testnet.midenscan.com/tx/0xfddc5b0c0668cb1caae144ca230aa5a99da07808f63df213a28fffe3d120ae52
ephemeral tx 5
sender: 0x5bcca043b5de62100006f8db1610ab
target: 0x6717bbdf75239c10000687c33ce06f
one or more warnings were emitted
Total time for loop iteration 4: 2.904180125s
Consumed Note Tx on MidenScan: https://testnet.midenscan.com/tx/0x4d9d23018669aea665daf65dabaedbf1a6f957a4dc85c1012380dfa0a25f1e1f
ephemeral tx 6
sender: 0x6717bbdf75239c10000687c33ce06f
target: 0x752fe4cebebfeb100006e7f9a3129c
one or more warnings were emitted
Total time for loop iteration 5: 2.886588458s
Consumed Note Tx on MidenScan: https://testnet.midenscan.com/tx/0x39be34b79aa24720c007fad3895e585239ca231f230b6e1ed5f4551319895fd9
ephemeral tx 7
sender: 0x752fe4cebebfeb100006e7f9a3129c
target: 0xc8ee0c3e68d384100006aeab3b063d
one or more warnings were emitted
Total time for loop iteration 6: 3.071692334s
Consumed Note Tx on MidenScan: https://testnet.midenscan.com/tx/0x6c38d351b9c4d86b076e6a3e69a667a1ceac94157008d9a0e81ef8370a16c334
ephemeral tx 8
sender: 0xc8ee0c3e68d384100006aeab3b063d
target: 0x65c8d4a279bf0a100006e1519eca84
one or more warnings were emitted
Total time for loop iteration 7: 2.89388675s
Consumed Note Tx on MidenScan: https://testnet.midenscan.com/tx/0x260e2ce59ddab76dc7b403b1003ff891ca2519dda1ee8cd8a9966507b955ff8b
ephemeral tx 9
sender: 0x65c8d4a279bf0a100006e1519eca84
target: 0xac0e06f781ac2d1000067663c3aadf
one or more warnings were emitted
Total time for loop iteration 8: 2.897855958s
Consumed Note Tx on MidenScan: https://testnet.midenscan.com/tx/0x3cdc6659cd270e07137499d204270211dfda8c34aa3a80c3b6dc8064ac8cb09a
Total execution time for ephemeral note txs: 26.920523209s
blocks: [BlockNumber(402884), BlockNumber(402884), BlockNumber(402884), BlockNumber(402884), BlockNumber(402884), BlockNumber(402884), BlockNumber(402884), BlockNumber(402884), BlockNumber(402884)]
Account: 0x71c184dcaae5ee1000064e93777b70 balance: 80
Account: 0x74f3b6cdee937110000655e334161b balance: 0
Account: 0x698ca2e2f7fc7010000643863b9f1a balance: 0
Account: 0x032dd4e8fad68c100006b82d9ca4db balance: 0
Account: 0x5bcca043b5de62100006f8db1610ab balance: 0
Account: 0x6717bbdf75239c10000687c33ce06f balance: 0
Account: 0x752fe4cebebfeb100006e7f9a3129c balance: 0
Account: 0xc8ee0c3e68d384100006aeab3b063d balance: 0
Account: 0x65c8d4a279bf0a100006e1519eca84 balance: 0
Account: 0xac0e06f781ac2d1000067663c3aadf balance: 20
Conclusion
Ephemeral notes on Miden offer a powerful mechanism for achieving faster asset settlements by allowing notes to be both created and consumed within the same block. In this guide, we walked through:
- Minting and Transacting with Ephemeral Notes: Building, serializing, and consuming notes quickly using the Miden client's "unauthenticated note" method.
- Performance Observations: Measuring and demonstrating how ephemeral notes enable assets to be sent faster than the blocktime.
By following this guide, you should now have a clear understanding of how to build and deploy high-performance transactions using ephemeral notes on Miden. Ephemeral notes are the ideal approach for applications like central limit order books (CLOBs) or other DeFi platforms where transaction speed is critical.
Running the example
To run the ephemeral note transfer example, navigate to the rust-client directory in the miden-tutorials repository and run this command:
cd rust-client
cargo run --release --bin ephemeral_note_transfer
How to Use Mappings in Miden Assembly
Using mappings in Miden assembly for storing key value pairs
Overview
In this example, we will explore how to use mappings in Miden Assembly. Mappings are essential data structures that store key-value pairs. We will demonstrate how to create an account that contains a mapping and then call a procedure in that account to update the mapping.
At a high level, this example involves:
- Setting up an account with a mapping stored in one of its storage slots.
- Writing a smart contract in Miden Assembly that includes procedures to read from and write to the mapping.
- Creating a transaction script that calls these procedures.
- Using Rust code to deploy the account and submit a transaction that updates the mapping.
After the Miden Assembly snippets, we explain that the transaction script calls a procedure in the account. This procedure then updates the mapping by modifying the mapping stored in the account's storage slot.
What we'll cover
- How to Use Mappings in Miden Assembly: See how to create a smart contract that uses a mapping.
- How to Link Libraries in Miden Assembly: Demonstrate how to link procedures across Accounts, Notes, and Scripts.
Step-by-step process
-
Setting up an account with a mapping
In this step, you create an account that has a storage slot configured as a mapping. The account smart contract code (shown below) defines procedures to write to and read from this mapping. -
Creating a script that calls a procedure in the account:
Next, you create a transaction script that calls the procedures defined in the account. This script sends the key-value data and then invokes the account procedure, which updates the mapping. -
How to read and write to a mapping in MASM:
Finally, we demonstrate how to use MASM instructions to interact with the mapping. The smart contract uses standard procedures to set a mapping item, retrieve a value from the mapping, and get the current mapping root.
Example of smart contract that uses a mapping
use.miden::account
use.std::sys
# Inputs: [KEY, VALUE]
# Outputs: []
export.write_to_map
# The storage map is in storage slot 1
push.1
# => [index, KEY, VALUE]
# Setting the key value pair in the map
exec.account::set_map_item
# => [OLD_MAP_ROOT, OLD_MAP_VALUE]
dropw dropw dropw dropw
# => []
# Incrementing the nonce by 1
push.1 exec.account::incr_nonce
# => []
end
# Inputs: [KEY]
# Outputs: [VALUE]
export.get_value_in_map
# The storage map is in storage slot 1
push.1
# => [index]
exec.account::get_map_item
# => [VALUE]
end
# Inputs: []
# Outputs: [CURRENT_ROOT]
export.get_current_map_root
# Getting the current root from slot 1
push.1 exec.account::get_item
# => [CURRENT_ROOT]
exec.sys::truncate_stack
# => [CURRENT_ROOT]
end
Explanation of the assembly code
-
write_to_map:
The procedure takes a key and a value as inputs. It pushes the storage index (0for our mapping) onto the stack, then calls theset_map_itemprocedure from the account library to update the mapping. After updating the map, it drops any unused outputs and increments the nonce. -
get_value_in_map:
This procedure takes a key as input and retrieves the corresponding value from the mapping by callingget_map_itemafter pushing the mapping index. -
get_current_map_root:
This procedure retrieves the current root of the mapping (stored at index0) by callingget_itemand then truncating the stack to leave only the mapping root.
Security Note: The procedure write_to_map calls the account procedure incr_nonce. This allows any external account to be able to write to the storage map of the account. Smart contract developers should know that procedures that call the account::incr_nonce procedure allow anyone to call the procedure and modify the state of the account.
Transaction script that calls the smart contract
use.miden_by_example::mapping_example_contract
use.std::sys
begin
push.1.2.3.4
push.0.0.0.0
# => [KEY, VALUE]
call.mapping_example_contract::write_to_map
# => []
push.0.0.0.0
# => [KEY]
call.mapping_example_contract::get_value_in_map
# => [VALUE]
dropw
# => []
call.mapping_example_contract::get_current_map_root
# => [CURRENT_ROOT]
exec.sys::truncate_stack
end
Explanation of the transaction script
The transaction script does the following:
- It pushes a key (
[0.0.0.0]) and a value ([1.2.3.4]) onto the stack. - It calls the
write_to_mapprocedure, which is defined in the account’s smart contract. This updates the mapping in the account. - It then pushes the key again and calls
get_value_in_mapto retrieve the value associated with the key. - Finally, it calls
get_current_map_rootto get the current state (root) of the mapping.
The script calls the write_to_map procedure in the account which writes the key value pair to the mapping.
Rust code that sets everything up
Below is the Rust code that deploys the smart contract, creates the transaction script, and submits a transaction to update the mapping in the account:
use std::{fs, path::Path, sync::Arc};
use rand::Rng;
use rand_chacha::rand_core::SeedableRng;
use rand_chacha::ChaCha20Rng;
use miden_client::{
account::{AccountStorageMode, AccountType},
crypto::RpoRandomCoin,
rpc::{Endpoint, TonicRpcClient},
store::{sqlite_store::SqliteStore, StoreAuthenticator},
transaction::{TransactionKernel, TransactionRequestBuilder},
Client, ClientError, Felt,
};
use miden_objects::{
account::{AccountBuilder, AccountComponent, AuthSecretKey, StorageMap, StorageSlot},
assembly::{Assembler, DefaultSourceManager},
crypto::dsa::rpo_falcon512::SecretKey,
transaction::TransactionScript,
Word,
};
use miden_assembly::{
ast::{Module, ModuleKind},
LibraryPath,
};
pub async fn initialize_client() -> Result<Client<RpoRandomCoin>, ClientError> {
// RPC endpoint and timeout
let endpoint = Endpoint::new(
"https".to_string(),
"rpc.testnet.miden.io".to_string(),
Some(443),
);
let timeout_ms = 10_000;
// Build RPC client
let rpc_api = Box::new(TonicRpcClient::new(endpoint, timeout_ms));
// Seed RNG
let mut seed_rng = rand::thread_rng();
let coin_seed: [u64; 4] = seed_rng.gen();
// Create random coin instance
let rng = RpoRandomCoin::new(coin_seed.map(Felt::new));
// SQLite path
let store_path = "store.sqlite3";
// Initialize SQLite store
let store = SqliteStore::new(store_path.into())
.await
.map_err(ClientError::StoreError)?;
let arc_store = Arc::new(store);
// Create authenticator referencing the store and RNG
let authenticator = StoreAuthenticator::new_with_rng(arc_store.clone(), rng);
// Instantiate client (toggle debug mode as needed)
let client = Client::new(rpc_api, rng, arc_store, Arc::new(authenticator), true);
Ok(client)
}
pub fn get_new_pk_and_authenticator() -> (Word, AuthSecretKey) {
// Create a deterministic RNG with zeroed seed
let seed = [0_u8; 32];
let mut rng = ChaCha20Rng::from_seed(seed);
// Generate Falcon-512 secret key
let sec_key = SecretKey::with_rng(&mut rng);
// Convert public key to `Word` (4xFelt)
let pub_key: Word = sec_key.public_key().into();
// Wrap secret key in `AuthSecretKey`
let auth_secret_key = AuthSecretKey::RpoFalcon512(sec_key);
(pub_key, auth_secret_key)
}
/// Creates a library from the provided source code and library path.
///
/// # Arguments
/// * `assembler` - The assembler instance used to build the library.
/// * `library_path` - The full library path as a string (e.g., "custom_contract::mapping_example").
/// * `source_code` - The MASM source code for the module.
///
/// # Returns
/// A `miden_assembly::Library` that can be added to the transaction script.
fn create_library(
assembler: Assembler,
library_path: &str,
source_code: &str,
) -> Result<miden_assembly::Library, Box<dyn std::error::Error>> {
let source_manager = Arc::new(DefaultSourceManager::default());
let module = Module::parser(ModuleKind::Library).parse_str(
LibraryPath::new(library_path)?,
source_code,
&source_manager,
)?;
let library = assembler.clone().assemble_library([module])?;
Ok(library)
}
#[tokio::main]
async fn main() -> Result<(), ClientError> {
// -------------------------------------------------------------------------
// Initialize the Miden client
// -------------------------------------------------------------------------
let mut client = initialize_client().await?;
println!("Client initialized successfully.");
// Fetch and display the latest synchronized block number from the node.
let sync_summary = client.sync_state().await.unwrap();
println!("Latest block: {}", sync_summary.block_num);
// -------------------------------------------------------------------------
// STEP 1: Deploy a smart contract with a mapping
// -------------------------------------------------------------------------
println!("\n[STEP 1] Deploy a smart contract with a mapping");
// Load the MASM file for the counter contract
let file_path = Path::new("./masm/accounts/mapping_example_contract.masm");
let account_code = fs::read_to_string(file_path).unwrap();
// Prepare assembler (debug mode = true)
let assembler: Assembler = TransactionKernel::assembler().with_debug_mode(true);
// Using an empty storage value in slot 0 since this is usually resurved
// for the account pub_key and metadata
let empty_storage_slot = StorageSlot::empty_value();
// initialize storage map
let storage_map = StorageMap::new();
let storage_slot_map = StorageSlot::Map(storage_map.clone());
// Compile the account code into `AccountComponent` with one storage slot
let mapping_contract_component = AccountComponent::compile(
account_code.clone(),
assembler.clone(),
vec![empty_storage_slot, storage_slot_map],
)
.unwrap()
.with_supports_all_types();
// Init seed for the counter contract
let init_seed = ChaCha20Rng::from_entropy().gen();
// Anchor block of the account
let anchor_block = client.get_latest_epoch_block().await.unwrap();
// Build the new `Account` with the component
let (mapping_example_contract, _seed) = AccountBuilder::new(init_seed)
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::RegularAccountImmutableCode)
.storage_mode(AccountStorageMode::Public)
.with_component(mapping_contract_component.clone())
.build()
.unwrap();
let (_, auth_secret_key) = get_new_pk_and_authenticator();
client
.add_account(
&mapping_example_contract.clone(),
Some(_seed),
&auth_secret_key,
false,
)
.await
.unwrap();
// -------------------------------------------------------------------------
// STEP 2: Call the Mapping Contract with a Script
// -------------------------------------------------------------------------
println!("\n[STEP 2] Call Mapping Contract With Script");
let script_code =
fs::read_to_string(Path::new("./masm/scripts/mapping_example_script.masm")).unwrap();
// Create the library from the account source code using the helper function.
let account_component_lib = create_library(
assembler.clone(),
"miden_by_example::mapping_example_contract",
&account_code,
)
.unwrap();
// Compile the transaction script with the library.
let tx_script = TransactionScript::compile(
script_code,
[],
assembler.with_library(&account_component_lib).unwrap(),
)
.unwrap();
// Build a transaction request with the custom script
let tx_increment_request = TransactionRequestBuilder::new()
.with_custom_script(tx_script)
.unwrap()
.build();
// Execute the transaction locally
let tx_result = client
.new_transaction(mapping_example_contract.id(), tx_increment_request)
.await
.unwrap();
let tx_id = tx_result.executed_transaction().id();
println!(
"View transaction on MidenScan: https://testnet.midenscan.com/tx/{:?}",
tx_id
);
// Submit transaction to the network
let _ = client.submit_transaction(tx_result).await;
client.sync_state().await.unwrap();
let account = client
.get_account(mapping_example_contract.id())
.await
.unwrap();
let index = 1;
let key = [Felt::new(0), Felt::new(0), Felt::new(0), Felt::new(0)];
println!(
"Mapping state\n Index: {:?}\n Key: {:?}\n Value: {:?}",
index,
key,
account
.unwrap()
.account()
.storage()
.get_map_item(index, key)
);
Ok(())
}
What the Rust code does
-
Client Initialization:
The client is initialized with a connection to the Miden Testnet and a SQLite store. This sets up the environment to deploy and interact with accounts. -
Deploying the Smart Contract:
The account containing the mapping is created by reading the MASM smart contract from a file, compiling it into anAccountComponent, and deploying it using anAccountBuilder. -
Creating and Executing a Transaction Script:
A separate MASM script is compiled into aTransactionScript. This script calls the smart contract's procedures to write to and then read from the mapping. -
Displaying the Result:
Finally, after the transaction is processed, the code reads the updated state of the mapping in the account.
Running the example
To run the full example, navigate to the rust-client directory in the miden-tutorials repository and run this command:
cd rust-client
cargo run --release --bin mapping_example
This example shows how the script calls the procedure in the account, which then updates the mapping stored within the account. The mapping update is verified by reading the mapping’s key-value pair after the transaction completes.
WebClient
TypeScript library, which can be used to programmatically interact with the Miden rollup.
The Miden WebClient can be used for a variety of things, including:
- Deploying and creating transactions to interact with accounts and notes on Miden.
- Storing the state of accounts and notes in the browser.
- Generating and submitting proofs of transactions.
- Submitting transactions to delegated proving services.
This section of the docs is an overview of the different things one can achieve using the WebClient, and how to implement them.
Keep in mind that both the WebClient and the documentation are works-in-progress!
Creating Accounts and Deploying Faucets
Using the Miden WebClient in TypeScript to create accounts and deploy faucets
Overview
In this tutorial, we will create a basic web application that interacts with Miden using the Miden WebClient.
Our web application will create a Miden account for Alice and then deploy a fungible faucet. In the next section we will mint tokens from the faucet to fund her account, and then send the tokens from Alice's account to other Miden accounts.
What we'll cover
- Understanding the difference between public and private accounts & notes
- Instantiating the Miden client
- Creating new accounts (public or private)
- Deploying a faucet to fund an account
Prerequisites
In this tutorial we use pnpm which is a drop in replacement for npm.
Public vs. private accounts & notes
Before we dive into the coding, let's clarify the concepts of public and private accounts and notes on Miden:
- Public accounts: The account's data and code are stored on-chain and are openly visible, including its assets.
- Private accounts: The account's state and logic are off-chain, only known to its owner.
- Public notes: The note's state is visible to anyone - perfect for scenarios where transparency is desired.
- Private notes: The note's state is stored off-chain, you will need to share the note data with the relevant parties (via email or Telegram) for them to be able to consume the note.
Note: The term "account" can be used interchangeably with the term "smart contract" since account abstraction on Miden is handled natively.
It is useful to think of notes on Miden as "cryptographic cashier's checks" that allow users to send tokens. If the note is private, the note transfer is only known to the sender and receiver.
Step 1: Initialize your repository
Create a new React TypeScript repository for your Miden web application, navigate to it, and install the Miden WebClient using this command:
pnpm create vite miden-app --template react-ts
Navigate to the new repository:
cd miden-app
Install dependencies:
pnpm install
Install the Miden WebClient SDK:
pnpm i @demox-labs/miden-sdk@0.6.1-next.4
Save this as your vite.config.ts file:
import { defineConfig } from 'vite';
import react from '@vitejs/plugin-react';
export default defineConfig({
plugins: [react()],
build: {
target: 'esnext',
},
optimizeDeps: {
exclude: ['@demox-labs/miden-sdk'], // Exclude the SDK from optimization
},
});
Note: ensure you are using Node version v20.12.0
Step 2: Initialize the client
Before we can interact with the Miden network, we need to instantiate the WebClient. In this step, we specify two parameters:
- RPC endpoint - The URL of the Miden node to which we connect.
- Delegated Prover Endpoint (optional) – The URL of the delegated prover which the client can connect to.
Create a webClient.ts file:
To instantiate the WebClient, pass in the endpoint of the Miden node. You can also instantiate the client with a delegated prover to speed up the proof generation time, however, in this example we will be instantiating the WebClient only with the endpoint of the Miden node since we will be handling proof generation locally within the browser.
Since we will be handling proof generation in the computationally constrained environment of the browser, it will be slower than proof generation handled by the Rust client. Currently, the Miden WebClient is thread-blocking when not used within a web worker.
Example of instantiating the WebClient:
const nodeEndpoint = "https://rpc.testnet.miden.io:443";
const client = await WebClient.create_client(nodeEndpoint);
In the src/ directory create a file named webClient.ts and paste the following into it:
// src/webClient.ts
import { WebClient } from "@demox-labs/miden-sdk";
const nodeEndpoint = "https://rpc.testnet.miden.io:443";
export async function webClient(): Promise<void> {
try {
// 1. Create client
const client = await WebClient.create_client(nodeEndpoint);
// 2. Sync and log block
const state = await client.sync_state();
console.log("Latest block number:", state.block_num());
} catch (error) {
console.error("Error", error);
throw error;
}
}
Edit your App.tsx file:
Set this as your App.tsx file.
// src/App.tsx
import { useState } from "react";
import "./App.css";
import { webClient } from "./webClient";
function App() {
const [clientStarted, setClientStarted] = useState(false);
const handleClick = () => {
webClient();
setClientStarted(true);
};
return (
<div className="App">
<h1>Miden Web App</h1>
<p>Open the console to view logs</p>
{!clientStarted && <button onClick={handleClick}>Start WebClient</button>}
</div>
);
}
export default App;
Starting the frontend:
pnpm run dev
Open the frontend at:
http://localhost:5173/
Now open the browser console. Click the "Start the WebClient" button. Then in the console, you should see something like:
Latest block number: 123
Step 3: Creating a wallet
Now that we've initialized the WebClient, we can create a wallet for Alice.
To create a wallet for Alice using the Miden WebClient, we specify the account type by specifying if the account code is mutable or immutable and whether the account is public or private. A mutable wallet means you can change the account code after deployment.
A wallet on Miden is simply an account with standardized code.
In the example below we create a mutable public account for Alice.
Our src/webClient.ts file should now look something like this:
// src/webClient.ts
import {
WebClient,
AccountStorageMode,
AccountId,
NoteType,
} from "@demox-labs/miden-sdk";
const nodeEndpoint = "https://rpc.testnet.miden.io:443";
export async function webClient(): Promise<void> {
try {
// 1. Create client
const client = await WebClient.create_client(nodeEndpoint);
// 2. Sync and log block
const state = await client.sync_state();
console.log("Latest block number:", state.block_num());
// 3. Create Alice account (public, updatable)
console.log("Creating account for Alice");
const aliceAccount = await client.new_wallet(
AccountStorageMode.public(), // account type
true, // mutability
);
const aliceIdHex = aliceAccount.id().to_string();
console.log("Alice's account ID:", aliceIdHex);
await client.sync_state();
} catch (error) {
console.error("Error:", error);
throw error;
}
}
Step 4: Deploying a fungible faucet
For Alice to receive testnet assets, we first need to deploy a faucet. A faucet account on Miden mints fungible tokens.
We'll create a public faucet with a token symbol, decimals, and a max supply. We will use this faucet to mint tokens to Alice's account in the next section.
Add this snippet to the end of the webClient() function:
// 4. Create faucet
console.log("Creating faucet...");
const faucetAccount = await client.new_faucet(
AccountStorageMode.public(), // account type
false, // is fungible
"MID", // symbol
8, // decimals
BigInt(1_000_000) // max supply
);
const faucetIdHex = faucetAccount.id().to_string();
console.log("Faucet account ID:", faucetIdHex);
await client.sync_state();
When tokens are minted from this faucet, each token batch is represented as a "note" (UTXO). You can think of a Miden Note as a cryptographic cashier's check that has certain spend conditions attached to it.
Summary
Our new src/webClient.ts file should look something like this:
// src/webClient.ts
import {
WebClient,
AccountStorageMode,
AccountId,
NoteType,
} from "@demox-labs/miden-sdk";
const nodeEndpoint = "https://rpc.testnet.miden.io:443";
export async function webClient(): Promise<void> {
try {
// 1. Create client
const client = await WebClient.create_client(nodeEndpoint);
// 2. Sync and log block
const state = await client.sync_state();
console.log("Latest block number:", state.block_num());
// 3. Create Alice account (public, updatable)
console.log("Creating account for Alice");
const aliceAccount = await client.new_wallet(
AccountStorageMode.public(),
true,
);
const aliceIdHex = aliceAccount.id().to_string();
console.log("Alice's account ID:", aliceIdHex);
// 4. Create faucet
console.log("Creating faucet...");
const faucetAccount = await client.new_faucet(
AccountStorageMode.public(), // account type
false, // is fungible
"MID", // symbol
8, // decimals
BigInt(1_000_000) // max supply
);
const faucetIdHex = faucetAccount.id().to_string();
console.log("Faucet account ID:", faucetIdHex);
await client.sync_state();
} catch (error) {
console.error("Error", error);
throw error;
}
}
Let's run the src/main.rs program again:
pnpm run dev
The output will look like this:
Latest block number: 2247
Alice's account ID: 0xd70b2072c6495d100000869a8bacf2
Faucet account ID: 0x2d7e506fb88dde200000a1386efec8
In this section, we explained how to instantiate the Miden client, create a wallet, and deploy a faucet.
In the next section we will cover how to mint tokens from the faucet, consume notes, and send tokens to other accounts.
Running the example
To run a full working example navigate to the web-client directory in the miden-tutorials repository and run the web application example:
cd web-client
pnpm i
pnpm run dev
Mint, Consume, and Create Notes
Using the Miden WebClient in TypeScript to mint, consume, and create notes
Overview
In the previous section, we initialized our repository and covered how to create an account and deploy a faucet. In this section, we will mint tokens from the faucet for Alice, consume the newly created notes, and demonstrate how to send assets to other accounts.
What we'll cover
- Minting assets from a faucet
- Consuming notes to fund an account
- Sending tokens to other users
Step 1: Minting tokens from the faucet
To mint notes with tokens from the faucet we created, Alice can use the WebClient's new_mint_transaction() function.
Below is an example of a transaction request minting tokens from the faucet for Alice.
Add this snippet to the end of the webClient function in the src/webClient.ts file that we created in the previous chapter:
await client.fetch_and_cache_account_auth_by_pub_key(
AccountId.from_hex(faucetIdHex),
);
await client.sync_state();
console.log("Minting tokens to Alice...");
await client.new_mint_transaction(
AccountId.from_hex(aliceIdHex), // target wallet id
AccountId.from_hex(faucetIdHex), // faucet id
NoteType.public(), // note type
BigInt(1000), // amount
);
console.log("Waiting 15 seconds for transaction confirmation...");
await new Promise((resolve) => setTimeout(resolve, 15000));
await client.sync_state();
Step 2: Identifying consumable notes
Once Alice has minted a note from the faucet, she will eventually want to spend the tokens that she received in the note created by the mint transaction.
Minting a note from a faucet on Miden means a faucet account creates a new note targeted to the requesting account. The requesting account must consume this note for the assets to appear in their account.
To identify notes that are ready to consume, the Miden WebClient has a useful function get_consumable_notes. It is also important to sync the state of the client before calling the get_consumable_notes function.
Tip: If you know the expected number of notes after a transaction, use await or a loop condition to verify their availability before calling get_consumable_notes. This prevents unnecessary application idling.
Identifying which notes are available:
consumable_notes = await client.get_consumable_notes(accountId);
Step 3: Consuming multiple notes in a single transaction:
Now that we know how to identify notes ready to consume, let's consume the notes created by the faucet in a single transaction. After consuming the notes, Alice's wallet balance will be updated.
The following code snippet identifies and consumes notes in a single transaction.
Add this snippet to the end of the webClient function in the src/webClient.ts file:
await client.fetch_and_cache_account_auth_by_pub_key(
AccountId.from_hex(aliceIdHex),
);
const mintedNotes = await client.get_consumable_notes(
AccountId.from_hex(aliceIdHex),
);
const mintedNoteIds = mintedNotes.map((n) =>
n.input_note_record().id().to_string(),
);
console.log("Minted note IDs:", mintedNoteIds);
console.log("Consuming minted notes...");
await client.new_consume_transaction(
AccountId.from_hex(aliceIdHex), // account id
mintedNoteIds, // array of note ids to consume
);
await client.sync_state();
console.log("Notes consumed.");
Step 4: Sending tokens to other accounts
After consuming the notes, Alice has tokens in her wallet. Now, she wants to send tokens to her friends. She has two options: create a separate transaction for each transfer or batch multiple notes in a single transaction.
The standard asset transfer note on Miden is the P2ID note (Pay to Id). There is also the P2IDR (Pay to Id Reclaimable) variant which allows the creator of the note to reclaim the note after a certain block height.
In our example, Alice will now send 50 tokens to a different account.
Basic P2ID transfer
Now as an example, Alice will send some tokens to an account in a single transaction.
Add this snippet to the end of your file in the main() function:
// send single P2ID note
const dummyIdHex = "0x599a54603f0cf9000000ed7a11e379";
console.log("Sending tokens to dummy account...");
await client.new_send_transaction(
AccountId.from_hex(aliceIdHex), // sender account id
AccountId.from_hex(dummyIdHex), // receiver account id
AccountId.from_hex(faucetIdHex), // faucet account id
NoteType.public(), // note type
BigInt(100), // amount
);
await client.sync_state();
Summary
Your src/webClient.ts function should now look like this:
import {
WebClient,
AccountStorageMode,
AccountId,
NoteType,
} from "@demox-labs/miden-sdk";
const nodeEndpoint = "https://rpc.testnet.miden.io:443";
export async function webClient(): Promise<void> {
try {
// 1. Create client
const client = await WebClient.create_client(nodeEndpoint);
// 2. Sync and log block
const state = await client.sync_state();
console.log("Latest block number:", state.block_num());
// 3. Create Alice account (public, updatable)
console.log("Creating account for Alice");
const aliceAccount = await client.new_wallet(
AccountStorageMode.public(), // account type
true // mutability
);
const aliceIdHex = aliceAccount.id().to_string();
console.log("Alice's account ID:", aliceIdHex);
// 4. Create faucet
console.log("Creating faucet...");
const faucetAccount = await client.new_faucet(
AccountStorageMode.public(), // account type
false, // fungible
"MID", // symbol
8, // decimals
BigInt(1_000_000) // max supply
);
const faucetIdHex = faucetAccount.id().to_string();
console.log("Faucet account ID:", faucetIdHex);
// 5. Mint tokens to Alice
await client.fetch_and_cache_account_auth_by_pub_key(
AccountId.from_hex(faucetIdHex),
);
await client.sync_state();
console.log("Minting tokens to Alice...");
await client.new_mint_transaction(
AccountId.from_hex(aliceIdHex), // target wallet id
AccountId.from_hex(faucetIdHex), // faucet id
NoteType.public(), // note type
BigInt(1000), // amount
);
console.log("Waiting 15 seconds for transaction confirmation...");
await new Promise((resolve) => setTimeout(resolve, 15000));
await client.sync_state();
// 6. Fetch minted notes
await client.fetch_and_cache_account_auth_by_pub_key(
AccountId.from_hex(aliceIdHex),
);
const mintedNotes = await client.get_consumable_notes(
AccountId.from_hex(aliceIdHex),
);
const mintedNoteIds = mintedNotes.map((n) =>
n.input_note_record().id().to_string(),
);
console.log("Minted note IDs:", mintedNoteIds);
// 7. Consume minted notes
console.log("Consuming minted notes...");
await client.new_consume_transaction(
AccountId.from_hex(aliceIdHex), // account id
mintedNoteIds, // array of note ids to consume
);
await client.sync_state();
console.log("Notes consumed.");
// 8. Send tokens to a dummy account
const dummyIdHex = "0x599a54603f0cf9000000ed7a11e379";
console.log("Sending tokens to dummy account...");
await client.new_send_transaction(
AccountId.from_hex(aliceIdHex), // sender account id
AccountId.from_hex(dummyIdHex), // receiver account id
AccountId.from_hex(faucetIdHex), // faucet account id
NoteType.public(), // note type
BigInt(100), // amount
);
await client.sync_state();
console.log("Tokens sent.");
} catch (error) {
console.error("Error:", error);
throw error;
}
}
Let's run the src/webClient.ts function again. Reload the page and click "Start WebClient".
Note: Currently there is a minor bug in the WebClient that produces a warning message, "Error inserting code with root" when creating multiple accounts. This is currently being fixed.
The output will look like this:
Latest block number: 4807
Alice's account ID: 0x1a20f4d1321e681000005020e69b1a
Creating faucet...
Faucet account ID: 0xaa86a6f05ae40b2000000f26054d5d
Minting tokens to Alice...
Waiting 15 seconds for transaction confirmation...
Minted note IDs: ['0x4edbb3d5dbdf6944f229a4711533114e0602ad48b70cda400993925c61f5bfaa']
Consuming minted notes...
Notes consumed.
Sending tokens to dummy account...
Tokens sent.
Resetting the MidenClientDB
The Miden webclient stores account and note data in the browser. To clear the account and node data in the browser, paste this code snippet into the browser console:
(async () => {
const dbs = await indexedDB.databases(); // Get all database names
for (const db of dbs) {
await indexedDB.deleteDatabase(db.name);
console.log(`Deleted database: ${db.name}`);
}
console.log("All databases deleted.");
})();
Running the example
To run a full working example navigate to the web-client directory in the miden-tutorials repository and run the web application example:
cd web-client
pnpm i
pnpm run dev
Overview
Components
The Miden client currently has two main components:
Miden client library
The Miden client library is a Rust library that can be integrated into projects, allowing developers to interact with the Miden rollup.
The library provides a set of APIs and functions for executing transactions, generating proofs, and managing activity on the Miden network.
Miden client CLI
The Miden client also includes a command-line interface (CLI) that serves as a wrapper around the library, exposing its basic functionality in a user-friendly manner.
The CLI provides commands for interacting with the Miden rollup, such as submitting transactions, syncing with the network, and managing account data.
Software prerequisites
- Rust installation minimum version 1.85.
Install the client
We currently recommend installing and running the client with the concurrent feature.
Run the following command to install the miden-client:
cargo install miden-cli --features concurrent
This installs the miden binary (at ~/.cargo/bin/miden) with the concurrent feature.
Concurrent feature
The concurrent flag enables optimizations that result in faster transaction execution and proving times.
Run the client
-
Make sure you have already installed the client. If you don't have a
miden-client.tomlfile in your directory, create one or runmiden initto initialize one at the current working directory. You can do so without any arguments to use its defaults or define either the RPC endpoint or the store config via--networkand--store-path -
Run the client CLI using:
miden
This section shows you how to get started with Miden by generating a new Miden account, requesting funds from a public faucet, consuming private notes, and creating public pay-to-id-notes.
By the end of this tutorial, you will have:
- Configured the Miden client.
- Connected to a Miden node.
- Created an account and requested funds from the faucet.
- Transferred assets between accounts by creating and consuming notes.
Prerequisites
Rust
Download from the Rust website.
In this section, we show you how to create a new local Miden account and how to receive funds from the public Miden faucet website.
Configure the Miden client
The Miden client facilitates interaction with the Miden rollup and provides a way to execute and prove transactions.
Tip Check the Miden client documentation for more information.
-
If you haven't already done so as part of another tutorial, open your terminal and create a new directory to store the Miden client.
mkdir miden-client cd miden-client -
Install the Miden client.
cargo install miden-cli --features concurrentYou can now use the
miden --versioncommand, and you should seeMiden 0.8.0. -
Initialize the client. This creates the
miden-client.tomlfile.miden init --network testnet # Creates a miden-client.toml configured with the testnet node's IP
Create a new Miden account
-
Create a new account of type
mutableusing the following command:miden new-wallet --mutable -
List all created accounts by running the following command:
miden account -lYou should see something like this:

Save the account ID for a future step.
Request tokens from the public faucet
-
To request funds from the faucet navigate to the following website: Miden faucet website.
-
Copy the Account ID printed by the
miden account -lcommand in the previous step. Feel free to change the amount of tokens to issue. -
Paste this ID into the Request test tokens input field on the faucet website and click Send Private Note.
Tip You can also click Send Public Note. If you do this, the note's details will be public and you will not need to download and import it, so you can skip to Sync the client.
-
After a few seconds your browser should download - or prompt you to download - a file called
note.mno(mno = Miden note). It contains the funds the faucet sent to your address. -
Save this file on your computer, you will need it for the next step.
Import the note into the Miden client
-
Import the private note that you have received using the following commands:
miden import <path-to-note>/note.mno -
You should see something like this:
Successfully imported note 0x0ff340133840d35e95e0dc2e62c88ed75ab2e383dc6673ce0341bd486fed8cb6 -
Now that the note has been successfully imported, you can view the note's information using the following command:
miden notes -
You should see something like this:

Tip: The importance of syncing
- As you can see, the note is listed as
Expected.- This is because you have received a private note but have not yet synced your view of the rollup to check that the note is the result of a valid transaction.
- Hence, before consuming the note we will need to update our view of the rollup by syncing.
- Many users could have received the same private note, but only one user can consume the note in a transaction that gets verified by the Miden operator.
Sync the client
Do this periodically to keep informed about any updates on the node by running the sync command:
miden sync
You will see something like this as output:
State synced to block 179672
New public notes: 0
Tracked notes updated: 1
Tracked notes consumed: 0
Tracked accounts updated: 0
Commited transactions: 0
Consume the note & receive the funds
-
Now that we have synced the client, the input-note imported from the faucet should have a
Committedstatus, confirming it exists at the rollup level:miden notes -
You should see something like this:

-
Find your account and note id by listing both
accountsandnotes:miden account miden notes -
Consume the note and add the funds from its vault to our account using the following command:
miden consume-notes --account <Account-Id> <Note-Id> -
You should see a confirmation message like this:
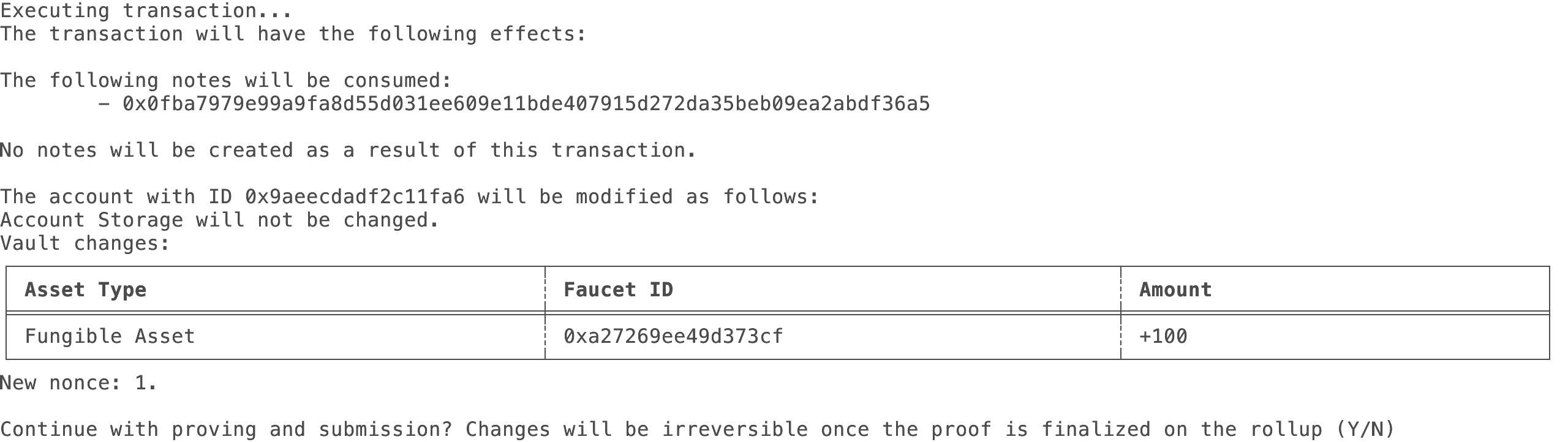
-
After confirming you can view the new note status by running the following command:
miden notes -
You should see something like this:

-
The note is
Processing. This means that the proof of the transaction was sent, but there is no network confirmation yet. You can update your view of the rollup by syncing again:miden sync -
After syncing, you should have received confirmation of the consumed note. You should see the note as
Consumedafter listing the notes:miden notes
Amazing! You just have created a client-side zero-knowledge proof locally on your machine and submitted it to the Miden rollup.
Tip You only need to copy the top line of characters of the Note ID.
View confirmations
-
View your updated account's vault containing the tokens sent by the faucet by running the following command:
miden account --show <Account-Id> -
You should now see your accounts vault containing the funds sent by the faucet.
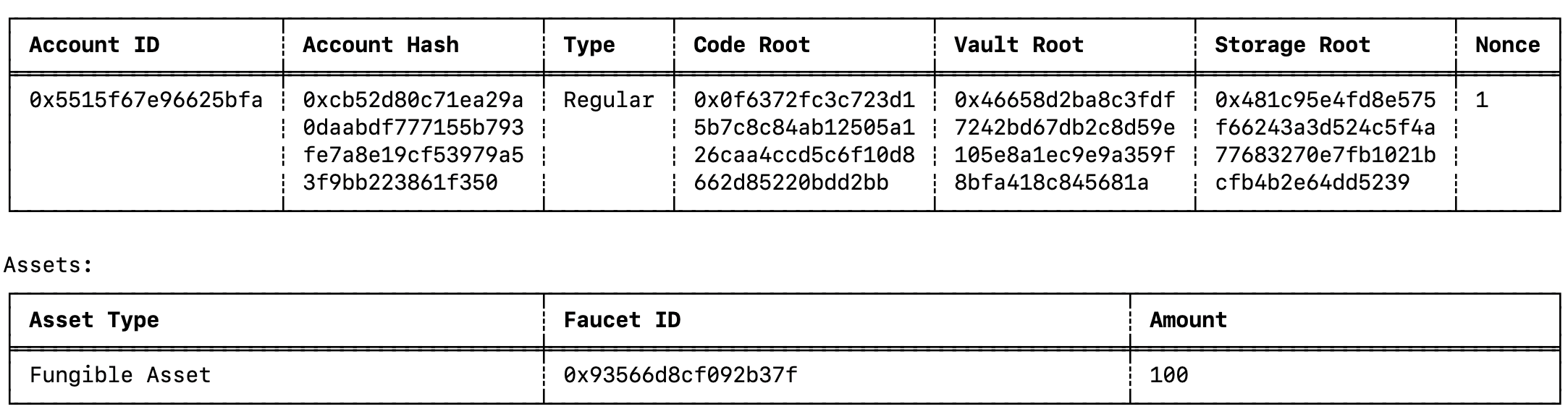
Congratulations!
You have successfully configured and used the Miden client to interact with a Miden rollup and faucet.
You have performed basic Miden rollup operations like submitting proofs of transactions, generating and consuming notes.
For more information on the Miden client, refer to the Miden client documentation.
Debugging tips (clear state and folder)
-
Need a fresh start? All state is maintained in
store.sqlite3, located in the directory defined in themiden-client.tomlfile. If you want to clear all state, delete this file. It recreates on any command execution. -
Getting an error? Only execute the
miden-clientcommand in the folder where yourmiden-client.tomlis located.
In this section, we show you how to execute transactions and send funds to another account using the Miden client and public notes.
Important: Prerequisite steps
- You should have already followed the prerequisite steps and get started documents.
- You should have not reset the state of your local client.
Create a second client
Tip Remember to use the Miden client documentation for clarifications.
This is an alternative to the private P2P transactions process.
In this tutorial, we use two different clients to simulate two different remote users who don't share local state.
To do this, we use two terminals with their own state (using their own miden-client.toml).
-
Create a new directory to store the new client.
mkdir miden-client-2 cd miden-client-2 -
Initialize the client. This creates the
miden-client.tomlfile line-by-line.miden init --network testnet # Creates a miden-client.toml file configured with the testnet node's IP -
On the new client, create a new basic account:
miden new-wallet --mutable -s publicWe refer to this account as Account C. Note that we set the account's storage mode to
public, which means that the account details are public and its latest state can be retrieved from the node. -
List and view the account with the following command:
miden account -l
Transfer assets between accounts
-
Now we can transfer some of the tokens we received from the faucet to our new account C. Remember to switch back to
miden-clientdirectory, since you'll be making the txn from Account ID A.To do this, from the first client run:
miden send --sender <basic-account-id-A> --target <basic-account-id-C> --asset 50::<faucet-account-id> --note-type publicNote The faucet account id is
0xad904b3138d71d3eand can also be found on the Miden faucet website under the title Miden faucet.This generates a Pay-to-ID (
P2ID) note containing50tokens, transferred from one account to the other. As the note is public, the second account can receive the necessary details by syncing with the node. -
First, sync the account on the new client.
miden sync -
At this point, we should have received the public note details.
miden notes --listBecause the note was retrieved from the node, the commit height will be included and displayed.
-
Have account C consume the note.
miden consume-notes --account <regular-account-ID-C> <input-note-id>Tip It's possible to use a short version of the note id: 7 characters after the
0xis sufficient, e.g.0x6ae613a.
That's it!
Account C has now consumed the note and there should be new assets in the account:
miden account --show <account-ID>
Clear state
All state is maintained in store.sqlite3, located in the directory defined in the miden-client.toml file.
To clear all state, delete this file. It recreates on any command execution.
In this section, we show you how to make private transactions and send funds to another account using the Miden client.
Important: Prerequisite steps
- You should have already followed the prerequisite steps and get started documents.
- You should not have reset the state of your local client.
Create a second account
Tip Remember to use the Miden client documentation for clarifications.
-
Create a second account to send funds with. Previously, we created a type
mutableaccount (account A). Now, create anothermutable(account B) using the following command:miden new-wallet --mutable -
List and view the newly created accounts with the following command:
miden account -l -
You should see two accounts:

Transfer assets between accounts
-
Now we can transfer some of the tokens we received from the faucet to our second account B.
To do this, run:
miden send --sender <regular-account-id-A> --target <regular-account-id-B> --asset 50::<faucet-account-id> --note-type privateNote The faucet account id can be found on the Miden faucet website under the title Miden faucet.
This generates a private Pay-to-ID (
P2ID) note containing50assets, transferred from one account to the other. -
First, sync the accounts.
miden sync -
Get the second note id.
miden notes -
Have the second account consume the note.
miden consume-notes --account <regular-account-ID-B> <input-note-id>Tip It's possible to use a short version of the note id: 7 characters after the
0xis sufficient, e.g.0x6ae613a.You should now see both accounts containing faucet assets with amounts transferred from
Account AtoAccount B. -
Check the second account:
miden account --show <regular-account-ID-B>
-
Check the original account:
miden account --show <regular-account-ID-A>
Wanna do more? Sending public notes
Congratulations!
You have successfully configured and used the Miden client to interact with a Miden rollup and faucet.
You have performed basic Miden rollup operations like submitting proofs of transactions, generating and consuming notes.
For more information on the Miden client, refer to the Miden client documentation.
Clear data
All state is maintained in store.sqlite3, located in the directory defined in the miden-client.toml file.
To clear all state, delete this file. It recreates on any command execution.
The Miden client offers a range of functionality for interacting with the Miden rollup.
Transaction execution
The Miden client facilitates the execution of transactions on the Miden rollup; allowing users to transfer assets, mint new tokens, and perform various other operations.
Proof generation
The Miden rollup supports user-generated proofs which are key to ensuring the validity of transactions on the Miden rollup.
To enable such proofs, the client contains the functionality for executing, proving, and submitting transactions.
Miden network interactivity
The Miden client enables users to interact with the Miden network. This includes syncing with the latest blockchain data and managing account information.
Account generation and tracking
The Miden client provides features for generating and tracking accounts within the Miden rollup ecosystem. Users can create accounts and track their transaction status.
The Miden client has the following architectural components:
tip
- The RPC client and the store are Rust traits.
- This allow developers and users to easily customize their implementations.
Store
The store is central to the client's design.
It manages the persistence of the following entities:
- Accounts; including their state history and related information such as vault assets and account code.
- Transactions and their scripts.
- Notes.
- Note tags.
- Block headers and chain information that the client needs to execute transactions and consume notes.
Because Miden allows off-chain executing and proving, the client needs to know about the state of the blockchain at the moment of execution. To avoid state bloat, however, the client does not need to see the whole blockchain history, just the chain history intervals that are relevant to the user.
The store can track any number of accounts, and any number of notes that those accounts might have created or may want to consume.
RPC client
The RPC client communicates with the node through a defined set of gRPC methods.
Currently, these include:
GetBlockHeaderByNumber: Returns the block header information given a specific block number.SyncState: Asks the node for information relevant to the client. For example, specific account changes, whether relevant notes have been created or consumed, etc.SubmitProvenTransaction: Sends a locally-proved transaction to the node for inclusion in the blockchain.
Transaction executor
The transaction executor executes transactions using the Miden VM.
When executing, the executor needs access to relevant blockchain history. The executor uses a DataStore interface for accessing this data. This means that there may be some coupling between the executor and the store.
To use the Miden client library in a Rust project, include it as a dependency.
In your project's Cargo.toml, add:
miden-client = { version = "0.8" }
Features
The Miden client library supports the concurrent feature which is recommended for developing applications with the client. To use it, add the following to your project's Cargo.toml:
miden-client = { version = "0.8", features = ["concurrent"] }
The library also supports several other features. Please refer to the crate's documentation to learn more.
Client instantiation
Spin up a client using the following Rust code and supplying a store and RPC endpoint.
Create local account
With the Miden client, you can create and track any number of public and local accounts. For local accounts, the state is tracked locally, and the rollup only keeps commitments to the data, which in turn guarantees privacy.
The AccountBuilder can be used to create a new account with the specified parameters and components. The following code creates a new local account:
Once an account is created, it is kept locally and its state is automatically tracked by the client.
To create an public account, you can specify AccountStorageMode::Public like so:
let key_pair = SecretKey::with_rng(client.rng());
let anchor_block = client.get_latest_epoch_block().await.unwrap();
let (new_account, seed) = AccountBuilder::new(init_seed) // Seed should be random for each account
.anchor((&anchor_block).try_into().unwrap())
.account_type(AccountType::RegularAccountImmutableCode)
.storage_mode(AccountStorageMode::Public)
.with_component(RpoFalcon512::new(key_pair.public_key()))
.with_component(BasicWallet)
.build()?;
client.add_account(&new_account, Some(seed), &AuthSecretKey::RpoFalcon512(key_pair), false).await?;
The account's state is also tracked locally, but during sync the client updates the account state by querying the node for the most recent account data.
Execute transaction
In order to execute a transaction, you first need to define which type of transaction is to be executed. This may be done with the TransactionRequest which represents a general definition of a transaction. Some standardized constructors are available for common transaction types.
Here is an example for a pay-to-id transaction type:
You can decide whether you want the note details to be public or private through the note_type parameter.
You may also execute a transaction by manually defining a TransactionRequest instance. This allows you to run custom code, with custom note arguments as well.
The following document lists the commands that the CLI currently supports.
tip
Use --help as a flag on any command for more information.
Usage
Call a command on the miden-client like this:
miden <command> <flags> <arguments>
Optionally, you can include the --debug flag to run the command with debug mode, which enables debug output logs from scripts that were compiled in this mode:
miden --debug <flags> <arguments>
Note that the debug flag overrides the MIDEN_DEBUG environment variable.
Commands
init
Creates a configuration file for the client in the current directory.
# This will create a config file named `miden-client.toml` using default values
# This file contains information useful for the CLI like the RPC provider and database path
miden init
# You can set up the CLI for any of the default networks
miden init --network testnet # This is the default value if no network is provided
miden init --network devnet
miden init --network localhost
# You can use the --network flag to override the default RPC config
miden init --network 18.203.155.106
# You can specify the port
miden init --network 18.203.155.106:8080
# You can also specify the protocol (http/https)
miden init --network https://18.203.155.106
# You can specify both
miden init --network https://18.203.155.106:1234
# You can use the --store_path flag to override the default store config
miden init --store_path db/store.sqlite3
# You can provide both flags
miden init --network 18.203.155.106 --store_path db/store.sqlite3
account
Inspect account details.
Action Flags
| Flags | Description | Short Flag |
|---|---|---|
--list | List all accounts monitored by this client | -l |
--show <ID> | Show details of the account for the specified ID | -s |
--default <ID> | Manage the setting for the default account | -d |
The --show flag also accepts a partial ID instead of the full ID. For example, instead of:
miden account --show 0x8fd4b86a6387f8d8
You can call:
miden account --show 0x8fd4b86
For the --default flag, if <ID> is "none" then the previous default account is cleared. If no <ID> is specified then the default account is shown.
new-wallet
Creates a new wallet account.
A basic wallet is comprised of a basic authentication component (for RPO Falcon signature verification), alongside a basic wallet component (for sending and receiving assets).
This command has three optional flags:
--storage-mode <TYPE>: Used to select the storage mode of the account (private if not specified). It may receive "private" or "public".--mutable: Makes the account code mutable (it's immutable by default).--extra-components <TEMPLATE_FILES_LIST>: Allows to pass a list of account component template files which can be added to the account. If the templates contain placeholders, the CLI will prompt the user to enter the required data for instantiating storage appropriately.
After creating an account with the new-wallet command, it is automatically stored and tracked by the client. This means the client can execute transactions that modify the state of accounts and track related changes by synchronizing with the Miden network.
new-account
Creates a new account and saves it locally.
An account may be composed of one or more components, each with its own storage and distinct functionality. This command lets you build a custom account by selecting an account type and optionally adding extra component templates.
This command has four flags:
--storage-mode <STORAGE_MODE>: Specifies the storage mode of the account. It accepts either "private" or "public", with "private" as the default.--account-type <ACCOUNT_TYPE>: Specifies the type of account to create. Accepted values are:fungible-faucetnon-fungible-faucetregular-account-immutable-coderegular-account-updatable-code
--component-templates <COMPONENT_TEMPLATES>: Allows you to provide a list of file paths for account component template files to include in the account. These components are looked up from your configuredcomponent_template_directoryfield inmiden-client.toml.--init-storage-data-path <INIT_STORAGE_DATA_PATH>: Specifies an optional file path to a TOML file containing key/value pairs used for initializing storage. Each key should map to a placeholder within the provided component templates. The CLI will prompt for any keys that are not present in the file.
After creating an account with the new-account command, the account is stored locally and tracked by the client, enabling it to execute transactions and synchronize state changes with the Miden network.
Examples
# Create a new wallet with default settings (private storage, immutable, no extra components)
miden new-wallet
# Create a new wallet with public storage and a mutable code
miden new-wallet --storage-mode public --mutable
# Create a new wallet that includes extra components from local templates
miden new-wallet --extra-components template1,template2
# Create a fungible faucet with interactive input
miden new-account --account-type fungible-faucet -c basic-fungible-faucet
# Create a fungible faucet with preset fields
miden new-account --account-type fungible-faucet --component-templates basic-fungible-faucet --init-storage-data-path init_data.toml
info
View a summary of the current client state.
notes
View and manage notes.
Action Flags
| Flags | Description | Short Flag |
|---|---|---|
--list [<filter>] | List input notes | -l |
--show <ID> | Show details of the input note for the specified note ID | -s |
The --list flag receives an optional filter:
- expected: Only lists expected notes.
- committed: Only lists committed notes.
- consumed: Only lists consumed notes.
- processing: Only lists processing notes.
- consumable: Only lists consumable notes. An additional --account-id <ID> flag may be added to only show notes consumable by the specified account.
If no filter is specified then all notes are listed.
The --show flag also accepts a partial ID instead of the full ID. For example, instead of:
miden notes --show 0x70b7ecba1db44c3aa75e87a3394de95463cc094d7794b706e02a9228342faeb0
You can call:
miden notes --show 0x70b7ec
sync
Sync the client with the latest state of the Miden network. Shows a brief summary at the end.
tags
View and add tags.
Action Flags
| Flag | Description | Aliases |
|---|---|---|
--list | List all tags monitored by this client | -l |
--add <tag> | Add a new tag to the list of tags monitored by this client | -a |
--remove <tag> | Remove a tag from the list of tags monitored by this client | -r |
tx
View transactions.
Action Flags
| Command | Description | Aliases |
|---|---|---|
--list | List tracked transactions | -l |
After a transaction gets executed, two entities start being tracked:
- The transaction itself: It follows a lifecycle from
Pending(initial state) andCommitted(after the node receives it). It may also beDiscardedif the transaction was not included in a block. - Output notes that might have been created as part of the transaction (for example, when executing a pay-to-id transaction).
Transaction creation commands
mint
Creates a note that contains a specific amount tokens minted by a faucet, that the target Account ID can consume.
Usage: miden mint --target <TARGET ACCOUNT ID> --asset <AMOUNT>::<FAUCET ID> --note-type <NOTE_TYPE>
consume-notes
Account ID consumes a list of notes, specified by their Note ID.
Usage: miden consume-notes --account <ACCOUNT ID> [NOTES]
For this command, you can also provide a partial ID instead of the full ID for each note. So instead of
miden consume-notes --account <some-account-id> 0x70b7ecba1db44c3aa75e87a3394de95463cc094d7794b706e02a9228342faeb0 0x80b7ecba1db44c3aa75e87a3394de95463cc094d7794b706e02a9228342faeb0
You can do:
miden consume-notes --account <some-account-id> 0x70b7ecb 0x80b7ecb
Additionally, you can optionally not specify note IDs, in which case any note that is known to be consumable by the executor account ID will be consumed.
Either Expected or Committed notes may be consumed by this command, changing their state to Processing. It's state will be updated to Consumed after the next sync.
send
Sends assets to another account. Sender Account creates a note that a target Account ID can consume. The asset is identified by the tuple (FAUCET ID, AMOUNT). The note can be configured to be recallable making the sender able to consume it after a height is reached.
Usage: miden send --sender <SENDER ACCOUNT ID> --target <TARGET ACCOUNT ID> --asset <AMOUNT>::<FAUCET ID> --note-type <NOTE_TYPE> <RECALL_HEIGHT>
swap
The source account creates a SWAP note that offers some asset in exchange for some other asset. When another account consumes that note, it will receive the offered asset amount and the requested asset will removed from its vault (and put into a new note which the first account can then consume). Consuming the note will fail if the account doesn't have enough of the requested asset.
Usage: miden swap --source <SOURCE ACCOUNT ID> --offered-asset <OFFERED AMOUNT>::<OFFERED FAUCET ID> --requested-asset <REQUESTED AMOUNT>::<REQUESTED FAUCET ID> --note-type <NOTE_TYPE>
Tips
For send and consume-notes, you can omit the --sender and --account flags to use the default account defined in the config. If you omit the flag but have no default account defined in the config, you'll get an error instead.
For every command which needs an account ID (either wallet or faucet), you can also provide a partial ID instead of the full ID for each account. So instead of
miden send --sender 0x80519a1c5e3680fc --target 0x8fd4b86a6387f8d8 --asset 100::0xa99c5c8764d4e011
You can do:
miden send --sender 0x80519 --target 0x8fd4b --asset 100::0xa99c5c8764d4e011
!!! note The only exception is for using IDs as part of the asset, those should have the full faucet's account ID.
Transaction confirmation
When creating a new transaction, a summary of the transaction updates will be shown and confirmation for those updates will be prompted:
miden <tx command> ...
TX Summary:
...
Continue with proving and submission? Changes will be irreversible once the proof is finalized on the rollup (Y/N)
This confirmation can be skipped in non-interactive environments by providing the --force flag (miden send --force ...):
Importing and exporting
export
Export input note data to a binary file .
| Flag | Description | Aliases |
|---|---|---|
--filename <FILENAME> | Desired filename for the binary file. | -f |
--export-type <EXPORT_TYPE> | Exported note type. | -e |
Export type
The user needs to specify how the note should be exported via the --export-type flag. The following options are available:
id: Only the note ID is exported. When importing, if the note ID is already tracked by the client, the note will be updated with missing information fetched from the node. This works for both public and private notes. If the note isn't tracked and the note is public, the whole note is fetched from the node and is stored for later use.full: The note is exported with all of its information (metadata and inclusion proof). When importing, the note is considered unverified. The note may not be consumed directly after importing as its block header will not be stored in the client. The block header will be fetched and be used to verify the note during the next sync. At this point the note will be committed and may be consumed.partial: The note is exported with minimal information and may be imported even if the note is not yet committed on chain. At the moment of importing the note, the client will check the state of the note by doing a note sync, using the note's tag. Depending on the response, the note will be either stored as "Expected" or "Committed".
import
Import entities managed by the client, such as accounts and notes. The type of entities is inferred.
Executing scripts
exec
Execute the specified program against the specified account.
| Flag | Description | Aliases |
|---|---|---|
--account <ACCOUNT_ID> | Account ID to use for the program execution. | -a |
--script-path <SCRIPT_PATH> | Path to script's source code to be executed. | -s |
--inputs-path <INPUTS_PATH> | Path to the inputs file. | -i |
--hex-words | Print the output stack grouped into words. |
After installation, use the client by running the following and adding the relevant commands:
miden
tip
Run miden --help for information on miden commands.
Client Configuration
We configure the client using a TOML file (miden-client.toml).
[rpc]
endpoint = { protocol = "http", host = "localhost", port = 57291 }
timeout_ms = 10000
[store]
database_filepath = "store.sqlite3"
[cli]
default_account_id = "0x012345678"
The TOML file should reside in same the directory from which you run the CLI.
In the configuration file, you will find a section for defining the node's rpc endpoint and timeout and the store's filename database_filepath.
By default, the node is set up to run on localhost:57291.
note
- Running the node locally for development is encouraged.
- However, the endpoint can point to any remote node.
There's an additional optional section used for CLI configuration. It currently contains the default account ID, which is used to execute transactions against it when the account flag is not provided.
By default none is set, but you can set and unset it with:
miden account --default <ACCOUNT_ID> #Sets default account
miden account --default none #Unsets default account
note
The account must be tracked by the client in order to be set as the default account.
You can also see the current default account ID with:
miden account --default
Environment variables
MIDEN_DEBUG: When set totrue, enables debug mode on the transaction executor and the script compiler. For any script that has been compiled and executed in this mode, debug logs will be output in order to facilitate MASM debugging (these instructions can be used to do so). This variable can be overridden by the--debugCLI flag.
note
For a complete example on how to run the client and submit transactions to the Miden node, refer to the Getting started documentation.
note
The latest and complete reference for the Miden client API can be found at Miden client docs.rs.
Introduction
Welcome to the Miden node documentation.
This book provides two separate guides aimed at node operators and developers looking to contribute to the node respectively. Each guide is standalone, but developers should also read through the operator guide as it provides some additional context.
At present, the Miden node is the central hub responsible for receiving user transactions and forming them into new blocks for a Miden network. As Miden decentralizes, the node will morph into the official reference implementation(s) of the various components required by a fully p2p network.
Each Miden network therefore has exactly one node receiving transactions and creating blocks. The node provides a gRPC interface for users, dApps, wallets and other clients to submit transactions and query the state.
Feedback
Please report any issues, ask questions or leave feedback in the node repository here.
This includes outdated, misleading, incorrect or just plain confusing information :)
Operator Guide
Welcome to the Miden node operator guide which should cover everything you need to succesfully run and maintain a
Miden node.
You can report any issues, ask questions or leave feedback at our project repo here.
Node architecture
The node itself consists of three distributed components: store, block-producer and RPC. We also provide a reference faucet implementation which we use to distribute testnet and devnet tokens.
The components can be run on separate instances when optimised for performance, but can also be run as a single process for convenience. At the moment both of Miden's public networks (testnet and devnet) are operating in single process mode.
The inter-component communication is done using a gRPC API wnich is assumed trusted. In other words this must not be public. External communication is handled by the RPC component with a separate external-only gRPC API.

RPC
The RPC component provides a public gRPC API with which users can submit transactions and query chain state. Queries are validated and then proxied to the store. Similarly, transaction proofs are verified before submitting them to the block-producer. This takes a non-trivial amount of load off the block-producer.
This is the only external facing component and it essentially acts as a shielding proxy that prevents bad requests from impacting block production.
It can be trivially scaled horizontally e.g. with a load-balancer in front as shown above.
Store
The store is responsible for persisting the chain state. It is effectively a database which holds the current state of the chain, wrapped in a gRPC interface which allows querying this state and submitting new blocks.
It expects that this gRPC interface is only accessible internally i.e. there is an implicit assumption of trust.
Block-producer
The block-producer is responsible for aggregating received transactions into blocks and submitting them to the store.
Transactions are placed in a mempool and are periodically sampled to form batches of transactions. These batches are proved, and then periodically aggregated into a block. This block is then proved and committed to the store.
Proof generation in production is typically outsourced to a remote machine with appropriate resources. For convenience, it is also possible to perform proving in-process. This is useful when running a local node for test purposes.
Faucet
A stand-alone binary which serves a webpage where users can request tokens from a customizable faucet account. The faucet communicates with the node via the RPC component and is not considered special by the node. It is a simple reference implementation of a faucet.
Installation
We provide Debian packages for official releases for both the node software as well as a reference faucet implementation.
Alternatively, both also can be installed from source on most systems using the Rust package manager cargo.
Debian package
Official Debian packages are available under our releases page.
Both amd64 and arm64 packages are available.
Note that the packages include a systemd service which is disabled by default.
To install, download the desired releases .deb package and checksum files. Install using
sudo dpkg -i $package_name.deb
You can (and should) verify the checksum prior to installation using a SHA256 utility. This differs from platform to platform, but on most linux distros:
sha256sum --check $checksum_file.deb.checksum
can be used so long as the checksum file and the package file are in the same folder.
Install using cargo
Install Rust version 1.85 or greater using the official Rust installation instructions.
Depending on the platform, you may need to install additional libraries. For example, on Ubuntu 22.04 the following command ensures that all required libraries are installed.
sudo apt install llvm clang bindgen pkg-config libssl-dev libsqlite3-dev
Install the latest node binary:
cargo install miden-node --locked
This will install the latest official version of the node. You can install a specific version x.y.z using
cargo install miden-node --locked --version x.y.z
You can also use cargo to compile the node from the source code if for some reason you need a specific git revision.
Note that since these aren't official releases we cannot provide much support for any issues you run into, so consider
this for advanced use only. The incantation is a little different as you'll be targeting our repo instead:
# Install from a specific branch
cargo install --locked --git https://github.com/0xPolygonMiden/miden-node miden-node --branch <branch>
# Install a specific tag
cargo install --locked --git https://github.com/0xPolygonMiden/miden-node miden-node --tag <tag>
# Install a specific git revision
cargo install --locked --git https://github.com/0xPolygonMiden/miden-node miden-node --rev <git-sha>
More information on the various cargo install options can be found
here.
Updating
warning
We currently have no backwards compatibility guarantees. This means updating your node is destructive - your existing chain will not work with the new version. This will change as our protocol and database schema mature and settle.
Updating the node to a new version is as simply as re-running the install process and repeating the Setup instructions.
Configuration and Usage
As outlined in the Architecture chapter, the node consists of several components which can be run separately or as a single bundled process. At present, the recommended way to operate a node is in bundled mode and is what this guide will focus on. Operating the components separately is very similar and should be relatively straight-foward to derive from these instructions.
This guide focusses on basic usage. To discover more advanced options we recommend exploring the various help menus
which can be accessed by appending --help to any of the commands.
Bootstrapping
The first step in starting a new Miden network is to initialize the genesis block data. This is a once-off operation.
# Write the default genesis configuration to a file.
#
# You can customize this file to add or remove accounts from the genesis block.
# By default this includes a single public faucet account.
#
# This can be skipped if using the default configuration.
miden-node store dump-genesis > genesis.toml
# Create a folder to store the node's data.
mkdir data
# Create a folder to store the genesis block's account secrets and data.
#
# These can be used to access the accounts afterwards.
# Without these the accounts would be inaccessible.
mkdir accounts
# Bootstrap the node.
#
# This generates the genesis data and stores it in `<data-directory>/genesis.dat`.
# This is used by the node to create and verify the database during node startup.
#
# Account secrets are stored as `<accounts-directory>/account_xx.mac`
# where `xx` is the index of the account in the configuration file.
#
# These account files are not used by the node and should instead be used wherever
# you intend to operate these accounts,
# e.g. to run the `miden-faucet` (see Faucet section).
miden-node bundled bootstrap \
--data-directory data \
--accounts-directory accounts \
--config genesis.toml # This can be omitted to use the default config.
Operation
Start the node with the desired public gRPC server address.
miden-node bundled start \
--data-directory data \
--rpc.url http://0.0.0.0:57123
Faucet
We also provide a reference implementation for a public faucet app with a basic webinterface to request tokens. The app requires a faucet account file which it can either generate (for a new account), or it can use an existing one e.g. one created as part of the genesis block.
Create a faucet account for the faucet app to use - or skip this step if you already have an account file.
mkdir accounts
miden-faucet create-faucet-account \
--token-symbol MY_TOKEN \
--decimals 12 \
--max-supply 5000
Create a configuration file for the faucet.
# This generates `miden-faucet.toml` which is used to configure the faucet.
#
# You can inspect and modify this if you want to make changes, e.g. to the website url.
miden-faucet init \
--config-path miden-faucet.toml \
--faucet-account-path accounts/account_0.mac # Filename may be different if you created a new account.
Run the faucet:
miden-faucet --config miden-faucet.toml
Systemd
Our Debian packages install a systemd service which operates the node in bundled
mode. You'll still need to run the bootstrapping process before the node can be started.
You can inspect the service file with systemctl cat miden-node (and miden-faucet) or alternatively you can see it in
our repository in the packaging folder. For the bootstrapping process be sure to specify the data-directory as
expected by the systemd file. If you're operating a faucet from an account generated in the genesis block, then you'll
also want to specify the accounts directory as expected by the faucet service file. With the default unmodified service
files this would be:
miden-node bundled bootstrap \
--data-directory /opt/miden-node \
--accounts-directory /opt/miden-faucet
Environment variables
Most configuration options can also be configured using environment variables as an alternative to providing the values
via the command-line. This is useful for certain deployment options like docker or systemd, where they can be easier
to define or inject instead of changing the underlying command line options.
These are especially convenient where multiple different configuration profiles are used. Write the environment
variables to some specific profile.env file and load it as part of the node command:
source profile.env && miden-node <...>
This works well on Linux and MacOS, but Windows requires some additional scripting unfortunately.
Monitoring & telemetry
We provide logging to stdout and an optional OpenTelemetry exporter for our traces.
OpenTelemetry exporting can be enabled by specifying --enable-otel via the command-line or the
MIDEN_NODE_ENABLE_OTEL environment variable when operating the node.
We do not export OpenTelemetry logs or metrics. Our end goal is to derive these based off of our tracing information. This approach is known as wide-events, structured logs, and Observibility 2.0.
What we're exporting are traces which consist of spans (covering a period of time), and events (something happened
at a specific instance in time). These are extremely useful to debug distributed systems - even though miden is still
centralized, the node components are distributed.
OpenTelemetry provides a Span Metrics Converter which can be used to convert our traces into more conventional metrics.
What gets traced
We assign a unique trace (aka root span) to each RPC request, batch build, and block build process.
Span and attribute naming is unstable and should not be relied upon. This also means changes here will not be considered breaking, however we will do our best to document them.
RPC request/response
Not yet implemented.
Block building
This trace covers the building, proving and submission of a block.
Span tree
block_builder.build_block
┝━ block_builder.select_block
│ ┝━ mempool.lock
│ ┕━ mempool.select_block
┝━ block_builder.get_block_inputs
│ ┝━ block_builder.summarize_batches
│ ┕━ store.client.get_block_inputs
│ ┕━ store.rpc/GetBlockInputs
│ ┕━ store.server.get_block_inputs
│ ┝━ validate_nullifiers
│ ┝━ read_account_ids
│ ┝━ validate_notes
│ ┝━ select_block_header_by_block_num
│ ┝━ select_note_inclusion_proofs
│ ┕━ select_block_headers
┝━ block_builder.prove_block
│ ┝━ execute_program
│ ┕━ block_builder.simulate_proving
┝━ block_builder.inject_failure
┕━ block_builder.commit_block
┝━ store.client.apply_block
│ ┕━ store.rpc/ApplyBlock
│ ┕━ store.server.apply_block
│ ┕━ apply_block
│ ┝━ select_block_header_by_block_num
│ ┕━ update_in_memory_structs
┝━ mempool.lock
┕━ mempool.commit_block
┕━ mempool.revert_expired_transactions
┕━ mempool.revert_transactions
Batch building
This trace covers the building and proving of a batch.
Span tree
batch_builder.build_batch
┝━ batch_builder.wait_for_available_worker
┝━ batch_builder.select_batch
│ ┝━ mempool.lock
│ ┕━ mempool.select_batch
┝━ batch_builder.get_batch_inputs
│ ┕━ store.client.get_batch_inputs
┝━ batch_builder.propose_batch
┝━ batch_builder.prove_batch
┝━ batch_builder.inject_failure
┕━ batch_builder.commit_batch
┝━ mempool.lock
┕━ mempool.commit_batch
Verbosity
We log important spans and events at info level or higher, which is also the default log level.
Changing this level should rarely be required - let us know if you're missing information that should be at info.
The available log levels are trace, debug, info (default), warn, error which can be configured using the
RUST_LOG environment variable e.g.
export RUST_LOG=debug
The verbosity can also be specified by component (when running them as a single process):
export RUST_LOG=warn,block-producer=debug,rpc=error
The above would set the general level to warn, and the block-producer and rpc components would be overriden to
debug and error respectively. Though as mentioned, it should be unusual to do this.
Configuration
The OpenTelemetry trace exporter is enabled by adding the --open-telemetry flag to the node's start command:
miden-node start --open-telemetry node
The exporter can be configured using environment variables as specified in the official documents.
Note: we only support gRPC as the export protocol.
Example: Honeycomb configuration
This is based off Honeycomb's OpenTelemetry setup guide.
OTEL_EXPORTER_OTLP_ENDPOINT=https://api.honeycomb.io:443 \
OTEL_EXPORTER_OTLP_HEADERS="x-honeycomb-team=your-api-key" \
miden-node start --open-telemetry node
TODO: honeycomb queries, triggers and board examples.
Versioning
We follow the semver standard for versioning.
The following is considered the node's public API, and will therefore be considered as breaking changes.
- RPC gRPC specification (note that this excludes internal inter-component gRPC schemas).
- Node configuration options.
- Faucet configuration options.
- Database schema changes which cannot be reverted.
- Large protocol and behavioral changes.
We intend to include our OpenTelemetry trace specification in this once it stabilizes.
We will also call out non-breaking behvioral changes in our changelog and release notes.
gRPC Reference
This is a reference of the Node's public RPC interface. It consists of a gRPC API which may be used to submit transactions and query the state of the blockchain.
The gRPC service definition can be found in the Miden node's proto
directory in the rpc.proto file.
- CheckNullifiers
- CheckNullifiersByPrefix
- GetAccountDetails
- GetAccountProofs
- GetAccountStateDelta
- GetBlockByNumber
- GetBlockHeaderByNumber
- GetNotesById
- SubmitProvenTransaction
- SyncNotes
- SyncState
CheckNullifiers
Request proofs for a set of nullifiers.
CheckNullifiersByPrefix
Request nullifiers filtered by prefix and created after some block number.
The prefix is used to obscure the callers interest in a specific nullifier. Currently only 16-bit prefixes are supported.
GetAccountDetails
Request the latest state of an account.
GetAccountProofs
Request state proofs for accounts, including specific storage slots.
GetAccountStateDelta
Request the delta of an account's state for a range of blocks. This can be used to update your local account state to the latest network state.
GetBlockByNumber
Request the raw data for a specific block.
GetBlockHeaderByNumber
Request a specific block header and its inclusion proof.
GetNotesById
Request a set of notes.
SubmitProvenTransaction
Submit a transaction to the network.
SyncNotes
Iteratively sync data for a given set of note tags.
Client specify the note tags of interest and the block height from which to search. The response returns the next block containing note matching the provided tags.
The response includes each note's metadata and inclusion proof.
A basic note sync can be implemented by repeatedly requesting the previous response's block until reaching the tip of the chain.
SyncState
Iteratively sync data for specific notes and accounts.
This request returns the next block containing data of interest. number in the chain. Client is expected to repeat these requests in a loop until the reponse reaches the head of the chain, at which point the data is fully synced.
Each update response also contains info about new notes, accounts etc. created. It also returns Chain MMR delta that can be used to update the state of Chain MMR. This includes both chain MMR peaks and chain MMR nodes.
The low part of note tags are redacted to preserve some degree of privacy. Returned data therefore contains additional notes which should be filtered out by the client.
Introduction
Miden VM is a zero-knowledge virtual machine written in Rust. For any program executed on Miden VM, a STARK-based proof of execution is automatically generated. This proof can then be used by anyone to verify that the program was executed correctly without the need for re-executing the program or even knowing the contents of the program.
Status and features
Miden VM is currently on release v0.14. In this release, most of the core features of the VM have been stabilized, and most of the STARK proof generation has been implemented. While we expect to keep making changes to the VM internals, the external interfaces should remain relatively stable, and we will do our best to minimize the amount of breaking changes going forward.
At this point, Miden VM is good enough for experimentation, and even for real-world applications, but it is not yet ready for production use. The codebase has not been audited and contains known and unknown bugs and security flaws.
Feature highlights
Miden VM is a fully-featured virtual machine. Despite being optimized for zero-knowledge proof generation, it provides all the features one would expect from a regular VM. To highlight a few:
- Flow control. Miden VM is Turing-complete and supports familiar flow control structures such as conditional statements and counter/condition-controlled loops. There are no restrictions on the maximum number of loop iterations or the depth of control flow logic.
- Procedures. Miden assembly programs can be broken into subroutines called procedures. This improves code modularity and helps reduce the size of Miden VM programs.
- Execution contexts. Miden VM program execution can span multiple isolated contexts, each with its own dedicated memory space. The contexts are separated into the root context and user contexts. The root context can be accessed from user contexts via customizable kernel calls.
- Memory. Miden VM supports read-write random-access memory. Procedures can reserve portions of global memory for easier management of local variables.
- u32 operations. Miden VM supports native operations with 32-bit unsigned integers. This includes basic arithmetic, comparison, and bitwise operations.
- Cryptographic operations. Miden assembly provides built-in instructions for computing hashes and verifying Merkle paths. These instructions use Rescue Prime Optimized hash function (which is the native hash function of the VM).
- External libraries. Miden VM supports compiling programs against pre-defined libraries. The VM ships with one such library: Miden
stdlibwhich adds support for such things as 64-bit unsigned integers. Developers can build other similar libraries to extend the VM's functionality in ways which fit their use cases. - Nondeterminism. Unlike traditional virtual machines, Miden VM supports nondeterministic programming. This means a prover may do additional work outside of the VM and then provide execution hints to the VM. These hints can be used to dramatically speed up certain types of computations, as well as to supply secret inputs to the VM.
- Customizable hosts. Miden VM can be instantiated with user-defined hosts. These hosts are used to supply external data to the VM during execution/proof generation (via nondeterministic inputs) and can connect the VM to arbitrary data sources (e.g., a database or RPC calls).
Planned features
In the coming months we plan to finalize the design of the VM and implement support for the following features:
- Recursive proofs. Miden VM will soon be able to verify a proof of its own execution. This will enable infinitely recursive proofs, an extremely useful tool for real-world applications.
- Better debugging. Miden VM will provide a better debugging experience including the ability to place breakpoints, better source mapping, and more complete program analysis info.
- Faulty execution. Miden VM will support generating proofs for programs with faulty execution (a notoriously complex task in ZK context). That is, it will be possible to prove that execution of some program resulted in an error.
Structure of this document
This document is meant to provide an in-depth description of Miden VM. It is organized as follows:
- In the introduction, we provide a high-level overview of Miden VM and describe how to run simple programs.
- In the user documentation section, we provide developer-focused documentation useful to those who want to develop on Miden VM or build compilers from higher-level languages to Miden assembly (the native language of Miden VM).
- In the design section, we provide in-depth descriptions of the VM's internals, including all AIR constraints for the proving system. We also provide the rationale for settling on specific design choices.
- Finally, in the background material section, we provide references to materials which could be useful for learning more about STARKs - the proving system behind Miden VM.
License
Licensed under the MIT license.
Miden VM overview
Miden VM is a stack machine. The base data type of the MV is a field element in a 64-bit prime field defined by modulus . This means that all values that the VM operates with are field elements in this field (i.e., values between and , both inclusive).
Miden VM consists of four high-level components as illustrated below.
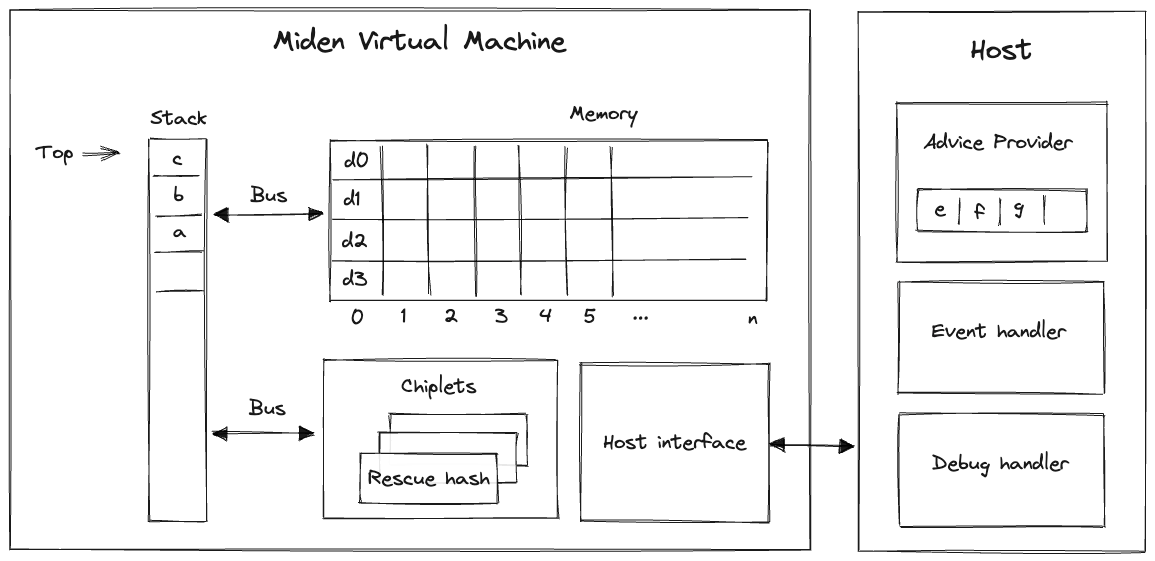
These components are:
- Stack which is a push-down stack where each item is a field element. Most assembly instructions operate with values located on the stack. The stack can grow up to items deep, however, only the top 16 items are directly accessible.
- Memory which is a linear random-access read-write memory. The memory is element-addressable, meaning, a single element is located at each address. However, there are instructions to read and write elements to/from memory both individually or in batches of four, since the latter is quite common. Memory addresses can be in the range .
- Chiplets which are specialized circuits for accelerating certain types of computations. These include Rescue Prime Optimized (RPO) hash function, 32-bit binary operations, and 16-bit range checks.
- Host which is a way for the prover to communicate with the VM during runtime. This includes responding to the VM's requests for non-deterministic inputs and handling messages sent by the VM (e.g., for debugging purposes). The requests for non-deterministic inputs are handled by the host's advice provider.
Miden VM comes with a default implementation of the host interface (with an in-memory advice provider). However, the users are able to provide their own implementations which can connect the VM to arbitrary data sources (e.g., a database or RPC calls) and define custom logic for handling events emitted by the VM.
Writing programs
Our goal is to make Miden VM an easy compilation target for high-level languages such as Rust, Move, Sway, and others. We believe it is important to let people write programs in the languages of their choice. However, compilers to help with this have not been developed yet. Thus, for now, the primary way to write programs for Miden VM is to use Miden assembly.
While writing programs in assembly is far from ideal, Miden assembly does make this task a little bit easier by supporting high-level flow control structures and named procedures.
Inputs and outputs
External inputs can be provided to Miden VM in two ways:
- Public inputs can be supplied to the VM by initializing the stack with desired values before a program starts executing. At most 16 values can be initialized in this way, so providing more than 16 values will cause an error.
- Secret (or nondeterministic) inputs can be supplied to the VM via the advice provider. There is no limit on how much data the advice provider can hold.
After a program finishes executing, the elements remaining on the stack become the outputs of the program. Notice that having more than 16 values on the stack at the end of execution will cause an error, so the values beyond the top 16 elements of the stack should be dropped. We've provided the truncate_stack utility procedure in the standard library for this purpose.
The number of public inputs and outputs of a program can be reduced by making use of the advice stack and Merkle trees. Just 4 elements are sufficient to represent a root of a Merkle tree, which can be expanded into an arbitrary number of values.
For example, if we wanted to provide a thousand public input values to the VM, we could put these values into a Merkle tree, initialize the stack with the root of this tree, initialize the advice provider with the tree itself, and then retrieve values from the tree during program execution using mtree_get instruction (described here).
Stack depth restrictions
For reasons explained here, the VM imposes the restriction that the stack depth cannot be smaller than . This has the following effects:
- When initializing a program with fewer than inputs, the VM will pad the stack with zeros to ensure the depth is at the beginning of execution.
- If an operation would result in the stack depth dropping below , the VM will insert a zero at the deep end of the stack to make sure the depth stays at .
Nondeterministic inputs
The advice provider component is responsible for supplying nondeterministic inputs to the VM. These inputs only need to be known to the prover (i.e., they do not need to be shared with the verifier).
The advice provider consists of three components:
- Advice stack which is a one-dimensional array of field elements. Being a stack, the VM can either push new elements onto the advice stack, or pop the elements from its top.
- Advice map which is a key-value map where keys are words and values are vectors of field elements. The VM can copy values from the advice map onto the advice stack as well as insert new values into the advice map (e.g., from a region of memory).
- Merkle store which contain structured data reducible to Merkle paths. Some examples of such structures are: Merkle tree, Sparse Merkle Tree, and a collection of Merkle paths. The VM can request Merkle paths from the Merkle store, as well as mutate it by updating or merging nodes contained in the store.
The prover initializes the advice provider prior to executing a program, and from that point on the advice provider is manipulated solely by executing operations on the VM.
Usage
Before you can use Miden VM, you'll need to make sure you have Rust installed. Miden VM v0.14 requires Rust version 1.85 or later.
Miden VM consists of several crates, each of which exposes a small set of functionality. The most notable of these crates are:
- miden-processor, which can be used to execute Miden VM programs.
- miden-prover, which can be used to execute Miden VM programs and generate proofs of their execution.
- miden-verifier, which can be used to verify proofs of program execution generated by Miden VM prover.
The above functionality is also exposed via the single miden-vm crate, which also provides a CLI interface for interacting with Miden VM.
CLI interface
Compiling Miden VM
To compile Miden VM into a binary, we have a Makefile with the following tasks:
make exec
This will place an optimized, multi-threaded miden executable into the ./target/optimized directory. It is equivalent to executing:
cargo build --profile optimized --features concurrent,executable
If you would like to enable single-threaded mode, you can compile Miden VM using the following command:
make exec-single
Controlling parallelism
Internally, Miden VM uses rayon for parallel computations. To control the number of threads used to generate a STARK proof, you can use RAYON_NUM_THREADS environment variable.
GPU acceleration
Miden VM proof generation can be accelerated via GPUs. Currently, GPU acceleration is enabled only on Apple Silicon hardware (via Metal). To compile Miden VM with Metal acceleration enabled, you can run the following command:
make exec-metal
Similar to make exec command, this will place the resulting miden executable into the ./target/optimized directory.
Currently, GPU acceleration is applicable only to recursive proofs which can be generated using the -r flag.
SIMD acceleration
Miden VM execution and proof generation can be accelerated via vectorized instructions. Currently, SIMD acceleration can be enabled on platforms supporting SVE and AVX2 instructions.
To compile Miden VM with AVX2 acceleration enabled, you can run the following command:
make exec-avx2
To compile Miden VM with SVE acceleration enabled, you can run the following command:
make exec-sve
This will place the resulting miden executable into the ./target/optimized directory.
Similar to Metal acceleration, SVE/AVX2 acceleration is currently applicable only to recursive proofs which can be generated using the -r flag.
Running Miden VM
Once the executable has been compiled, you can run Miden VM like so:
./target/optimized/miden [subcommand] [parameters]
Currently, Miden VM can be executed with the following subcommands:
run- this will execute a Miden assembly program and output the result, but will not generate a proof of execution.prove- this will execute a Miden assembly program, and will also generate a STARK proof of execution.verify- this will verify a previously generated proof of execution for a given program.compile- this will compile a Miden assembly program (i.e., build a program MAST) and outputs stats about the compilation process.debug- this will instantiate a Miden debugger against the specified Miden assembly program and inputs.analyze- this will run a Miden assembly program against specific inputs and will output stats about its execution.repl- this will initiate the Miden REPL tool.example- this will execute a Miden assembly example program, generate a STARK proof of execution and verify it. Currently, it is possible to runblake3andfibonacciexamples.
All of the above subcommands require various parameters to be provided. To get more detailed help on what is needed for a given subcommand, you can run the following:
./target/optimized/miden [subcommand] --help
For example:
./target/optimized/miden prove --help
To execute a program using the Miden VM there needs to be a .masm file containing the Miden Assembly code and a .inputs file containing the inputs.
Enabling logging
You can use MIDEN_LOG environment variable to control how much logging output the VM produces. For example:
MIDEN_LOG=trace ./target/optimized/miden [subcommand] [parameters]
If the level is not specified, warn level is set as default.
Enable Debugging features
You can use the run command with --debug parameter to enable debugging with the debug instruction such as debug.stack:
./target/optimized/miden run [path_to.masm] --debug
Inputs
As described here the Miden VM can consume public and secret inputs.
- Public inputs:
operand_stack- can be supplied to the VM to initialize the stack with the desired values before a program starts executing. If the number of provided input values is less than 16, the input stack will be padded with zeros to the length of 16. The maximum number of the stack inputs is limited by 16 values, providing more than 16 values will cause an error.
- Secret (or nondeterministic) inputs:
advice_stack- can be supplied to the VM. There is no limit on how much data the advice provider can hold. This is provided as a string array where each string entry represents a field element.advice_map- is supplied as a map of 64-character hex keys, each mapped to an array of numbers. The hex keys are interpreted as 4 field elements and the arrays of numbers are interpreted as arrays of field elements.merkle_store- the Merkle store is container that allows the user to definemerkle_tree,sparse_merkle_treeandpartial_merkle_treedata structures.merkle_tree- is supplied as an array of 64-character hex values where each value represents a leaf (4 elements) in the tree.sparse_merkle_tree- is supplied as an array of tuples of the form (number, 64-character hex string). The number represents the leaf index and the hex string represents the leaf value (4 elements).partial_merkle_tree- is supplied as an array of tuples of the form ((number, number), 64-character hex string). The internal tuple represents the leaf depth and index at this depth, and the hex string represents the leaf value (4 elements).
Check out the comparison example to see how secret inputs work.
After a program finishes executing, the elements that remain on the stack become the outputs of the program. Notice that the number of values on the operand stack at the end of the program execution can not be greater than 16, otherwise the program will return an error. The truncate_stack utility procedure from the standard library could be used to conveniently truncate the stack at the end of the program.
Fibonacci example
In the miden/masm-examples/fib directory, we provide a very simple Fibonacci calculator example. This example computes the 1001st term of the Fibonacci sequence. You can execute this example on Miden VM like so:
./target/optimized/miden run miden/masm-examples/fib/fib.masm
Capturing Output
This will run the example code to completion and will output the top element remaining on the stack.
If you want the output of the program in a file, you can use the --output or -o flag and specify the path to the output file. For example:
./target/optimized/miden run miden/masm-examples/fib/fib.masm -o fib.out
This will dump the output of the program into the fib.out file. The output file will contain the state of the stack at the end of the program execution.
Running with debug instruction enabled
Inside miden/masm-examples/fib/fib.masm, insert debug.stack instruction anywhere between begin and end. Then run:
./target/optimized/miden run miden/masm-examples/fib/fib.masm -n 1 --debug
You should see output similar to "Stack state before step ..."
Performance
The benchmarks below should be viewed only as a rough guide for expected future performance. The reasons for this are twofold:
- Not all constraints have been implemented yet, and we expect that there will be some slowdown once constraint evaluation is completed.
- Many optimizations have not been applied yet, and we expect that there will be some speedup once we dedicate some time to performance optimizations.
Overall, we don't expect the benchmarks to change significantly, but there will definitely be some deviation from the below numbers in the future.
A few general notes on performance:
- Execution time is dominated by proof generation time. In fact, the time needed to run the program is usually under 1% of the time needed to generate the proof.
- Proof verification time is really fast. In most cases it is under 1 ms, but sometimes gets as high as 2 ms or 3 ms.
- Proof generation process is dynamically adjustable. In general, there is a trade-off between execution time, proof size, and security level (i.e. for a given security level, we can reduce proof size by increasing execution time, up to a point).
- Both proof generation and proof verification times are greatly influenced by the hash function used in the STARK protocol. In the benchmarks below, we use BLAKE3, which is a really fast hash function.
Single-core prover performance
When executed on a single CPU core, the current version of Miden VM operates at around 20 - 25 KHz. In the benchmarks below, the VM executes a Fibonacci calculator program on Apple M1 Pro CPU in a single thread. The generated proofs have a target security level of 96 bits.
| VM cycles | Execution time | Proving time | RAM consumed | Proof size |
|---|---|---|---|---|
| 210 | 1 ms | 60 ms | 20 MB | 46 KB |
| 212 | 2 ms | 180 ms | 52 MB | 56 KB |
| 214 | 8 ms | 680 ms | 240 MB | 65 KB |
| 216 | 28 ms | 2.7 sec | 950 MB | 75 KB |
| 218 | 81 ms | 11.4 sec | 3.7 GB | 87 KB |
| 220 | 310 ms | 47.5 sec | 14 GB | 100 KB |
As can be seen from the above, proving time roughly doubles with every doubling in the number of cycles, but proof size grows much slower.
We can also generate proofs at a higher security level. The cost of doing so is roughly doubling of proving time and roughly 40% increase in proof size. In the benchmarks below, the same Fibonacci calculator program was executed on Apple M1 Pro CPU at 128-bit target security level:
| VM cycles | Execution time | Proving time | RAM consumed | Proof size |
|---|---|---|---|---|
| 210 | 1 ms | 120 ms | 30 MB | 61 KB |
| 212 | 2 ms | 460 ms | 106 MB | 77 KB |
| 214 | 8 ms | 1.4 sec | 500 MB | 90 KB |
| 216 | 27 ms | 4.9 sec | 2.0 GB | 103 KB |
| 218 | 81 ms | 20.1 sec | 8.0 GB | 121 KB |
| 220 | 310 ms | 90.3 sec | 20.0 GB | 138 KB |
Multi-core prover performance
STARK proof generation is massively parallelizable. Thus, by taking advantage of multiple CPU cores we can dramatically reduce proof generation time. For example, when executed on an 8-core CPU (Apple M1 Pro), the current version of Miden VM operates at around 100 KHz. And when executed on a 64-core CPU (Amazon Graviton 3), the VM operates at around 250 KHz.
In the benchmarks below, the VM executes the same Fibonacci calculator program for 220 cycles at 96-bit target security level:
| Machine | Execution time | Proving time | Execution % | Implied Frequency |
|---|---|---|---|---|
| Apple M1 Pro (16 threads) | 310 ms | 7.0 sec | 4.2% | 140 KHz |
| Apple M2 Max (16 threads) | 280 ms | 5.8 sec | 4.5% | 170 KHz |
| AMD Ryzen 9 5950X (16 threads) | 270 ms | 10.0 sec | 2.6% | 100 KHz |
| Amazon Graviton 3 (64 threads) | 330 ms | 3.6 sec | 8.5% | 265 KHz |
Recursive proofs
Proofs in the above benchmarks are generated using BLAKE3 hash function. While this hash function is very fast, it is not very efficient to execute in Miden VM. Thus, proofs generated using BLAKE3 are not well-suited for recursive proof verification. To support efficient recursive proofs, we need to use an arithmetization-friendly hash function. Miden VM natively supports Rescue Prime Optimized (RPO), which is one such hash function. One of the downsides of arithmetization-friendly hash functions is that they are considerably slower than regular hash functions.
In the benchmarks below we execute the same Fibonacci calculator program for 220 cycles at 96-bit target security level using RPO hash function instead of BLAKE3:
| Machine | Execution time | Proving time | Proving time (HW) |
|---|---|---|---|
| Apple M1 Pro (16 threads) | 310 ms | 94.3 sec | 42.0 sec |
| Apple M2 Max (16 threads) | 280 ms | 75.1 sec | 20.9 sec |
| AMD Ryzen 9 5950X (16 threads) | 270 ms | 59.3 sec | |
| Amazon Graviton 3 (64 threads) | 330 ms | 21.7 sec | 14.9 sec |
In the above, proof generation on some platforms can be hardware-accelerated. Specifically:
- On Apple M1/M2 platforms the built-in GPU is used for a part of proof generation process.
- On the Graviton platform, SVE vector extension is used to accelerate RPO computations.
Development Tools and Resources
The following tools are available for interacting with Miden VM:
- Via the miden-vm crate (or within the Miden VM repo):
- Via your browser:
- The interactive Miden VM Playground for writing, executing, proving, and verifying programs from your browser.
The following resources are available to help you get started programming with Miden VM more quickly:
- The Miden VM examples repo contains examples of programs written in Miden Assembly.
- Our Scaffolded repo can be cloned for starting a new Rust project using Miden VM.
Miden Debugger
The Miden debugger is a command-line interface (CLI) application, inspired by GNU gdb, which allows debugging of Miden assembly (MASM) programs. The debugger allows the user to step through the execution of the program, both forward and backward, either per clock cycle tick, or via breakpoints.
The Miden debugger supports the following commands:
| Command | Shortcut | Arguments | Description |
|---|---|---|---|
| next | n | count? | Steps count clock cycles. Will step 1 cycle of count is omitted. |
| continue | c | - | Executes the program until completion, failure or a breakpoint. |
| back | b | count? | Backward step count clock cycles. Will back-step 1 cycle of count is omitted. |
| rewind | r | - | Executes the program backwards until the beginning, failure or a breakpoint. |
| p | - | Displays the complete state of the virtual machine. | |
| print mem | p m | address? | Displays the memory value at address. If address is omitted, didisplays all the memory values. |
| print stack | p s | index? | Displays the stack value at index. If index is omitted, displays all the stack values. |
| clock | c | - | Displays the current clock cycle. |
| quit | q | - | Quits the debugger. |
| help | h | - | Displays the help message. |
In order to start debugging, the user should provide a MASM program:
cargo run --features executable -- debug --assembly miden/masm-examples/nprime/nprime.masm
The expected output is:
============================================================
Debug program
============================================================
Reading program file `miden/masm-examples/nprime/nprime.masm`
Compiling program... done (16 ms)
Debugging program with hash 11dbbddff27e26e48be3198133df8cbed6c5875d0fb
606c9f037c7893fde4118...
Reading input file `miden/masm-examples/nprime/nprime.inputs`
Welcome! Enter `h` for help.
>>
In order to add a breakpoint, the user should insert a breakpoint instruction into the MASM file. This will generate a Noop operation that will be decorated with the debug break configuration. This is a provisory solution until the source mapping is implemented.
The following example will halt on the third instruction of foo:
proc.foo
dup
dup.2
breakpoint
swap
add.1
end
begin
exec.foo
end
Miden REPL
The Miden Read–eval–print loop (REPL) is a Miden shell that allows for quick and easy debugging of Miden assembly. After the REPL gets initialized, you can execute any Miden instruction, undo executed instructions, check the state of the stack and memory at a given point, and do many other useful things! When the REPL is exited, a history.txt file is saved. One thing to note is that all the REPL native commands start with an ! to differentiate them from regular assembly instructions.
Miden REPL can be started via the CLI repl command like so:
./target/optimized/miden repl
It is also possible to initialize REPL with libraries. To create it with Miden standard library you need to specify -s or --stdlib subcommand, it is also possible to add a third-party library by specifying -l or --libraries subcommand with paths to .masl library files. For example:
./target/optimized/miden repl -s -l example/library.masl
Miden assembly instruction
All Miden instructions mentioned in the Miden Assembly sections are valid. One can either input instructions one by one or multiple instructions in one input.
For example, the below two commands will result in the same output.
>> push.1
>> push.2
>> push.3
push.1 push.2 push.3
To execute a control flow operation, one must write the entire statement in a single line with spaces between individual operations.
repeat.20
pow2
end
The above example should be written as follows in the REPL tool:
repeat.20 pow2 end
!help
The !help command prints out all the available commands in the REPL tool.
!program
The !program command prints out the entire Miden program being executed. E.g., in the below scenario:
>> push.1.2.3.4
>> repeat.16 pow2 end
>> u32wrapping_add
>> !program
begin
push.1.2.3.4
repeat.16 pow2 end
u32wrapping_add
end
!stack
The !stack command prints out the state of the stack at the last executed instruction. Since the stack always contains at least 16 elements, 16 or more elements will be printed out (even if all of them are zeros).
>> push.1 push.2 push.3 push.4 push.5
>> exp
>> u32wrapping_mul
>> swap
>> eq.2
>> assert
The !stack command will print out the following state of the stack:
>> !stack
3072 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
!mem
The !mem command prints out the contents of all initialized memory locations. For each such location, the address, along with its memory values, is printed. Recall that four elements are stored at each memory address.
If the memory has at least one value that has been initialized:
>> !mem
7: [1, 2, 0, 3]
8: [5, 7, 3, 32]
9: [9, 10, 2, 0]
If the memory is not yet been initialized:
>> !mem
The memory has not been initialized yet
!mem[addr]
The !mem[addr] command prints out memory contents at the address specified by addr.
If the addr has been initialized:
>> !mem[9]
9: [9, 10, 2, 0]
If the addr has not been initialized:
>> !mem[87]
Memory at address 87 is empty
!use
The !use command prints out the list of all modules available for import.
If the stdlib was added to the available libraries list !use command will print all its modules:
>> !use
Modules available for importing:
std::collections::mmr
std::collections::smt
...
std::mem
std::sys
std::utils
Using the !use command with a module name will add the specified module to the program imports:
>> !use std::math::u64
>> !program
use.std::math::u64
begin
end
!undo
The !undo command reverts to the previous state of the stack and memory by dropping off the last executed assembly instruction from the program. One could use !undo as often as they want to restore the state of a stack and memory instructions ago (provided there are instructions in the program). The !undo command will result in an error if no remaining instructions are left in the Miden program.
>> push.1 push.2 push.3
>> push.4
>> !stack
4 3 2 1 0 0 0 0 0 0 0 0 0 0 0 0
>> push.5
>> !stack
5 4 3 2 1 0 0 0 0 0 0 0 0 0 0 0
>> !undo
4 3 2 1 0 0 0 0 0 0 0 0 0 0 0 0
>> !undo
3 2 1 0 0 0 0 0 0 0 0 0 0 0 0 0
User Documentation
In the following sections, we provide developer-focused documentation useful to those who want to develop on Miden VM or build compilers from higher-level languages to Miden VM.
This documentation consists of two high-level sections:
- Miden assembly which provides a detailed description of Miden assembly language, which is the native language of Miden VM.
- Miden Standard Library which provides descriptions of all procedures available in Miden Standard Library.
For info on how to run programs on Miden VM, please refer to the usage section in the introduction.
Miden Assembly
Miden assembly is a simple, low-level language for writing programs for Miden VM. It stands just above raw Miden VM instruction set, and in fact, many instructions of Miden assembly map directly to raw instructions of Miden VM.
Before Miden assembly can be executed on Miden VM, it needs to be compiled into a Program MAST (Merkelized Abstract Syntax Tree) which is a binary tree of code blocks each containing raw Miden VM instructions.
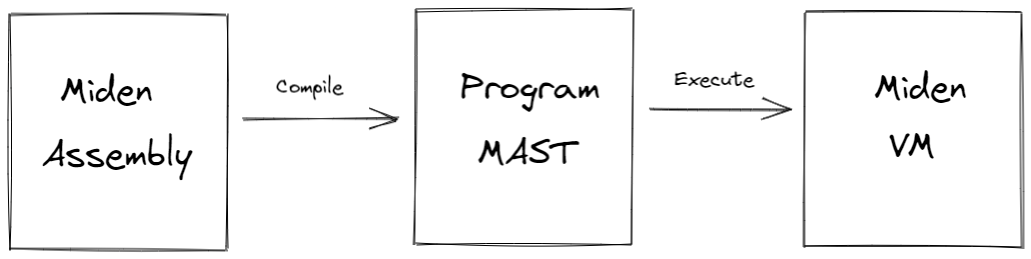
As compared to raw Miden VM instructions, Miden assembly has several advantages:
- Miden assembly is intended to be a more stable external interface for the VM. That is, while we plan to make significant changes to the underlying VM to optimize it for stability, performance etc., we intend to make very few breaking changes to Miden assembly.
- Miden assembly natively supports control flow expressions which the assembler automatically transforms into a program MAST. This greatly simplifies writing programs with complex execution logic.
- Miden assembly supports macro instructions. These instructions expand into short sequences of raw Miden VM instructions making it easier to encode common operations.
- Miden assembly supports procedures. These are stand-alone blocks of code which the assembler inlines into program MAST at compile time. This improves program modularity and code organization.
The last two points also make Miden assembly much more concise as compared to the raw program MAST. This may be important in the blockchain context where pubic programs need to be stored on chain.
Terms and notations
In this document we use the following terms and notations:
- is the modulus of the VM's base field which is equal to .
- A binary value means a field element which is either or .
- Inequality comparisons are assumed to be performed on integer representations of field elements in the range .
Throughout this document, we use lower-case letters to refer to individual field elements (e.g., ). Sometimes it is convenient to describe operations over groups of elements. For these purposes we define a word to be a group of four elements. We use upper-case letters to refer to words (e.g., ). To refer to individual elements within a word, we use numerical subscripts. For example, is the first element of word , is the last element of word , etc.
Design goals
The design of Miden assembly tries to achieve the following goals:
- Miden assembly should be an easy compilation target for high-level languages.
- Programs written in Miden assembly should be readable, even if the code is generated by a compiler from a high-level language.
- Control flow should be easy to understand to help in manual inspection, formal verification, and optimization.
- Compilation of Miden assembly into Miden program MAST should be as straight-forward as possible.
- Serialization of Miden assembly into a binary representation should be as compact and as straight-forward as possible.
In order to achieve the first goal, Miden assembly exposes a set of native operations over 32-bit integers and supports linear read-write memory. Thus, from the stand-point of a higher-level language compiler, Miden VM can be viewed as a regular 32-bit stack machine with linear read-write memory.
In order to achieve the second and third goals, Miden assembly facilitates flow control via high-level constructs like while loops, if-else statements, and function calls with statically defined targets. Thus, for example, there are no explicit jump instructions.
In order to achieve the fourth goal, Miden assembly retains direct access to the VM stack rather than abstracting it away with higher-level constructs and named variables.
Lastly, in order to achieve the fifth goal, each instruction of Miden assembly can be encoded using a single byte. The resulting byte-code is simply a one-to-one mapping of instructions to their binary values.
Code organization
A Miden assembly program is just a sequence of instructions each describing a specific directive or an operation. You can use any combination of whitespace characters to separate one instruction from another.
In turn, Miden assembly instructions are just keywords which can be parameterized by zero or more parameters. The notation for specifying parameters is keyword.param1.param2 - i.e., the parameters are separated by periods. For example, push.123 instruction denotes a push operation which is parameterized by value 123.
Miden assembly programs are organized into procedures. Procedures, in turn, can be grouped into modules.
Procedures
A procedure can be used to encapsulate a frequently-used sequence of instructions which can later be invoked via a label. A procedure must start with a proc.<label>.<number of locals> instruction and terminate with an end instruction. For example:
proc.foo.2
<instructions>
end
A procedure label must start with a letter and can contain any combination of numbers, ASCII letters, and underscores (_). Should you need to represent a label with other characters, an extended set is permitted via quoted identifiers, i.e. an identifier surrounded by "..". Quoted identifiers additionally allow any alphanumeric letter (ASCII or UTF-8), as well as various common punctuation characters: !, ?, :, ., <, >, and -. Quoted identifiers are primarily intended for representing symbols/identifiers when compiling higher-level languages to Miden Assembly, but can be used anywhere that normal identifiers are expected.
The number of locals specifies the number of memory-based local field elements a procedure can access (via loc_load, loc_store, and other instructions). If a procedure doesn't need any memory-based locals, this parameter can be omitted or set to 0. A procedure can have at most locals, and the total number of locals available to all procedures at runtime is limited to . Note that the assembler internally always rounds up the number of declared locals to the nearest multiple of 4.
To execute a procedure, the exec.<label>, call.<label>, and syscall.<label> instructions can be used. For example:
exec.foo
The difference between using each of these instructions is explained in the next section.
A procedure may execute any other procedure, however recursion is not currently permitted, due to limitations imposed by the Merkalized Abstract Syntax Tree. Recursion is caught by static analysis of the call graph during assembly, so in general you don't need to think about this, but it is a limitation to be aware of. For example, the following code block defines a program with two procedures:
proc.bar
<instructions>
exec.foo
<instructions>
end
proc.foo
<instructions>
end
begin
<instructions>
exec.bar
<instructions>
exec.foo
end
Dynamic procedure invocation
It is also possible to invoke procedures dynamically - i.e., without specifying target procedure labels at compile time. A procedure can only call itself using dynamic invocation. There are two instructions, dynexec and dyncall, which can be used to execute dynamically-specified code targets. Both instructions expect the MAST root of the target to be stored in memory, and the memory address of the MAST root to be on the top of the stack. The difference between dynexec and dyncall corresponds to the difference between exec and call, see the documentation on procedure invocation semantics for more details.
Dynamic code execution in the same context is achieved by setting the top element of the stack to the memory address where the hash of the dynamic code block is stored, and then executing the dynexec or dyncall instruction. You can obtain the hash of a procedure in the current program, by name, using the procref instruction. See the following example of pairing the two:
# Retrieve the hash of `foo`, store it at `ADDR`, and push `ADDR` on top of the stack
procref.foo mem_storew.ADDR dropw push.ADDR
# Execute `foo` dynamically
dynexec
During assembly, the procref.foo instruction is compiled to a push.HASH, where HASH is the hash of the MAST root of the foo procedure.
During execution of the dynexec instruction, the VM does the following:
- Read the top stack element , and read the memory word starting at address (the hash of the dynamic target),
- Shift the stack left by one element,
- Load the code block referenced by the hash, or trap if no such MAST root is known,
- Execute the loaded code block.
The dyncall instruction is used the same way, with the difference that it involves a context switch to a new context when executing the referenced block, and switching back to the calling context once execution of the callee completes.
Modules
A module consists of one or more procedures. There are two types of modules: library modules and executable modules (also called programs).
Library modules
Library modules contain zero or more internal procedures and one or more exported procedures. For example, the following module defines one internal procedure (defined with proc instruction) and one exported procedure (defined with export instruction):
proc.foo
<instructions>
end
export.bar
<instructions>
exec.foo
<instructions>
end
Programs
Executable modules are used to define programs. A program contains zero or more internal procedures (defined with proc instruction) and exactly one main procedure (defined with begin instruction). For example, the following module defines one internal procedure and a main procedure:
proc.foo
<instructions>
end
begin
<instructions>
exec.foo
<instructions>
end
A program cannot contain any exported procedures.
When a program is executed, the execution starts at the first instruction following the begin instruction. The main procedure is expected to be the last procedure in the program and can be followed only by comments.
Importing modules
To reference items in another module, you must either import the module you wish to use, or specify a fully-qualified path to the item you want to reference.
To import a module, you must use the use keyword in the top level scope of the current module, as shown below:
use.std::math::u64
begin
...
end
In this example, the std::math::u64 module is imported as u64, the default "alias" for the imported module. You can specify a different alias like so:
use.std::math::u64->bigint
This would alias the imported module as bigint rather than u64. The alias is needed to reference items from the imported module, as shown below:
use.std::math::u64
begin
push.1.0
push.2.0
exec.u64::wrapping_add
end
You can also bypass imports entirely, and specify an absolute procedure path, which requires prefixing the path with ::. For example:
begin
push.1.0
push.2.0
exec.::std::math::u64::wrapping_add
end
In the examples above, we have been referencing the std::math::u64 module, which is a module in the Miden Standard Library. There are a number of useful modules there, that provide a variety of helpful functionality out of the box.
If the assembler does not know about the imported modules, assembly will fail. You can register modules with the assembler when instantiating it, either in source form, or precompiled form. See the miden-assembly docs for details. The assembler will use this information to resolve references to imported procedures during assembly.
Re-exporting procedures
A procedure defined in one module can be re-exported from a different module under the same or a different name. For example:
use.std::math::u64
export.u64::add
export.u64::mul->mul64
export.foo
<instructions>
end
In the module shown above, not only is the locally-defined procedure foo exported, but so are two procedures named add and mul64, whose implementations are defined in the std::math::u64 module.
Similar to procedure invocation, you can bypass the explicit import by specifying an absolute path, like so:
export.::std::math::u64::mul->mul64
Additionally, you may re-export a procedure using its MAST root, so long as you specify an alias:
export.0x0000..0000->mul64
In all of the forms described above, the actual implementation of the re-exported procedure is defined externally. Other modules which reference the re-exported procedure, will have those references resolved to the original procedure during assembly.
Constants
Miden assembly supports constant declarations. These constants are scoped to the module they are defined in and can be used as immediate parameters for Miden assembly instructions. Constants are supported as immediate values for many of the instructions in the Miden Assembly instruction set, see the documentation for specific instructions to determine whether or not it provides a form which accepts immediate operands.
Constants must be declared right after module imports and before any procedures or program bodies. A constant's name must start with an upper-case letter and can contain any combination of numbers, upper-case ASCII letters, and underscores (_). The number of characters in a constant name cannot exceed 100.
A constant's value must be in a decimal or hexadecimal form and be in the range between and (both inclusive). Value can be defined by an arithmetic expression using +, -, *, /, //, (, ) operators and references to the previously defined constants if it uses only decimal numbers. Here / is a field division and // is an integer division. Note that the arithmetic expression cannot contain spaces.
use.std::math::u64
const.CONSTANT_1=100
const.CONSTANT_2=200+(CONSTANT_1-50)
const.ADDR_1=3
begin
push.CONSTANT_1.CONSTANT_2
exec.u64::wrapping_add
mem_store.ADDR_1
end
Comments
Miden assembly allows annotating code with simple comments. There are two types of comments: single-line comments which start with a # (pound) character, and documentation comments which start with #! characters. For example:
#! This is a documentation comment
export.foo
# this is a comment
push.1
end
Documentation comments must precede a procedure declaration. Using them inside a procedure body is an error.
Execution contexts
Miden assembly program execution can span multiple isolated contexts. An execution context defines its own memory space which is not accessible from other execution contexts.
All programs start executing in a root context. Thus, the main procedure of a program is always executed in the root context. To move execution into a different context, we can invoke a procedure using the call instruction. In fact, any time we invoke a procedure using the call instruction, the procedure is executed in a new context. We refer to all non-root contexts as user contexts.
While executing in a user context, we can request to execute some procedures in the root context. This can be done via the syscall instruction. The set of procedures which can be invoked via the syscall instruction is limited by the kernel against which a program is compiled. Once the procedure called via syscall returns, the execution moves back to the user context from which it was invoked. The diagram below illustrates this graphically:
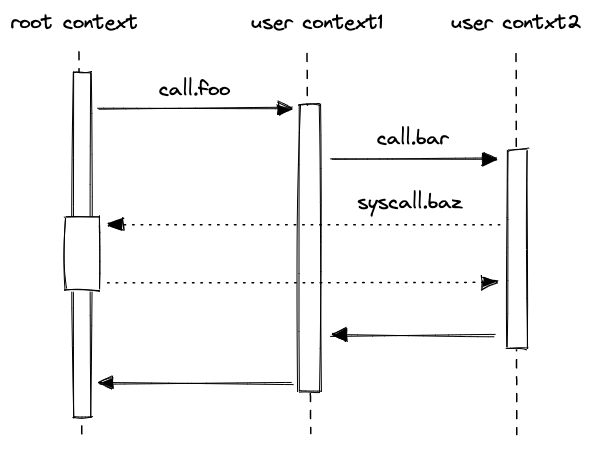
Procedure invocation semantics
As mentioned in the previous section, procedures in Miden assembly can be invoked via five different instructions: exec, call, syscall, dynexec, and dyncall. Invocation semantics of call, dyncall, and syscall instructions are basically the same, the only difference being that the syscall instruction can be used only with procedures which are defined in the program's kernel. The exec and dynexec instructions are different, and we explain these differences below.
Invoking via call, dyncall, and syscall instructions
When a procedure is invoked via a call, dyncall, or a syscall instruction, the following happens:
- Execution moves into a different context. In case of the
callanddyncallinstructions, a new user context is created. In case of asyscallinstruction, the execution moves back into the root context. - All stack items beyond the 16th item get "hidden" from the invoked procedure. That is, from the standpoint of the invoked procedure, the initial stack depth is set to 16.
- Note that for
dyncall, the stack is shifted left by one element before being set to 16.
- Note that for
When the callee returns, the following happens:
- The execution context of the caller is restored
- If the original stack depth was greater than 16, those elements that were "hidden" during the call as described above, are restored. However, the stack depth must be exactly 16 elements when the procedure returns, or this will fail and the VM will trap.
The manipulations of the stack depth described above have the following implications:
- The top 16 elements of the stack can be used to pass parameters and return values between the caller and the callee.
- Caller's stack beyond the top 16 elements is inaccessible to the callee, and thus, is guaranteed not to change as the result of the call.
- As mentioned above, in the case of
dyncall, the elements at indices 1 to 17 at the call site will be accessible to the callee (shifted to indices 0 to 16)
- As mentioned above, in the case of
- At the end of its execution, the callee must ensure that stack depth is exactly 16. If this is difficult to ensure manually, the
truncate_stackprocedure can be used to drop all elements from the stack except for the top 16.
Invoking via exec instruction
The exec instruction can be thought of as the "normal" way of invoking procedures, i.e. it has semantics that would be familiar to anyone coming from a standard programming language, or that is familiar with procedure call instructions in a typical assembly language.
In Miden Assembly, it is used to execute procedures without switching execution contexts, i.e. the callee executes in the same context as the caller. Conceptually, invoking a procedure via exec behaves as if the body of that procedure was inlined at the call site. In practice, the procedure may or may not be actually inlined, based on compiler optimizations around code size, but there is no actual performance tradeoff in the usual sense. Thus, when executing a program, there is no meaningful difference between executing a procedure via exec, or replacing the exec with the body of the procedure.
Kernels
A kernel defines a set of procedures which can be invoked from user contexts to be executed in the root context. Miden assembly programs are always compiled against some kernel. The default kernel is empty - i.e., it does not contain any procedures. To compile a program against a non-empty kernel, the kernel needs to be specified when instantiating the Miden Assembler.
A kernel can be defined similarly to a regular library module - i.e., it can have internal and exported procedures. However, there are some small differences between what procedures can do in a kernel module vs. what they can do in a regular library module. Specifically:
- Procedures in a kernel module cannot use
call,dyncallorsyscallinstructions. This means that creating a new context from within asyscallis not possible. - Unlike procedures in regular library modules, procedures in a kernel module can use the
callerinstruction. This instruction puts the hash of the procedure which initiated the parent context onto the stack.
Memory layout
As mentioned earlier, procedures executed within a given context can access memory only of that context. This is true for both memory reads and memory writes.
Address space of every context is the same: the smallest accessible address is and the largest accessible address is . Any code executed in a given context has access to its entire address space. However, by convention, we assign different meanings to different regions of the address space.
For user contexts we have the following:
- The first addresses are assumed to be global memory.
- The next addresses are reserved for memory locals of procedures executed in the same context (i.e., via the
execinstruction). - The remaining address space has no special meaning.

For the root context we have the following:
- The first addresses are assumed to be global memory.
- The next addresses are reserved for memory locals of procedures executed in the root context.
- The next addresses are reserved for memory locals of procedures executed from within a
syscall. - The remaining address space has no special meaning.

For both types of contexts, writing directly into regions of memory reserved for procedure locals is not advisable. Instead, loc_load, loc_store and other similar dedicated instructions should be used to access procedure locals.
Example
To better illustrate what happens as we execute procedures in different contexts, let's go over the following example.
kernel
--------------------
export.baz.2
<instructions>
caller
<instructions>
end
program
--------------------
proc.bar.1
<instructions>
syscall.baz
<instructions>
end
proc.foo.3
<instructions>
call.bar
<instructions>
exec.bar
<instructions>
end
begin
<instructions>
call.foo
<instructions>
end
Execution of the above program proceeds as follows:
- The VM starts executing instructions immediately following the
beginstatement. These instructions are executed in the root context (let's call this contextctx0). - When
call.foois executed, a new context is created (ctx1). Memory in this context is isolated fromctx0. Additionally, any elements on the stack beyond the top 16 are hidden fromfoo. - Instructions executed inside
foocan access memory ofctx1only. The address of the first procedure local infoo(e.g., accessed vialoc_load.0) is . - When
call.baris executed, a new context is created (ctx2). The stack depth is set to 16 again, and any instruction executed in this context can access memory ofctx2only. The first procedure local ofbaris also located at address . - When
syscall.bazis executed, the execution moves back into the root context. That is, instructions executed insidebazhave access to the memory ofctx0. The first procedure local ofbazis located at address . Whenbazstarts executing, the stack depth is again set to 16. - When
calleris executed insidebaz, the first 4 elements of the stack are populated with the hash ofbarsincebazwas invoked frombar's context. - Once
bazreturns, execution moves back toctx2, and then, whenbarreturns, execution moves back toctx1. We assume that instructions executed right before each procedure returns ensure that the stack depth is exactly 16 right before procedure's end. - Next, when
exec.baris executed,baris executed again, but this time it is executed in the same context asfoo. Thus, it can access memory ofctx1. Moreover, the stack depth is not changed, and thus,barcan access the entire stack offoo. Lastly, this first procedure local ofbarnow will be at address (since the first 3 locals in this context are reserved forfoo). - When
syscall.bazis executed the second time, execution moves into the root context again. However, now, whencalleris executed insidebaz, the first 4 elements of the stack are populated with the hash offoo(notbar). This happens because this time aroundbardoes not have its own context andbazis invoked fromfoo's context. - Finally, when
bazreturns, execution moves back toctx1, and then asbarandfooreturn, back toctx0, and the program terminates.
Flow control
As mentioned above, Miden assembly provides high-level constructs to facilitate flow control. These constructs are:
- if-else expressions for conditional execution.
- repeat expressions for bounded counter-controlled loops.
- while expressions for unbounded condition-controlled loops.
Conditional execution
Conditional execution in Miden VM can be accomplished with if-else statements. These statements can take one of the following forms:
if.true .. else .. end
This is the full form, when there is work to be done on both branches:
if.true
..instructions..
else
..instructions..
end
if.true .. end
This is the abbreviated form, for when there is only work to be done on one branch. In these cases the "unused" branch can be elided:
if.true
..instructions..
end
In addition to if.true, there is also if.false, which is identical in syntax, but for false-conditioned branches. It is equivalent in semantics to using if.true and swapping the branches.
The body of each branch, i.e. ..instructions.. in the examples above, can be a sequence of zero or more instructions (an empty body is only valid so long as at least one branch is non-empty). These can consist of any instruction, including nested control flow.
tip
As with other control structures described below that have nested blocks,
it is essential that you ensure that the state of the operand stack is
consistent at join points in control flow. For example, with if.true
control flow implicitly joins at the end of each branch. If you have moved
items around on the operand stack, or added/removed items, and those
modifications would persist past the end of that branch, it is highly
recommended that you make equivalent modifications in the opposite branch.
This is not required if modifications are local to a block.
The semantics of the if.true and if.false control operator are as follows:
- The condition is popped from the top of the stack. It must be a boolean value, i.e. for false, for true. If the condition is not a boolean value, then execution traps.
- The conditional branch is chosen:
a. If the operator is
if.true, and the condition is true, instructions in the first branch are executed; otherwise, if the condition is false, then the second branch is executed. If a branch was elided or empty, the assembler provides a default body consisting of a singlenopinstruction. b. If the operator isif.false, the behavior is identical to that ofif.true, except the condition must be false for the first branch to be taken, and true for the second branch. - Control joins at the next instruction immediately following the
if.true/if.falseinstruction.
tip
A note on performance: using if-else statements incurs a small, but non-negligible overhead. Thus, for simple conditional statements, it may be more efficient to compute the result of both branches, and then select the result using conditional drop instructions.
This does not apply to if-else statements whose bodies contain side-effects that cannot be easily adapted to this type of rewrite. For example, writing a value to global memory is a side effect, but if both branches would write to the same address, and only the value being written differs, then this can likely be rewritten to use cdrop.
Counter-controlled loops
Executing a sequence of instructions a predefined number of times can be accomplished with repeat statements. These statements look like so:
repeat.<count>
<instructions>
end
where:
instructionscan be a sequence of any instructions, including nested control structures.countis the number of times theinstructionssequence should be repeated (e.g.repeat.10).countmust be an integer or a constant greater than .
Note: During compilation the
repeat.<count>blocks are unrolled and expanded into<count>copies of its inner block, there is no additional cost for counting variables in this case.
Condition-controlled loops
Executing a sequence of instructions zero or more times based on some condition can be accomplished with while loop expressions. These expressions look like so:
while.true
<instructions>
end
where instructions can be a sequence of any instructions, including nested control structures. The above does the following:
- Pops the top item from the stack.
- If the value of the item is ,
instructionsin the loop body are executed.- After the body is executed, the stack is popped again, and if the popped value is , the body is executed again.
- If the popped value is , the loop is exited.
- If the popped value is not binary, the execution fails.
- If the value of the item is , execution of loop body is skipped.
- If the value is not binary, the execution fails.
Example:
# push the boolean true to the stack
push.1
# pop the top element of the stack and loop while it is true
while.true
# push the boolean false to the stack, finishing the loop for the next iteration
push.0
end
No-op
While rare, there may be situations where you have an empty block and require a do-nothing placeholder instruction, or where you specifically want to advance the cycle counter without any side-effects. The nop instruction can be used in these instances.
if.true
nop
else
..instructions..
end
In the example above, we do not want to perform any work if the condition is true, so we place a nop in that branch. This explicit representation of "empty" blocks is automatically done by the assembler when parsing if.true or if.false in abbreviated form, or when one of the branches is empty.
The semantics of this instruction are to increment the cycle count, and that is it - no other effects.
Field operations
Miden assembly provides a set of instructions which can perform operations with raw field elements. These instructions are described in the tables below.
While most operations place no restrictions on inputs, some operations expect inputs to be binary values, and fail if executed with non-binary inputs.
For instructions where one or more operands can be provided as immediate parameters (e.g., add and add.b), we provide stack transition diagrams only for the non-immediate version. For the immediate version, it can be assumed that the operand with the specified name is not present on the stack.
Assertions and tests
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| assert - (1 cycle) | [a, ...] | [...] | If , removes it from the stack. Fails if |
| assertz - (2 cycles) | [a, ...] | [...] | If , removes it from the stack, Fails if |
| assert_eq - (2 cycles) | [b, a, ...] | [...] | If , removes them from the stack. Fails if |
| assert_eqw - (11 cycles) | [B, A, ...] | [...] | If , removes them from the stack. Fails if |
The above instructions can also be parametrized with an error code which can be any 32-bit value specified either directly or via a named constant. For example:
assert.err=123
assert.err=MY_CONSTANT
If the error code is omitted, the default value of is assumed.
Arithmetic and Boolean operations
The arithmetic operations below are performed in a 64-bit prime field defined by modulus . This means that overflow happens after a value exceeds . Also, the result of divisions may appear counter-intuitive because divisions are defined via inversions.
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| add - (1 cycle) add.b - (1-2 cycle) | [b, a, ...] | [c, ...] | |
| sub - (2 cycles) sub.b - (2 cycles) | [b, a, ...] | [c, ...] | |
| mul - (1 cycle) mul.b - (2 cycles) | [b, a, ...] | [c, ...] | |
| div - (2 cycles) div.b - (2 cycles) | [b, a, ...] | [c, ...] | Fails if |
| neg - (1 cycle) | [a, ...] | [b, ...] | |
| inv - (1 cycle) | [a, ...] | [b, ...] | Fails if |
| pow2 - (16 cycles) | [a, ...] | [b, ...] | Fails if |
| exp.uxx - (9 + xx cycles) exp.b - (9 + log2(b) cycles) | [b, a, ...] | [c, ...] | Fails if xx is outside [0, 63) exp is equivalent to exp.u64 and needs 73 cycles |
| ilog2 - (44 cycles) | [a, ...] | [b, ...] | Fails if |
| not - (1 cycle) | [a, ...] | [b, ...] | Fails if |
| and - (1 cycle) | [b, a, ...] | [c, ...] | Fails if |
| or - (1 cycle) | [b, a, ...] | [c, ...] | Fails if |
| xor - (7 cycles) | [b, a, ...] | [c, ...] | Fails if |
Comparison operations
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| eq - (1 cycle) eq.b - (1-2 cycles) | [b, a, ...] | [c, ...] | |
| neq - (2 cycle) neq.b - (2-3 cycles) | [b, a, ...] | [c, ...] | |
| lt - (14 cycles) lt.b - (15 cycles) | [b, a, ...] | [c, ...] | |
| lte - (15 cycles) lte.b - (16 cycles) | [b, a, ...] | [c, ...] | |
| gt - (15 cycles) gt.b - (16 cycles) | [b, a, ...] | [c, ...] | |
| gte - (16 cycles) gte.b - (17 cycles) | [b, a, ...] | [c, ...] | |
| is_odd - (5 cycles) | [a, ...] | [b, ...] | |
| eqw - (15 cycles) | [A, B, ...] | [c, A, B, ...] |
Extension Field Operations
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| ext2add - (5 cycles) | [b1, b0, a1, a0, ...] | [c1, c0, ...] | and |
| ext2sub - (7 cycles) | [b1, b0, a1, a0, ...] | [c1, c0, ...] | and |
| ext2mul - (3 cycles) | [b1, b0, a1, a0, ...] | [c1, c0, ...] | and |
| ext2neg - (4 cycles) | [a1, a0, ...] | [a1', a0', ...] | and |
| ext2inv - (8 cycles) | [a1, a0, ...] | [a1', a0', ...] | Fails if |
| ext2div - (11 cycles) | [b1, b0, a1, a0, ...] | [c1, c0,] | fails if , where multiplication and inversion are as defined by the operations above |
u32 operations
Miden assembly provides a set of instructions which can perform operations on regular two-complement 32-bit integers. These instructions are described in the tables below.
For instructions where one or more operands can be provided as immediate parameters (e.g., u32wrapping_add and u32wrapping_add.b), we provide stack transition diagrams only for the non-immediate version. For the immediate version, it can be assumed that the operand with the specified name is not present on the stack.
In all the table below, the number of cycles it takes for the VM to execute each instruction is listed beneath the instruction.
Notes on Undefined Behavior
Most of the instructions documented below expect to receive operands whose values are valid u32
values, i.e. values in the range . Currently, the semantics of the instructions
when given values outside of that range are undefined (as noted in the documented semantics for
each instruction). The rule with undefined behavior generally speaking is that you can make no
assumptions about what will happen if your program exhibits it.
For purposes of describing the effects of undefined behavior below, we will refer to values which
are not valid for the input type of the affected operation, e.g. u32, as poison. Any use of a
poison value propagates the poison state. For example, performing u32div with a poison operand,
can be considered as producing a poison value as its result, for the purposes of discussing
undefined behavior semantics.
With that in mind, there are two ways in which the effects of undefined behavior manifest:
Executor Semantics
From an executor perspective, currently, the semantics are completely undefined. An executor can do everything from terminate the program, panic, always produce 42 as a result, produce a random result, or something more principled.
In practice, the Miden VM, when executing an operation, will almost always trap on poison values. This is not guaranteed, but is currently the case for most operations which have niches of undefined behavior. To the extent that some other behavior may occur, it will generally be to truncate/wrap the poison value, but this is subject to change at any time, and is undocumented. You should assume that all operations will trap on poison.
The reason the Miden VM makes the choice to trap on poison, is to ensure that undefined behavior is caught close to the source, rather than propagated silently throughout the program. It also has the effect of ensuring you do not execute a program with undefined behavior, and produce a proof that is not actually valid, as we will describe in a moment.
Verifier Semantics
From the perspective of the verifier, the implementation details of the executor are completely unknown. For example, the fact that the Miden VM traps on poison values is not actually verified by constraints. An alternative executor implementation could choose not to trap, and thus appear to execute successfully. The resulting proof, however, as a result of the program exhibiting undefined behavior, is not a valid proof. In effect the use of poison values "poisons" the proof as well.
As a result, a program that exhibits undefined behavior, and executes successfully, will produce a proof that could pass verification, even though it should not. In other words, the proof does not prove what it says it does.
In the future, we may attempt to remove niches of undefined behavior in such a way that producing such invalid proofs is not possible, but for the time being, you must ensure that your program does not exhibit (or rely on) undefined behavior.
Conversions and tests
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| u32test - (5 cycles) | [a, ...] | [b, a, ...] | |
| u32testw - (23 cycles) | [A, ...] | [b, A, ...] | |
| u32assert - (3 cycles) | [a, ...] | [a, ...] | Fails if |
| u32assert2 - (1 cycle) | [b, a,...] | [b, a,...] | Fails if or |
| u32assertw - (6 cycles) | [A, ...] | [A, ...] | Fails if |
| u32cast - (2 cycles) | [a, ...] | [b, ...] | |
| u32split - (1 cycle) | [a, ...] | [c, b, ...] | , |
The instructions u32assert, u32assert2 and u32assertw can also be parametrized with an error code which can be any 32-bit value specified either directly or via a named constant. For example:
u32assert.err=123
u32assert.err=MY_CONSTANT
If the error code is omitted, the default value of is assumed.
Arithmetic operations
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| u32overflowing_add - (1 cycle) u32overflowing_add.b - (2-3 cycles) | [b, a, ...] | [d, c, ...] | Undefined if |
| u32wrapping_add - (2 cycles) u32wrapping_add.b - (3-4 cycles) | [b, a, ...] | [c, ...] | Undefined if |
| u32overflowing_add3 - (1 cycle) | [c, b, a, ...] | [e, d, ...] | , Undefined if |
| u32wrapping_add3 - (2 cycles) | [c, b, a, ...] | [d, ...] | , Undefined if |
| u32overflowing_sub - (1 cycle) u32overflowing_sub.b - (2-3 cycles) | [b, a, ...] | [d, c, ...] | Undefined if |
| u32wrapping_sub - (2 cycles) u32wrapping_sub.b - (3-4 cycles) | [b, a, ...] | [c, ...] | Undefined if |
| u32overflowing_mul - (1 cycle) u32overflowing_mul.b - (2-3 cycles) | [b, a, ...] | [d, c, ...] | Undefined if |
| u32wrapping_mul - (2 cycles) u32wrapping_mul.b - (3-4 cycles) | [b, a, ...] | [c, ...] | Undefined if |
| u32overflowing_madd - (1 cycle) | [b, a, c, ...] | [e, d, ...] | Undefined if |
| u32wrapping_madd - (2 cycles) | [b, a, c, ...] | [d, ...] | Undefined if |
| u32div - (2 cycles) u32div.b - (3-4 cycles) | [b, a, ...] | [c, ...] | Fails if Undefined if |
| u32mod - (3 cycles) u32mod.b - (4-5 cycles) | [b, a, ...] | [c, ...] | Fails if Undefined if |
| u32divmod - (1 cycle) u32divmod.b - (2-3 cycles) | [b, a, ...] | [d, c, ...] | Fails if Undefined if |
Bitwise operations
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| u32and - (1 cycle) u32and.b - (2 cycles) | [b, a, ...] | [c, ...] | Computes as a bitwise AND of binary representations of and . Fails if |
| u32or - (6 cycle)s u32or.b - (7 cycles) | [b, a, ...] | [c, ...] | Computes as a bitwise OR of binary representations of and . Fails if |
| u32xor - (1 cycle) u32xor.b - (2 cycles) | [b, a, ...] | [c, ...] | Computes as a bitwise XOR of binary representations of and . Fails if |
| u32not - (5 cycles) u32not.a - (6 cycles) | [a, ...] | [b, ...] | Computes as a bitwise NOT of binary representation of . Fails if |
| u32shl - (18 cycles) u32shl.b - (3 cycles) | [b, a, ...] | [c, ...] | Undefined if or |
| u32shr - (18 cycles) u32shr.b - (3 cycles) | [b, a, ...] | [c, ...] | Undefined if or |
| u32rotl - (18 cycles) u32rotl.b - (3 cycles) | [b, a, ...] | [c, ...] | Computes by rotating a 32-bit representation of to the left by bits. Undefined if or |
| u32rotr - (23 cycles) u32rotr.b - (3 cycles) | [b, a, ...] | [c, ...] | Computes by rotating a 32-bit representation of to the right by bits. Undefined if or |
| u32popcnt - (33 cycles) | [a, ...] | [b, ...] | Computes by counting the number of set bits in (hamming weight of ). Undefined if |
| u32clz - (42 cycles) | [a, ...] | [b, ...] | Computes as a number of leading zeros of . Undefined if |
| u32ctz - (34 cycles) | [a, ...] | [b, ...] | Computes as a number of trailing zeros of . Undefined if |
| u32clo - (41 cycles) | [a, ...] | [b, ...] | Computes as a number of leading ones of . Undefined if |
| u32cto - (33 cycles) | [a, ...] | [b, ...] | Computes as a number of trailing ones of . Undefined if |
Comparison operations
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| u32lt - (3 cycles) u32lt.b - (4 cycles) | [b, a, ...] | [c, ...] | Undefined if |
| u32lte - (5 cycles) u32lte.b - (6 cycles) | [b, a, ...] | [c, ...] | Undefined if |
| u32gt - (4 cycles) u32gt.b - (5 cycles) | [b, a, ...] | [c, ...] | Undefined if |
| u32gte - (4 cycles) u32gte.b - (5 cycles) | [b, a, ...] | [c, ...] | Undefined if |
| u32min - (8 cycles) u32min.b - (9 cycles) | [b, a, ...] | [c, ...] | Undefined if |
| u32max - (9 cycles) u32max.b - (10 cycles) | [b, a, ...] | [c, ...] | Undefined if |
Stack manipulation
Miden VM stack is a push-down stack of field elements. The stack has a maximum depth of , but only the top elements are directly accessible via the instructions listed below.
In addition to the typical stack manipulation instructions such as drop, dup, swap etc., Miden assembly provides several conditional instructions which can be used to manipulate the stack based on some condition - e.g., conditional swap cswap or conditional drop cdrop.
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| drop - (1 cycle) | [a, ... ] | [ ... ] | Deletes the top stack item. |
| dropw - (4 cycles) | [A, ... ] | [ ... ] | Deletes a word (4 elements) from the top of the stack. |
| padw - (4 cycles) | [ ... ] | [0, 0, 0, 0, ... ] | Pushes four values onto the stack. Note: simple pad is not provided because push.0 does the same thing. |
| dup.n - (1-3 cycles) | [ ..., a, ... ] | [a, ..., a, ... ] | Pushes a copy of the th stack item onto the stack. dup and dup.0 are the same instruction. Valid for |
| dupw.n - (4 cycles) | [ ..., A, ... ] | [A, ..., A, ... ] | Pushes a copy of the th stack word onto the stack. dupw and dupw.0 are the same instruction. Valid for |
| swap.n - (1-6 cycles) | [a, ..., b, ... ] | [b, ..., a, ... ] | Swaps the top stack item with the th stack item. swap and swap.1 are the same instruction. Valid for |
| swapw.n - (1 cycle) | [A, ..., B, ... ] | [B, ..., A, ... ] | Swaps the top stack word with the th stack word. swapw and swapw.1 are the same instruction. Valid for |
| swapdw - (1 cycle) | [D, C, B, A, ... ] | [B, A, D, C ... ] | Swaps words on the top of the stack. The 1st with the 3rd, and the 2nd with the 4th. |
| movup.n - (1-4 cycles) | [ ..., a, ... ] | [a, ... ] | Moves the th stack item to the top of the stack. Valid for |
| movupw.n - (2-3 cycles) | [ ..., A, ... ] | [A, ... ] | Moves the th stack word to the top of the stack. Valid for |
| movdn.n - (1-4 cycles) | [a, ... ] | [ ..., a, ... ] | Moves the top stack item to the th position of the stack. Valid for |
| movdnw.n - (2-3 cycles) | [A, ... ] | [ ..., A, ... ] | Moves the top stack word to the th word position of the stack. Valid for |
Conditional manipulation
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| cswap - (1 cycle) | [c, b, a, ... ] | [e, d, ... ] | Fails if |
| cswapw - (1 cycle) | [c, B, A, ... ] | [E, D, ... ] | Fails if |
| cdrop - (2 cycles) | [c, b, a, ... ] | [d, ... ] | Fails if |
| cdropw - (5 cycles) | [c, B, A, ... ] | [D, ... ] | Fails if |
Input / output operations
Miden assembly provides a set of instructions for moving data between the operand stack and several other sources. These sources include:
- Program code: values to be moved onto the operand stack can be hard-coded in a program's source code.
- Environment: values can be moved onto the operand stack from environment variables. These include current clock cycle, current stack depth, and a few others.
- Advice provider: values can be moved onto the operand stack from the advice provider by popping them from the advice stack (see more about the advice provider here). The VM can also inject new data into the advice provider via system event instructions.
- Memory: values can be moved between the stack and random-access memory. The memory is element-addressable, meaning that a single element is located at each address. However, reading and writing elements to/from memory in batches of four is supported via the appropriate instructions (e.g.
mem_loadwormem_storew). Memory can be accessed via absolute memory references (i.e., via memory addresses) as well as via local procedure references (i.e., local index). The latter approach ensures that a procedure does not access locals of another procedure.
Constant inputs
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| push.a - (1-2 cycles) push.a.b push.a.b.c... | [ ... ] | [a, ... ] [b, a, ... ] [c, b, a, ... ] | Pushes values , , etc. onto the stack. Up to values can be specified. All values must be valid field elements in decimal (e.g., ) or hexadecimal (e.g., ) representation. |
The value can be specified in hexadecimal form without periods between individual values as long as it describes a full word ( field elements or bytes). Note that hexadecimal values separated by periods (short hexadecimal strings) are assumed to be in big-endian order, while the strings specifying whole words (long hexadecimal strings) are assumed to be in little-endian order. That is, the following are semantically equivalent:
push.0x00001234.0x00005678.0x00009012.0x0000abcd
push.0x341200000000000078560000000000001290000000000000cdab000000000000
push.4660.22136.36882.43981
In both case the values must still encode valid field elements.
Environment inputs
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| clk - (1 cycle) | [ ... ] | [t, ... ] | Pushes the current value of the clock cycle counter onto the stack. |
| sdepth - (1 cycle) | [ ... ] | [d, ... ] | Pushes the current depth of the stack onto the stack. |
| caller - (1 cycle) | [A, b, ... ] | [H, b, ... ] | Overwrites the top four stack items with the hash of a function which initiated the current SYSCALL. Executing this instruction outside of SYSCALL context will fail. |
| locaddr.i - (2 cycles) | [ ... ] | [a, ... ] | Pushes the absolute memory address of local memory at index onto the stack. |
| procref.name - (4 cycles) | [ ... ] | [A, ... ] | Pushes MAST root of the procedure with name onto the stack. |
Nondeterministic inputs
As mentioned above, nondeterministic inputs are provided to the VM via the advice provider. Instructs which access the advice provider fall into two categories. The first category consists of instructions which move data from the advice stack onto the operand stack and/or memory.
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| adv_push.n - (n cycles) | [ ... ] | [a, ... ] | Pops values from the advice stack and pushes them onto the operand stack. Valid for . Fails if the advice stack has fewer than values. |
| adv_loadw - (1 cycle) | [0, 0, 0, 0, ... ] | [A, ... ] | Pop the next word (4 elements) from the advice stack and overwrites the first word of the operand stack (4 elements) with them. Fails if the advice stack has fewer than values. |
| adv_pipe - (1 cycle) | [C, B, A, a, ... ] | [E, D, A, a', ... ] | Pops the next two words from the advice stack, overwrites the top of the operand stack with them and also writes these words into memory at address and . Fails if the advice stack has fewer than values. |
Note: The opcodes above always push data onto the operand stack so that the first element is placed deepest in the stack. For example, if the data on the stack is
a,b,c,dand you use the opcodeadv_push.4, the data will bed,c,b,aon your stack. This is also the behavior of the other opcodes.
The second category injects new data into the advice provider. These operations are called system events and they affect only the advice provider state. That is, the state of all other VM components (e.g., stack, memory) are unaffected. Handling system events does not consume any VM cycles (i.e., these instructions are executed in cycles).
System events fall into two categories: (1) events which push new data onto the advice stack, and (2) events which insert new data into the advice map.
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| adv.push_mapval | [K, ... ] | [K, ... ] | Pushes a list of field elements onto the advice stack. The list is looked up in the advice map using word as the key. |
| adv.push_mapvaln | [K, ... ] | [K, ... ] | Pushes a list of field elements together with the number of elements onto the advice stack ([n, ele1, ele2, ...], where n is the number of elements pushed). The list is looked up in the advice map using word as the key. |
| adv.push_mtnode | [d, i, R, ... ] | [d, i, R, ... ] | Pushes a node of a Merkle tree with root at depth and index from Merkle store onto the advice stack. |
| adv.push_u64div | [b1, b0, a1, a0, ...] | [b1, b0, a1, a0, ...] | Pushes the result of u64 division onto the advice stack. Both and are represented using 32-bit limbs. The result consists of both the quotient and the remainder. |
| adv.push_ext2intt | [osize, isize, iptr, ... ] | [osize, isize, iptr, ... ] | Given evaluations of a polynomial over some specified domain, interpolates the evaluations into a polynomial in coefficient form and pushes the result into the advice stack. |
| adv.push_smtpeek | [K, R, ... ] | [K, R, ... ] | Pushes value onto the advice stack which is associated with key in a Sparse Merkle Tree with root . |
| adv.insert_mem | [K, a, b, ... ] | [K, a, b, ... ] | Reads words from memory, and save the data into . |
| adv.insert_hdword | [B, A, ... ] | [B, A, ... ] | Reads top two words from the stack, computes a key as , and saves the data into . |
| adv.insert_hdword_d | [B, A, d, ... ] | [B, A, d, ... ] | Reads top two words from the stack, computes a key as , and saves the data into . is the domain value, where changing the domain changes the resulting hash given the same A and B. |
| adv.insert_hperm | [B, A, C, ...] | [B, A, C, ...] | Reads top three words from the stack, computes a key as , and saves data into . |
Random access memory
As mentioned above, there are two ways to access memory in Miden VM. The first way is via memory addresses using the instructions listed below. The addresses are absolute - i.e., they don't depend on the procedure context. Memory addresses can be in the range .
Memory is guaranteed to be initialized to zeros. Thus, when reading from memory address which hasn't been written to previously, zero elements will be returned.
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| mem_load - (1 cycle) mem_load.a - (2 cycles) | [a, ... ] | [v, ... ] | Reads the field element from memory at address a, and pushes it onto the stack. If is provided via the stack, it is removed from the stack first. Fails if |
| mem_loadw - (1 cycle) mem_loadw.a - (2 cycles) | [a, 0, 0, 0, 0, ... ] | [A, ... ] | Reads a word from memory starting at address and overwrites top four stack elements with it, in reverse order, such that mem[a+3] is on top of the stack. If is provided via the stack, it is removed from the stack first. Fails if , or if is not a multiple of 4 |
| mem_store - (2 cycles) mem_store.a - (3-4 cycles) | [a, v, ... ] | [ ... ] | Pops the top element off the stack and stores it in memory at address . If is provided via the stack, it is removed from the stack first. Fails if |
| mem_storew - (1 cycle) mem_storew.a - (2-3 cycles) | [a, A, ... ] | [A, ... ] | Stores the top four elements of the stack in reverse order in memory starting at address , such that the first element of A is placed at mem[a+3]. If is provided via the stack, it is removed from the stack first. Fails if , or if is not a multiple of 4 |
| mem_stream - (1 cycle) | [C, B, A, a, ... ] | [E, D, A, a', ... ] | Read two sequential words from memory starting at address and overwrites the first two words in the operand stack. |
The second way to access memory is via procedure locals using the instructions listed below. These instructions are available only in procedure context. The number of locals available to a given procedure must be specified at procedure declaration time, and trying to access more locals than was declared will result in a compile-time error. A procedure can have at most locals, and the total number of locals available to all procedures at runtime is limited to . The assembler internally always rounds up the number of declared locals to the nearest multiple of 4.
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| loc_load.i - (3-4 cycles) | [ ... ] | [v, ... ] | Reads a field element from local memory at index i, and pushes it onto the stack. |
| loc_loadw.i - (3-4 cycles) | [0, 0, 0, 0, ... ] | [A, ... ] | Reads a word from local memory starting at index and overwrites top four stack elements with it in reverse order, such that local[i+3] is placed at the top of the stack. Fails if is not a multiple 4. |
| loc_store.i - (4-5 cycles) | [v, ... ] | [ ... ] | Pops the top element off the stack and stores it in local memory at index . |
| loc_storew.i - (3-4 cycles) | [A, ... ] | [A, ... ] | Stores the top four elements of the stack in local memory in reverse order starting at index , such that the top of stack is placed at local[i+3]. |
Unlike regular memory, procedure locals are not guaranteed to be initialized to zeros. Thus, when working with locals, one must assume that before a local memory address has been written to, it contains "garbage".
Internally in the VM, procedure locals are stored at memory offset starting at . Thus, every procedure local has an absolute address in regular memory. The locaddr.i instruction is provided specifically to map an index of a procedure's local to an absolute address so that it can be passed to downstream procedures, when needed.
Cryptographic operations
Miden assembly provides a set of instructions for performing common cryptographic operations. These instructions are listed in the table below.
Hashing and Merkle trees
Rescue Prime Optimized is the native hash function of Miden VM. The parameters of the hash function were chosen to provide 128-bit security level against preimage and collision attacks. The function operates over a state of 12 field elements, and requires 7 rounds for a single permutation. However, due to its special status within the VM, computing Rescue Prime Optimized hashes can be done very efficiently. For example, applying a permutation of the hash function can be done in a single VM cycle.
| Instruction | Stack_input | Stack_output | Notes |
|---|---|---|---|
| hash - (20 cycles) | [A, ...] | [B, ...] | where, computes a 1-to-1 Rescue Prime Optimized hash. |
| hperm - (1 cycle) | [C, B, A, ...] | [F, E, D, ...] | Performs a Rescue Prime Optimized permutation on the top 3 words of the operand stack, where the top 2 words elements are the rate (words C and B), the deepest word is the capacity (word A), the digest output is the word E. |
| hmerge - (16 cycles) | [B, A, ...] | [C, ...] | where, computes a 2-to-1 Rescue Prime Optimized hash. |
| mtree_get - (9 cycles) | [d, i, R, ...] | [V, R, ...] | Fetches the node value from the advice provider and runs a verification equivalent to mtree_verify, returning the value if succeeded. |
| mtree_set - (29 cycles) | [d, i, R, V', ...] | [V, R', ...] | Updates a node in the Merkle tree with root at depth and index to value . is the Merkle root of the resulting tree and is old value of the node. Merkle tree with root must be present in the advice provider, otherwise execution fails. At the end of the operation the advice provider will contain both Merkle trees. |
| mtree_merge - (16 cycles) | [R, L, ...] | [M, ...] | Merges two Merkle trees with the provided roots R (right), L (left) into a new Merkle tree with root M (merged). The input trees are retained in the advice provider. |
| mtree_verify - (1 cycle) | [V, d, i, R, ...] | [V, d, i, R, ...] | Verifies that a Merkle tree with root opens to node at depth and index . Merkle tree with root must be present in the advice provider, otherwise execution fails. |
The mtree_verify instruction can also be parametrized with an error code which can be any 32-bit value specified either directly or via a named constant. For example:
mtree_verify.err=123
mtree_verify.err=MY_CONSTANT
If the error code is omitted, the default value of is assumed.
Events
Miden assembly supports the concept of events. Events are a simple data structure with a single event_id field. When an event is emitted by a program, it is communicated to the host. Events can be emitted at specific points of program execution with the intent of triggering some action on the host. This is useful as the program has contextual information that would be challenging for the host to infer. The emission of events allows the program to communicate this contextual information to the host. The host contains an event handler that is responsible for handling events and taking appropriate actions. The emission of events does not change the state of the VM but it can change the state of the host.
An event can be emitted via the emit.<event_id> assembly instruction where <event_id> can be any 32-bit value specified either directly or via a named constant. For example:
emit.EVENT_ID_1
emit.2
Tracing
Miden assembly also supports code tracing, which works similar to the event emitting.
A trace can be emitted via the trace.<trace_id> assembly instruction where <trace_id> can be any 32-bit value specified either directly or via a named constant. For example:
trace.EVENT_ID_1
trace.2
To make use of the trace instruction, programs should be ran with tracing flag (-t or --trace), otherwise these instructions will be ignored.
Debugging
To support basic debugging capabilities, Miden assembly provides a debug instruction. This instruction prints out the state of the VM at the time when the debug instruction is executed. The instruction can be parameterized as follows:
debug.stackprints out the entire contents of the stack.debug.stack.<n>prints out the top items of the stack. must be an integer greater than and smaller than .debug.memprints out the entire contents of RAM.debug.mem.<n>prints out contents of memory at address .debug.mem.<n>.<m>prints out the contents of memory starting at address and ending at address (both inclusive). must be greater or equal to .debug.localprints out the whole local memory of the currently executing procedure.debug.local.<n>prints out contents of the local memory at index for the currently executing procedure. must be greater or equal to and smaller than .debug.local.<n>.<m>prints out contents of the local memory starting at index and ending at index (both inclusive). must be greater or equal to . and must be greater or equal to and smaller than .
Debug instructions do not affect the VM state and do not change the program hash.
To make use of the debug instruction, programs must be compiled with an assembler instantiated in the debug mode. Otherwise, the assembler will simply ignore the debug instructions.
Miden Standard Library
Miden standard library provides a set of procedures which can be used by any Miden program. These procedures build on the core instruction set of Miden assembly expanding the functionality immediately available to the user.
The goals of Miden standard library are:
- Provide highly-optimized and battle-tested implementations of commonly-used primitives.
- Reduce the amount of code that needs to be shared between parties for proving and verifying program execution.
The second goal can be achieved because calls to procedures in the standard library can always be serialized as 32 bytes, regardless of how large the procedure is.
Terms and notations
In this document we use the following terms and notations:
- A field element is an element in a prime field of size .
- A binary value means a field element which is either or .
- Inequality comparisons are assumed to be performed on integer representations of field elements in the range .
Throughout this document, we use lower-case letters to refer to individual field elements (e.g., ). Sometimes it is convenient to describe operations over groups of elements. For these purposes we define a word to be a group of four elements. We use upper-case letters to refer to words (e.g., ). To refer to individual elements within a word, we use numerical subscripts. For example, is the first element of word , is the last element of word , etc.
Organization and usage
Procedures in the Miden Standard Library are organized into modules, each targeting a narrow set of functionality. Modules are grouped into higher-level namespaces. However, higher-level namespaces do not expose any procedures themselves. For example, std::math::u64 is a module containing procedures for working with 64-bit unsigned integers. This module is a part of the std::math namespace. However, the std::math namespace does not expose any procedures.
For an example of how to invoke procedures from imported modules see this section.
Available modules
Currently, Miden standard library contains just a few modules, which are listed below. Over time, we plan to add many more modules which will include various cryptographic primitives, additional numeric data types and operations, and many others.
| Module | Description |
|---|---|
| std::collections::mmr | Contains procedures for manipulating Merkle Mountain Ranges. |
| std::crypto::fri::frie2f4 | Contains procedures for verifying FRI proofs (field extension = 2, folding factor = 4). |
| std::crypto::hashes::blake3 | Contains procedures for computing hashes using BLAKE3 hash function. |
| std::crypto::hashes::sha256 | Contains procedures for computing hashes using SHA256 hash function. |
| std::math::u64 | Contains procedures for working with 64-bit unsigned integers. |
| std::mem | Contains procedures for working with random access memory. |
| std::sys | Contains system-level utility procedures. |
Collections
Namespace std::collections contains modules for commonly-used authenticated data structures. This includes:
- A Merkle Mountain range.
- A Sparse Merkle Tree with 64-bit keys.
- A Sparse Merkle Tree with 256-bit keys.
Merkle Mountain Range
Module std::collections::mmr contains procedures for manipulating Merkle Mountain Range data structure which can be used as an append-only log.
The following procedures are available to read data from and make updates to a Merkle Mountain Range.
| Procedure | Description |
|---|---|
| get | Loads the leaf at the absolute position pos in the MMR onto the stack.Valid range for pos is between and (both inclusive).Inputs: [pos, mmr_ptr, ...]Output: [N, ...]Where N is the leaf loaded from the MMR whose memory location starts at mmr_ptr. |
| add | Adds a new leaf to the MMR. This will update the MMR peaks in the VM's memory and the advice provider with any merged nodes. Inputs: [N, mmr_ptr, ...]Outputs: [...]Where N is the leaf added to the MMR whose memory locations starts at mmr_ptr. |
| pack | Computes a commitment to the given MMR and copies the MMR to the Advice Map using the commitment as a key. Inputs: [mmr_ptr, ...]Outputs: [HASH, ...] |
| unpack | Writes the MMR who's peaks hash to HASH to the memory location pointed to by mmr_ptr.Inputs: [HASH, mmr_ptr, ...]Outputs: [...]Where: - HASH: is the MMR peak hash, the hash is expected to be padded to an even length and to have a minimum size of 16 elements.- The advice map must contain a key with HASH, and its value is [num_leaves, 0, 0, 0] || hash_data, and hash_data is the data used to computed HASH- mmr_ptr: the memory location where the MMR data will be written, starting with the MMR forest (the total count of its leaves) followed by its peaks. The memory location must be word-aligned. |
mmr_ptr is a pointer to the mmr data structure, which is defined as:
mmr_ptr[0]contains the number of leaves in the MMRmmr_ptr[1..4]are padding and are ignoredmmr_ptr[4..8], mmr_ptr[8..12], ...contain the 1st MMR peak, 2nd MMR peak, etc.
Sparse Merkle Tree
Module std::collections::smt contains procedures for manipulating key-value maps with 4-element keys and 4-element values. The underlying implementation is a Sparse Merkle Tree where leaves can exist only at depth 64. Initially, when a tree is empty, it is equivalent to an empty Sparse Merkle Tree of depth 64 (i.e., leaves at depth 64 are set and hash to [ZERO; 4]). When inserting non-empty values into the tree, the most significant element of the key is used to identify the corresponding leaf. All key-value pairs that map to a given leaf are inserted (ordered) in the leaf.
The following procedures are available to read data from and make updates to a Sparse Merkle Tree.
| Procedure | Description |
|---|---|
| get | Returns the value located under the specified key in the Sparse Merkle Tree defined by the specified root. If no values had been previously inserted under the specified key, an empty word is returned. Inputs: [KEY, ROOT, ...]Outputs: [VALUE, ROOT, ...]Fails if the tree with the specified root does not exist in the VM's advice provider. |
| set | Inserts the specified value under the specified key in a Sparse Merkle Tree defined by the specified root. If the insert is successful, the old value located under the specified key is returned via the stack. If VALUE is an empty word, the new state of the tree is guaranteed to be equivalent to the state as if the updated value was never inserted.Inputs: [VALUE, KEY, ROOT, ...]Outputs: [OLD_VALUE, NEW_ROOT, ...]Fails if the tree with the specified root does not exits in the VM's advice provider. |
Digital signatures
Namespace std::crypto::dsa contains a set of digital signature schemes supported by default in the Miden VM. Currently, these schemes are:
RPO Falcon512: a variant of the Falcon signature scheme.
RPO Falcon512
Module std::crypto::dsa::rpo_falcon512 contains procedures for verifying RPO Falcon512 signatures. These signatures differ from the standard Falcon signatures in that instead of using SHAKE256 hash function in the hash-to-point algorithm we use RPO256. This makes the signature more efficient to verify in the Miden VM.
The module exposes the following procedures:
| Procedure | Description |
|---|---|
| verify | Verifies a signature against a public key and a message. The procedure gets as inputs the hash of the public key and the hash of the message via the operand stack. The signature is expected to be provided via the advice provider. The signature is valid if and only if the procedure returns. Stack inputs: [PK, MSG, ...]Advice stack inputs: [SIGNATURE]Outputs: [...]Where PK is the hash of the public key and MSG is the hash of the message, and SIGNATURE is the signature being verified. Both hashes are expected to be computed using RPO hash function. |
FRI verification procedures
Namespace std::crypto::fri contains modules for verifying FRI proofs.
FRI Extension 2, Fold 4
Module std::crypto::fri::frie2f4 contains procedures for verifying FRI proofs generated over the quadratic extension of the Miden VM's base field. Moreover, the procedures assume that layer folding during the commit phase of FRI protocol was performed using folding factor 4.
| Procedure | Description |
|---|---|
| verify | Verifies a FRI proof where the proof was generated over the quadratic extension of the base field and layer folding was performed using folding factor 4. Input: [query_start_ptr, query_end_ptr, layer_ptr, rem_ptr, g, ...]>Output: [...]- query_start_ptr is a pointer to a list of tuples of the form (e0, e1, p, 0) where p is a query index at the first layer and (e0, e1) is an extension field element corresponding to the value of the first layer at index p.- query_end_ptr is a pointer to the first empty memory address after the last (e0, e1, p, 0) tuple.- layer_ptr is a pointer to the first layer commitment denoted throughout the code by C. layer_ptr + 1 points to the first (alpha0, alpha1, t_depth, d_size) where d_size is the size of initial domain divided by 4, t_depth is the depth of the Merkle tree commitment to the first layer and (alpha0, alpha1) is the first challenge used in folding the first layer. Both t_depth and d_size are expected to be smaller than 2^32. Otherwise, the result of this procedure is undefined.- rem_ptr is a pointer to the first tuple of two consecutive degree 2 extension field elements making up the remainder codeword. This codeword can be of length either 32 or 64.The memory referenced above is used contiguously, as follows: [layer_ptr ... rem_ptr ... query_start_ptr ... query_end_ptr]This means for example that: 1. rem_ptr - 1 points to the last (alpha0, alpha1, t_depth, d_size) tuple.2. The length of the remainder codeword is 2 * (rem_ptr - query_start_ptr).Cycles: for domains of size 2^n where:- n is even: 12 + 6 + num_queries * (40 + num_layers * 76 + 69) + 2626- n is odd: 12 + 6 + num_queries * (40 + num_layers * 76 + 69) + 1356 |
Cryptographic hashes
Namespace std::crypto contains modules for commonly used cryptographic hash functions.
BLAKE3
Module std::crypto::hashes::blake3 contains procedures for computing hashes using BLAKE3 hash function. The input and output elements are assumed to contain one 32-bit value per element.
| Procedure | Description |
|---|---|
| hash_1to1 | Computes BLAKE3 1-to-1 hash. Input: 32-bytes stored in the first 8 elements of the stack (32 bits per element). Output: A 32-byte digest stored in the first 8 elements of stack (32 bits per element). |
| hash_2to1 | Computes BLAKE3 2-to-1 hash. Input: 64-bytes stored in the first 16 elements of the stack (32 bits per element). Output: A 32-byte digest stored in the first 8 elements of stack (32 bits per element) |
SHA256
Module std::crypto::hashes::sha256 contains procedures for computing hashes using SHA256 hash function. The input and output elements are assumed to contain one 32-bit value per element.
| Procedure | Description |
|---|---|
| hash_1to1 | Computes SHA256 1-to-1 hash. Input: 32-bytes stored in the first 8 elements of the stack (32 bits per element). Output: A 32-byte digest stored in the first 8 elements of stack (32 bits per element). |
| hash_2to1 | Computes SHA256 2-to-1 hash. Input: 64-bytes stored in the first 16 elements of the stack (32 bits per element). Output: A 32-byte digest stored in the first 8 elements of stack (32 bits per element). |
Unsigned 64-bit integer operations
Module std::math::u64 contains a set of procedures which can be used to perform unsigned 64-bit integer operations. These operations fall into the following categories:
- Arithmetic operations - addition, multiplication, division etc.
- Comparison operations - equality, less than, greater than etc.
- Bitwise operations - binary AND, OR, XOR, bit shifts etc.
All procedures assume that an unsigned 64-bit integer (u64) is encoded using two elements, each containing an unsigned 32-bit integer (u32). When placed on the stack, the least-significant limb is assumed to be deeper in the stack. For example, a u64 value a consisting of limbs a_hi and a_lo would be position on the stack like so:
[a_hi, a_lo, ... ]
Many of the procedures listed below (e.g., overflowing_add, wrapping_add, lt) do not check whether the inputs are encoded using valid u32 values. These procedures do not fail when the inputs are encoded incorrectly, but rather produce undefined results. Thus, it is important to be certain that limbs of input values are valid u32 values prior to calling such procedures.
Arithmetic operations
| Procedure | Description |
|---|---|
| overflowing_add | Performs addition of two unsigned 64-bit integers preserving the overflow. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [overflow_flag, c_hi, c_lo, ...], where c = (a + b) % 2^64 This takes 6 cycles. |
| wrapping_add | Performs addition of two unsigned 64-bit integers discarding the overflow. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = (a + b) % 2^64 This takes 7 cycles. |
| overflowing_sub | Performs subtraction of two unsigned 64-bit integers preserving the overflow. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [underflow_flag, c_hi, c_lo, ...], where c = (a - b) % 2^64 This takes 11 cycles. |
| wrapping_sub | Performs subtraction of two unsigned 64-bit integers discarding the overflow. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = (a - b) % 2^64 This takes 10 cycles. |
| overflowing_mul | Performs multiplication of two unsigned 64-bit integers preserving the overflow. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c_hi_hi, c_hi_lo, c_lo_hi, c_lo_lo, ...], where c = (a * b) % 2^64 This takes 18 cycles. |
| wrapping_mul | Performs multiplication of two unsigned 64-bit integers discarding the overflow. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = (a * b) % 2^64 This takes 11 cycles. |
| div | Performs division of two unsigned 64-bit integers discarding the remainder. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = a // b This takes 54 cycles. |
| mod | Performs modulo operation of two unsigned 64-bit integers. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = a % b This takes 54 cycles. |
| divmod | Performs divmod operation of two unsigned 64-bit integers. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [r_hi, r_lo, q_hi, q_lo ...], where r = a % b, q = a // b This takes 54 cycles. |
Comparison operations
| Procedure | Description |
|---|---|
| lt | Performs less-than comparison of two unsigned 64-bit integers. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c, ...], where c = 1 when a < b, and 0 otherwise. This takes 11 cycles. |
| gt | Performs greater-than comparison of two unsigned 64-bit integers. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c, ...], where c = 1 when a > b, and 0 otherwise. This takes 11 cycles. |
| lte | Performs less-than-or-equal comparison of two unsigned 64-bit integers. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c, ...], where c = 1 when a <= b, and 0 otherwise. This takes 12 cycles. |
| gte | Performs greater-than-or-equal comparison of two unsigned 64-bit integers. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c, ...], where c = 1 when a >= b, and 0 otherwise. This takes 12 cycles. |
| eq | Performs equality comparison of two unsigned 64-bit integers. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c, ...], where c = 1 when a == b, and 0 otherwise. This takes 6 cycles. |
| neq | Performs inequality comparison of two unsigned 64-bit integers. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c, ...], where c = 1 when a != b, and 0 otherwise. This takes 6 cycles. |
| eqz | Performs comparison to zero of an unsigned 64-bit integer. The input value is assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [a_hi, a_lo, ...] -> [c, ...], where c = 1 when a == 0, and 0 otherwise. This takes 4 cycles. |
| min | Compares two unsigned 64-bit integers and drop the larger one from the stack. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = a when a < b, and b otherwise. This takes 23 cycles. |
| max | Compares two unsigned 64-bit integers and drop the smaller one from the stack. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = a when a > b, and b otherwise. This takes 23 cycles. |
Bitwise operations
| Procedure | Description |
|---|---|
| and | Performs bitwise AND of two unsigned 64-bit integers. The input values are assumed to be represented using 32-bit limbs, but this is not checked. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = a AND b. This takes 6 cycles. |
| or | Performs bitwise OR of two unsigned 64-bit integers. The input values are expected to be represented using 32-bit limbs, and the procedure will fail if they are not. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = a OR b. This takes 16 cycles. |
| xor | Performs bitwise XOR of two unsigned 64-bit integers. The input values are expected to be represented using 32-bit limbs, and the procedure will fail if they are not. The stack transition looks as follows: [b_hi, b_lo, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = a XOR b. This takes 6 cycles. |
| shl | Performs left shift of one unsigned 64-bit integer using the pow2 operation. The input value to be shifted is assumed to be represented using 32-bit limbs. The shift value should be in the range [0, 64), otherwise it will result in an error. The stack transition looks as follows: [b, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = a << b mod 2^64. This takes 28 cycles. |
| shr | Performs right shift of one unsigned 64-bit integer using the pow2 operation. The input value to be shifted is assumed to be represented using 32-bit limbs. The shift value should be in the range [0, 64), otherwise it will result in an error. The stack transition looks as follows: [b, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = a >> b. This takes 44 cycles. |
| rotl | Performs left rotation of one unsigned 64-bit integer using the pow2 operation. The input value to be shifted is assumed to be represented using 32-bit limbs. The shift value should be in the range [0, 64), otherwise it will result in an error. The stack transition looks as follows: [b, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = a << b mod 2^64. This takes 35 cycles. |
| rotr | Performs right rotation of one unsigned 64-bit integer using the pow2 operation. The input value to be shifted is assumed to be represented using 32-bit limbs. The shift value should be in the range [0, 64), otherwise it will result in an error. The stack transition looks as follows: [b, a_hi, a_lo, ...] -> [c_hi, c_lo, ...], where c = a << b mod 2^64. This takes 40 cycles. |
| clz | Counts the number of leading zeros of one unsigned 64-bit integer. The input value is assumed to be represented using 32 bit limbs, but this is not checked. The stack transition looks as follows: [n_hi, n_lo, ...] -> [clz, ...], where clz is a number of leading zeros of value n.This takes 43 cycles. |
| ctz | Counts the number of trailing zeros of one unsigned 64-bit integer. The input value is assumed to be represented using 32 bit limbs, but this is not checked. The stack transition looks as follows: [n_hi, n_lo, ...] -> [ctz, ...], where ctz is a number of trailing zeros of value n.This takes 41 cycles. |
| clo | Counts the number of leading ones of one unsigned 64-bit integer. The input value is assumed to be represented using 32 bit limbs, but this is not checked. The stack transition looks as follows: [n_hi, n_lo, ...] -> [clo, ...], where clo is a number of leading ones of value n.This takes 42 cycles. |
| cto | Counts the number of trailing ones of one unsigned 64-bit integer. The input value is assumed to be represented using 32 bit limbs, but this is not checked. The stack transition looks as follows: [n_hi, n_lo, ...] -> [cto, ...], where cto is a number of trailing ones of value n.This takes 40 cycles. |
Memory procedures
Module std::mem contains a set of utility procedures for working with random access memory.
| Procedure | Description |
|---|---|
| memcopy_words | Copies n words from read_ptr to write_ptr; both pointers must be word-aligned.Stack transition looks as follows: [n, read_ptr, write_ptr, ...] -> [...] Cycles: 15 + 16n |
| pipe_double_words_to_memory | Moves an even number of words from the advice stack to memory. Input: [C, B, A, write_ptr, end_ptr, ...] Output: [C, B, A, write_ptr, ...] Where: - The words C, B, and A are the RPO hasher state - A is the capacity - C, B are the rate portion of the state - The value num_words = end_ptr - write_ptr must be positive and evenCycles: 10 + 9 * num_words / 2 |
| pipe_words_to_memory | Moves an arbitrary number of words from the advice stack to memory. Input: [num_words, write_ptr, ...] Output: [HASH, write_ptr', ...] Where HASH is the sequential RPO hash of all copied words.Cycles: - Even num_words: 48 + 9 * num_words / 2 - Odd num_words: 65 + 9 * round_down(num_words / 2) |
| pipe_preimage_to_memory | Moves an arbitrary number of words from the advice stack to memory and asserts it matches the commitment. Input: [num_words, write_ptr, COM, ...] Output: [write_ptr', ...] Cycles: - Even num_words: 58 + 9 * num_words / 2 - Odd num_words: 75 + 9 * round_down(num_words / 2) |
System procedures
Module std::sys contains a set of system-level utility procedures.
| Procedure | Description |
|---|---|
| truncate_stack | Removes elements deep in the stack until the depth of the stack is exactly 16. The elements are removed in such a way that the top 16 elements of the stack remain unchanged. If the stack would otherwise contain more than 16 elements at the end of execution, then adding a call to this function at the end will reduce the size of the public inputs that are shared with the verifier. Input: Stack with 16 or more elements. Output: Stack with only the original top 16 elements. |
Design
In the following sections, we provide in-depth descriptions of Miden VM internals, including all AIR constraints for the proving system. We also provide rationale for making specific design choices.
Throughout these sections we adopt the following notations and assumptions:
- All arithmetic operations, unless noted otherwise, are assumed to be in a prime field with modulus .
- A binary value means a field element which is either or .
- We use lowercase letters to refer to individual field elements (e.g., ), and uppercase letters to refer to groups of elements, also referred to as words (e.g., ). To refer to individual elements within a word, we use numerical subscripts. For example, is the first element of word , is the last element of word , etc.
- When describing AIR constraints:
- For a column , we denote the value in the current row simply as , and the value in the next row of the column as . Thus, all transition constraints for Miden VM work with two consecutive rows of the execution trace.
- For multiset equality constraints, we denote random values sent by the verifier after the prover commits to the main execution trace as etc.
- To differentiate constraints from other formulas, we frequently use the following format for constraint equations.
In the above, the constraint equation is followed by the implied algebraic degree of the constraint. This degree is determined by the number of multiplications between trace columns. If a constraint does not involve any multiplications between columns, its degree is . If a constraint involves multiplication between two columns, its degree is . If we need to multiply three columns together, the degree is ect.
The maximum allowed constraint degree in Miden VM is . If a constraint degree grows beyond that, we frequently need to introduce additional columns to reduce the degree.
VM components
Miden VM consists of several interconnected components, each providing a specific set of functionality. These components are:
- System, which is responsible for managing system data, including the current VM cycle (
clk), the free memory pointer (fmp) used for specifying the region of memory available to procedure locals, and the current and parent execution contexts. - Program decoder, which is responsible for computing a commitment to the executing program and converting the program into a sequence of operations executed by the VM.
- Operand stack, which is a push-down stack which provides operands for all operations executed by the VM.
- Range checker, which is responsible for providing 16-bit range checks needed by other components.
- Chiplets, which is a set of specialized circuits used to accelerate commonly-used complex computations. Currently, the VM relies on 4 chiplets:
- Hash chiplet, used to compute Rescue Prime Optimized hashes both for sequential hashing and for Merkle tree hashing.
- Bitwise chiplet, used to compute bitwise operations (e.g.,
AND,XOR) over 32-bit integers. - Memory chiplet, used to support random-access memory in the VM.
- Kernel ROM chiplet, used to enable calling predefined kernel procedures which are provided before execution begins.
The above components are connected via buses, which are implemented using lookup arguments. We also use multiset check lookups internally within components to describe virtual tables.
VM execution trace
The execution trace of Miden VM consists of main trace columns, buses, and virtual tables, as shown in the diagram below.
As can be seen from the above, the system, decoder, stack, and range checker components use dedicated sets of columns, while all chiplets share the same columns. To differentiate between chiplets, we use a set of binary selector columns, a combination of which uniquely identifies each chiplet.
The system component does not yet have a dedicated documentation section, since the design is likely to change. However, the following two columns are not expected to change:
clkwhich is used to keep track of the current VM cycle. Values in this column start out at and are incremented by with each cycle.fmpwhich contains the value of the free memory pointer used for specifying the region of memory available to procedure locals.
AIR constraints for the fmp column are described in system operations section. For the clk column, the constraints are straightforward:
Programs in Miden VM
Miden VM consumes programs in a form of a Merkelized Abstract Syntax Tree (MAST). This tree is a binary tree where each node is a code block. The VM starts execution at the root of the tree, and attempts to recursively execute each required block according to its semantics. If the execution of a code block fails, the VM halts at that point and no further blocks are executed. A set of currently available blocks and their execution semantics are described below.
Code blocks
Join block
A join block is used to describe sequential execution. When the VM encounters a join block, it executes its left child first, and then executes its right child.
A join block must always have two children, and thus, cannot be a leaf node in the tree.
Split block
A split block is used to describe conditional execution. When the VM encounters a split block, it checks the top of the stack. If the top of the stack is , it executes the left child, if the top of the stack is , it executes the right child. If the top of the stack is neither nor , the execution fails.
A split block must always have two children, and thus, cannot be a leaf node in the tree.
Loop block
A loop block is used to describe condition-based iterative execution. When the VM encounters a loop block, it checks the top of the stack. If the top of the stack is , it executes the loop body, if the top of the stack is , the block is not executed. If the top of the stack is neither nor , the execution fails.
After the body of the loop is executed, the VM checks the top of the stack again. If the top of the stack is , the body is executed again, if the top of the stack is , the loop is exited. If the top of the stack is neither nor , the execution fails.
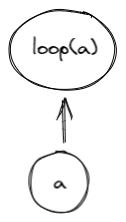
A loop block must always have one child, and thus, cannot be a leaf node in the tree.
Dyn block
A dyn block is used to describe a node whose target is specified dynamically via the stack. When the VM encounters a dyn block, it executes a program which hashes to the target specified by the top of the stack. Thus, it has a dynamic target rather than a hardcoded target. In order to execute a dyn block, the VM must be aware of a program with the hash value that is specified by the top of the stack. Otherwise, the execution fails.
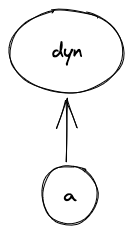
A dyn block must always have one (dynamically-specified) child. Thus, it cannot be a leaf node in the tree.
Call block
A call block is used to describe a function call which is executed in a user context. When the VM encounters a call block, it creates a new user context, then executes a program which hashes to the target specified by the call block in the new context. Thus, in order to execute a call block, the VM must be aware of a program with the specified hash. Otherwise, the execution fails. At the end of the call block, execution returns to the previous context.
When executing a call block, the VM does the following:
- Checks if a syscall is already being executed and fails if so.
- Sets the depth of the stack to 16.
- Upon return, checks that the depth of the stack is 16. If so, the original stack depth is restored. Otherwise, an error occurs.
A call block does not have any children. Thus, it must be leaf node in the tree.
Syscall block
A syscall block is used to describe a function call which is executed in the root context. When the VM encounters a syscall block, it returns to the root context, then executes a program which hashes to the target specified by the syscall block. Thus, in order to execute a syscall block, the VM must be aware of a program with the specified hash, and that program must belong to the kernel against which the code is compiled. Otherwise, the execution fails. At the end of the syscall block, execution returns to the previous context.
When executing a syscall block, the VM does the following:
- Checks if a syscall is already being executed and fails if so.
- Sets the depth of the stack to 16.
- Upon return, checks that the depth of the stack is 16. If so, the original stack depth is restored. Otherwise, an error occurs.
A syscall block does not have any children. Thus, it must be leaf node in the tree.
Span block
A span block is used to describe a linear sequence of operations. When the VM encounters a span block, it breaks the sequence of operations into batches and groups according to the following rules:
- A group is represented by a single field element. Thus, assuming a single operation can be encoded using 7 bits, and assuming we are using a 64-bit field, a single group may encode up to 9 operations or a single immediate value.
- A batch is a set of groups which can be absorbed by a hash function used by the VM in a single permutation. For example, assuming the hash function can absorb up to 8 field elements in a single permutation, a single batch may contain up to 8 groups.
- There is no limit on the number of batches contained within a single span.
Thus, for example, executing 8 pushes in a row will result in two operation batches as illustrated in the picture below:
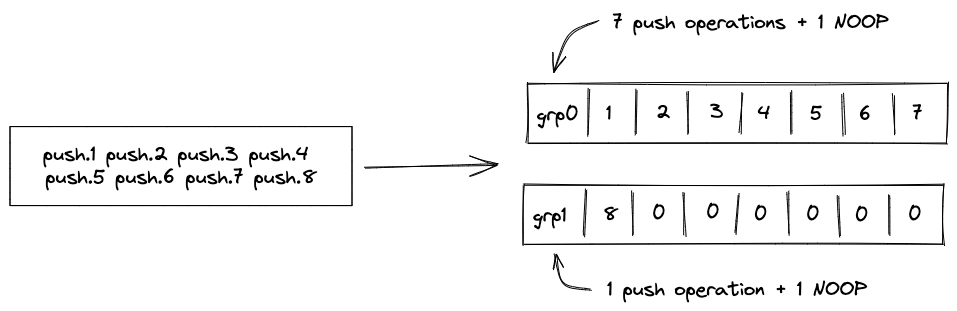
- The first batch will contain 8 groups, with the first group containing 7
PUSHopcodes and 1NOOP, and the remaining 7 groups containing immediate values for each of the push operations. The reason for theNOOPis explained later in this section. - The second batch will contain 2 groups, with the first group containing 1
PUSHopcode and 1NOOP, and the second group containing the immediate value for the last push operation.
If a sequence of operations does not have any operations which carry immediate values, up to 72 operations can fit into a single batch.
From the user's perspective, all operations are executed in order, however, the VM may insert occasional NOOPs to ensure proper alignment of all operations in the sequence. Currently, the alignment requirements are as follows:
- An operation carrying an immediate value cannot be the last operation in a group. Thus, for example, if a
PUSHoperation is the last operation in a group, the VM will insert aNOOPafter it.
A span block does not have any children, and thus, must be leaf node in the tree.
Program example
Consider the following program, where , etc. represent individual operations:
a_0, ..., a_i
if.true
b_0, ..., b_j
else
c_0, ..., c_k
while.true
d_0, ..., d_n
end
e_0, ..., e_m
end
f_0, ..., f_l
A MAST for this program would look as follows:

Execution of this program would proceed as follows:
- The VM will start execution at the root of the program which is block .
- Since, is a join block, the VM will attempt to execute block first, and only after that execute block .
- Block is also a join block, and thus, the VM will execute block by executing operations in sequence, and then execute block .
- Block is a split block, and thus, the VM will pop the value off the top of the stack. If the popped value is , operations from block will be executed in sequence. If the popped value is , then the VM will attempt to execute block .
- is a join block, thus, the VM will try to execute block first, and then execute operations from block .
- Block is also a join_block, and thus, the VM will first execute all operations in block , and then will attempt to execute block .
- Block is a loop block, thus, the VM will pop the value off the top of the stack. If the pooped value is , the VM will execute the body of the loop defined by block . If the popped value is , the VM will not execute block and instead will move up the tree executing first block , then .
- If the VM does enter the loop, then after operation is executed, the VM will pop the value off the top of the stack again. If the popped value is , the VM will execute block again, and again until the top of the stack becomes . Once the top of the stack becomes , the VM will exit the loop and will move up the tree executing first block , then .
Program hash computation
Every Miden VM program can be reduced to a unique hash value. Specifically, it is infeasible to find two Miden VM programs with distinct semantics which hash to the same value. Padding a program with NOOPs does not change a program's execution semantics, and thus, programs which differ only in the number and/or placement of NOOPs may hash to the same value, although in most cases padding with NOOP should not affect program hash.
To prevent program hash collisions we implement domain separation across the variants of control blocks. We define the domain value to be the opcode of the operation that initializes the control block.
Below we denote to be an arithmetization-friendly hash function with -element output and capable of absorbing elements in a single permutation. The hash domain is specified as the subscript of the hash function and its value is used to populate the second capacity register upon initialization of control block hashing - .
- The hash of a join block is computed as , where and are hashes of the code block being joined.
- The hash of a split block is computed as , where is a hash of a code block corresponding to the true branch of execution, and is a hash of a code block corresponding to the false branch of execution.
- The hash of a loop block is computed as , where is a hash of a code block corresponding to the loop body.
- The hash of a dyn block is set to a constant, so it is the same for all dyn blocks. It does not depend on the hash of the dynamic child. This constant is computed as the RPO hash of two empty words (
[ZERO, ZERO, ZERO, ZERO]) using a domain value ofDYN_DOMAIN, whereDYN_DOMAINis the op code of theDynoperation. - The hash of a call block is computed as , where is a hash of a program of which the VM is aware.
- The hash of a syscall block is computed as , where is a hash of a program belonging to the kernel against which the code was compiled.
- The hash of a span block is computed as , where is the th batch of operations in the span block. Each batch of operations is defined as containing field elements, and thus, hashing a -batch span block requires absorption steps.
- In cases when the number of operations is insufficient to fill the last batch entirely,
NOOPsare appended to the end of the last batch to ensure that the number of operations in the batch is always equal to .
- In cases when the number of operations is insufficient to fill the last batch entirely,
Miden VM Program decoder
Miden VM program decoder is responsible for ensuring that a program with a given MAST root is executed by the VM. As the VM executes a program, the decoder does the following:
- Decodes a sequence of field elements supplied by the prover into individual operation codes (or opcodes for short).
- Organizes the sequence of field elements into code blocks, and computes the hash of the program according to the methodology described here.
At the end of program execution, the decoder outputs the computed program hash. This hash binds the sequence of opcodes executed by the VM to a program the prover claims to have executed. The verifier uses this hash during the STARK proof verification process to verify that the proof attests to a correct execution of a specific program (i.e., the prover didn't claim to execute program while in fact executing a different program ).
The sections below describe how Miden VM decoder works. Throughout these sections we make the following assumptions:
- An opcode requires bits to represent.
- An immediate value requires one full field element to represent.
- A
NOOPoperation has a numeric value of , and thus, can be encoded as seven zeros. Executing aNOOPoperation does not change the state of the VM, but it does advance operation counter, and may affect program hash.
Program execution
Miden VM programs consist of a set of code blocks organized into a binary tree. The leaves of the tree contain linear sequences of instructions, and control flow is defined by the internal nodes of the tree.
Managing control flow in the VM is accomplished by executing control flow operations listed in the table below. Each of these operations requires exactly one VM cycle to execute.
| Operation | Description |
|---|---|
JOIN | Initiates processing of a new Join block. |
SPLIT | Initiates processing of a new Split block. |
LOOP | Initiates processing of a new Loop block. |
REPEAT | Initiates a new iteration of an executing loop. |
SPAN | Initiates processing of a new Span block. |
RESPAN | Initiates processing of a new operation batch within a span block. |
DYN | Initiates processing of a new Dyn block. |
CALL | Initiates processing of a new Call block. |
SYSCALL | Initiates processing ofa new Syscall block. |
END | Marks the end of a program block. |
HALT | Marks the end of the entire program. |
Let's consider a simple program below:
begin
<operations1>
if.true
<operations2>
else
<operations3>
end
end
Block structure of this program is shown below.
JOIN
SPAN
<operations1>
END
SPLIT
SPAN
<operations2>
END
SPAN
<operations3>
END
END
END
Executing this program on the VM can result in one of two possible instruction sequences. First, if after operations in <operations1> are executed the top of the stack is , the VM will execute the following:
JOIN
SPAN
<operations1>
END
SPLIT
SPAN
<operations2>
END
END
END
HALT
However, if after <operations1> are executed, the top of the stack is , the VM will execute the following:
JOIN
SPAN
<operations1>
END
SPLIT
SPAN
<operations3>
END
END
END
HALT
The main task of the decoder is to output exactly the same program hash, regardless of which one of the two possible execution paths was taken. However, before we can describe how this is achieved, we need to give an overview of the overall decoder structure.
Decoder structure
The decoder is one of the more complex parts of the VM. It consists of the following components:
- Main execution trace consisting of trace columns which contain the state of the decoder at a given cycle of a computation.
- Connection to the hash chiplet, which is used to offload hash computations from the decoder.
- virtual tables (implemented via multi-set checks), which keep track of code blocks and operations executing on the VM.
Decoder trace
Decoder trace columns can be grouped into several logical sets of registers as illustrated below.

These registers have the following meanings:
- Block address register . This register contains address of the hasher for the current block (row index from the auxiliary hashing table). It also serves the role of unique block identifiers. This is convenient, because hasher addresses are guaranteed to be unique.
- Registers , which encode opcodes for operation to be executed by the VM. Each of these registers can contain a single binary value (either or ). And together these values describe a single opcode.
- Hasher registers . When control flow operations are executed, these registers are used to provide inputs for the current block's hash computation (e.g., for
JOIN,SPLIT,LOOP,SPAN,CALL,SYSCALLoperations) or to record the result of the hash computation (i.e., forENDoperation). However, when regular operations are executed, of these registers are used to help with op group decoding, and the remaining can be used to hold operation-specific helper variables. - Register which contains a binary flag indicating whether the VM is currently executing instructions inside a span block. The flag is set to when the VM executes non-control flow instructions, and is set to otherwise.
- Register which keeps track of the number of unprocessed operation groups in a given span block.
- Register which keeps track of a currently executing operation's index within its operation group.
- Operation batch flags which indicate how many operation groups a given operation batch contains. These flags are set only for
SPANandRESPANoperations, and are set to 's otherwise. - Two additional registers (not shown) are used primarily for constraint degree reduction.
Program block hashing
To compute hashes of program blocks, the decoder relies on the hash chiplet. Specifically, the decoder needs to perform two types of hashing operations:
- A simple 2-to-1 hash, where we provide a sequence of field elements, and get back field elements representing the result. Computing such a hash requires rows in the hash chiplet.
- A sequential hash of elements. Computing such a hash requires multiple absorption steps, and at each step field elements are absorbed into the hasher. Thus, computing a sequential hash of elements requires rows in the hash chiplet. At the end, we also get field elements representing the result.
To make hashing requests to the hash chiplet and to read the results from it, we will need to divide out relevant values from the chiplets bus column as described below.
Simple 2-to-1 hash
To initiate a 2-to-1 hash of elements () we need to divide by the following value:
where:
- is a label indicating beginning of a new permutation. Value of this label is computed based on hash chiplet selector flags according to the methodology described here.
- is the address of the row at which the hashing begins.
- Some values are skipped in the above (e.g., ) because of the specifics of how auxiliary hasher table rows are reduced to field elements (described here). For example, is used as a coefficient for node index values during Merkle path computations in the hasher, and thus, is not relevant in this case. The term is omitted when the number of items being hashed is a multiple of the rate width () because it is multiplied by 0 - the value of the first capacity register as determined by the hasher chiplet logic.
To read the -element result (), we need to divide by the following value:
where:
- is a label indicating return of the hash value. Value of this label is computed based on hash chiplet selector flags according to the methodology described here.
- is the address of the row at which the hashing began.
Sequential hash
To initiate a sequential hash of elements (), we need to divide by the following value:
This also absorbs the first elements of the sequence into the hasher state. Then, to absorb the next sequence of elements (e.g., ), we need to divide by the following value:
Where is a label indicating absorption of more elements into the hasher state. Value of this label is computed based on hash chiplet selector flags according to the methodology described here.
We can keep absorbing elements into the hasher in the similar manner until all elements have been absorbed. Then, to read the result (e.g., ), we need to divide by the following value:
Thus, for example, if , the result will of the hash will be available at hasher row .
Control flow tables
In addition to the hash chiplet, control flow operations rely on virtual tables: block stack table, block hash table, and op group table. These tables are virtual in that they don't require separate trace columns. Their state is described solely by running product columns: , , and . The tables are described in the following sections.
Block stack table
When the VM starts executing a new program block, it adds its block ID together with the ID of its parent block (and some additional info) to the block stack table. When a program block is fully executed, it is removed from the table. In this way, the table represents a stack of blocks which are currently executing on the VM. By the time program execution completes, block stack table must be empty.
The block stack table is also used to ensure that execution contexts are managed properly across the CALL and SYSCALL operations.
The table can be thought of as consisting of columns as shown below:
where:
- The first column () contains the ID of the block.
- The second column () contains the ID of the parent block. If the block has no parent (i.e., it is a root block of the program), parent ID is 0.
- The third column () contains a binary value which is set to is the block is a loop block, and to otherwise.
- The following 8 columns are only set to non-zero values for
CALLandSYSCALLoperations. They save all the necessary information to be able to restore the parent context properly upon the correspondingENDoperation- the
prnt_b0andprnt_b1columns refer to the stack helper columns B0 and B1 (current stack depth and last overflow address, respectively)
- the
In the above diagram, the first 2 rows correspond to 2 different CALL operations. The first CALL operation is called from the root context, and hence its parent fn hash is the zero hash. Additionally, the second CALL operation has a parent fn hash of [h0, h1, h2, h3], indicating that the first CALL was to a procedure with that hash.
Running product column is used to keep track of the state of the table. At any step of the computation, the current value of defines which rows are present in the table.
To reduce a row in the block stack table to a single value, we compute the following.
where are the random values provided by the verifier.
Block hash table
When the VM starts executing a new program block, it adds hashes of the block's children to the block hash table. And when the VM finishes executing a block, it removes its hash from the block hash table. Thus, by the time program execution completes, block hash table must be empty.
The table can be thought of as consisting of columns as shown below:
where:
- The first column () contains the ID of the block's parent. For program root, parent ID is .
- The next columns () contain the hash of the block.
- The next column () contains a binary value which is set to if the block is the first child of a join block, and to otherwise.
- The last column () contains a binary value which is set to if the block is a body of a loop, and to otherwise.
Running product column is used to keep track of the state of the table. At any step of the computation, the current value of defines which rows are present in the table.
To reduce a row in the block hash table to a single value, we compute the following.
Where are the random values provided by the verifier.
Unlike other virtual tables, block hash table does not start out in an empty state. Specifically, it is initialized with a single row containing the hash of the program's root block. This needs to be done because the root block does not have a parent and, thus, otherwise it would never be added to the block hash table.
Initialization of the block hash table is done by setting the initial value of to the value of the row containing the hash of a program's root block.
Op group table
Op group table is used in decoding of span blocks, which are leaves in a program's MAST. As described here, a span block can contain one or more operation batches, each batch containing up to operation groups.
When the VM starts executing a new batch of operations, it adds all operation groups within a batch, except for the first one, to the op group table. Then, as the VM starts executing an operation group, it removes the group from the table. Thus, by the time all operation groups in a batch have been executed, the op group table must be empty.
The table can be thought of as consisting of columns as shown below:
The meaning of the columns is as follows:
- The first column () contains operation batch ID. During the execution of the program, each operation batch is assigned a unique ID.
- The second column () contains the position of the group in the span block (not just in the current batch). The position is -based and is counted from the end. Thus, for example, if a span block consists of a single batch with groups, the position of the first group would be , the position of the second group would be etc. (the reason for this is explained in this section). Note that the group with position is not added to the table, because it is the first group in the batch, so the first row of the table will be for the group with position .
- The third column () contains the actual values of operation groups (this could include up to opcodes or a single immediate value).
Permutation column is used to keep track of the state of the table. At any step of the computation, the current value of defines which rows are present in the table.
To reduce a row in the op group table to a single value, we compute the following.
Where are the random values provided by the verifier.
Control flow operation semantics
In this section we describe high-level semantics of executing all control flow operations. The descriptions are not meant to be complete and omit some low-level details. However, they provide good intuition on how these operations work.
JOIN operation
Before a JOIN operation is executed by the VM, the prover populates registers with hashes of left and right children of the join program block as shown in the diagram below.
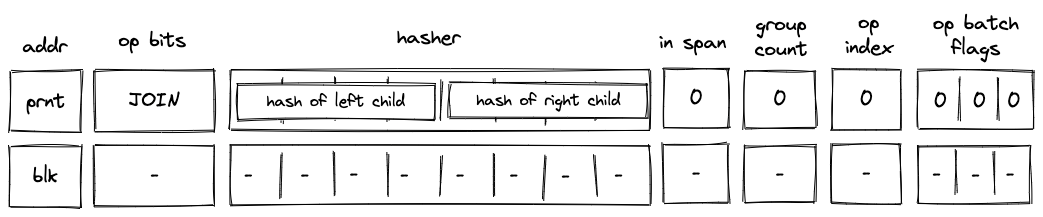
In the above diagram, blk is the ID of the join block which is about to be executed. blk is also the address of the hasher row in the auxiliary hasher table. prnt is the ID of the block's parent.
When the VM executes a JOIN operation, it does the following:
- Adds a tuple
(blk, prnt, 0, 0...)to the block stack table. - Adds tuples
(blk, left_child_hash, 1, 0)and(blk, right_child_hash, 0, 0)to the block hash table. - Initiates a 2-to-1 hash computation in the hash chiplet (as described here) using
blkas row address in the auxiliary hashing table and as input values.
SPLIT operation
Before a SPLIT operation is executed by the VM, the prover populates registers with hashes of true and false branches of the split program block as shown in the diagram below.
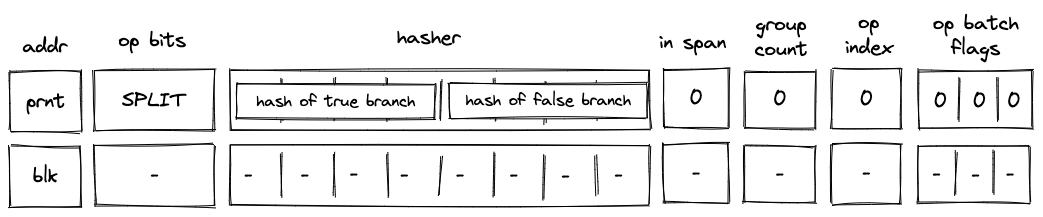
In the above diagram, blk is the ID of the split block which is about to be executed. blk is also the address of the hasher row in the auxiliary hasher table. prnt is the ID of the block's parent.
When the VM executes a SPLIT operation, it does the following:
- Adds a tuple
(blk, prnt, 0, 0...)to the block stack table. - Pops the stack and:
a. If the popped value is , adds a tuple(blk, true_branch_hash, 0, 0)to the block hash table.
b. If the popped value is , adds a tuple(blk, false_branch_hash, 0, 0)to the block hash table.
c. If the popped value is neither nor , the execution fails. - Initiates a 2-to-1 hash computation in the hash chiplet (as described here) using
blkas row address in the auxiliary hashing table and as input values.
LOOP operation
Before a LOOP operation is executed by the VM, the prover populates registers with hash of the loop's body as shown in the diagram below.
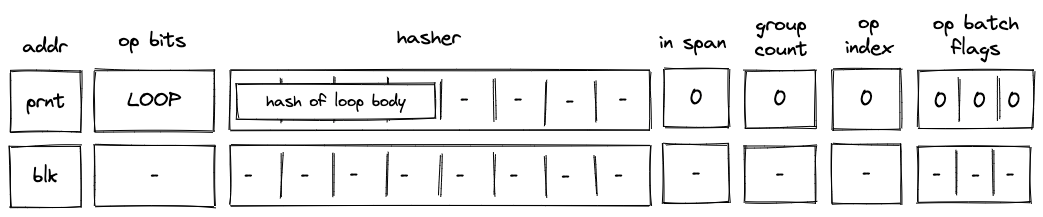
In the above diagram, blk is the ID of the loop block which is about to be executed. blk is also the address of the hasher row in the auxiliary hasher table. prnt is the ID of the block's parent.
When the VM executes a LOOP operation, it does the following:
- Pops the stack and:
a. If the popped value is adds a tuple(blk, prnt, 1, 0...)to the block stack table (the1indicates that the loop's body is expected to be executed). Then, adds a tuple(blk, loop_body_hash, 0, 1)to the block hash table.
b. If the popped value is , adds(blk, prnt, 0, 0...)to the block stack table. In this case, nothing is added to the block hash table.
c. If the popped value is neither nor , the execution fails. - Initiates a 2-to-1 hash computation in the hash chiplet (as described here) using
blkas row address in the auxiliary hashing table and as input values.
SPAN operation
Before a SPAN operation is executed by the VM, the prover populates registers with contents of the first operation batch of the span block as shown in the diagram below. The prover also sets the group count register to the total number of operation groups in the span block.
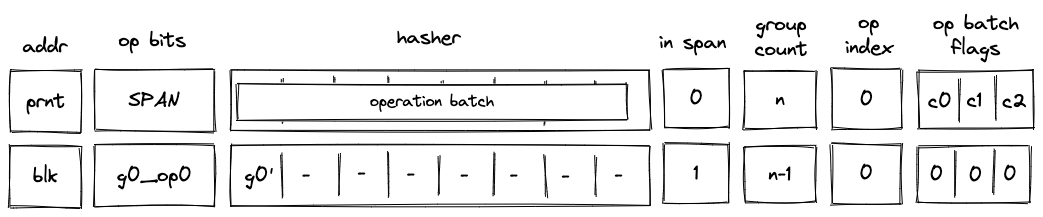
In the above diagram, blk is the ID of the span block which is about to be executed. blk is also the address of the hasher row in the auxiliary hasher table. prnt is the ID of the block's parent. g0_op0 is the first operation of the batch, and g_0' is the first operation group of the batch with the first operation removed.
When the VM executes a SPAN operation, it does the following:
- Adds a tuple
(blk, prnt, 0, 0...)to the block stack table. - Adds groups of the operation batch, as specified by op batch flags (see here) to the op group table.
- Initiates a sequential hash computation in the hash chiplet (as described here) using
blkas row address in the auxiliary hashing table and as input values. - Sets the
in_spanregister to . - Decrements
group_countregister by . - Sets the
op_indexregister to .
DYN operation

In the above diagram, blk is the ID of the dyn block which is about to be executed. blk is also the address of the hasher row in the auxiliary hasher table. p_addr is the ID of the block's parent.
When the VM executes a DYN operation, it does the following:
- Adds a tuple
(blk, p_addr, 0, 0...)to the block stack table. - Sends a memory read request to the memory chiplet, using
s0as the memory address. The resulthash of calleeis placed in the decoder hasher trace at . - Adds the tuple
(blk, hash of callee, 0, 0)to the block hash table. - Initiates a 2-to-1 hash computation in the hash chiplet (as described here) using
blkas row address in the auxiliary hashing table and[ZERO; 8]as input values. - Performs a stack left shift
- Above
s16was pulled from the stack overflow table if present; otherwise set to0.
- Above
Note that unlike DYNCALL, the fmp, ctx, in_syscall and fn_hash registers are unchanged.
DYNCALL operation

In the above diagram, blk is the ID of the dyn block which is about to be executed. blk is also the address of the hasher row in the auxiliary hasher table. p_addr is the ID of the block's parent.
When the VM executes a DYNCALL operation, it does the following:
- Adds a tuple
(blk, p_addr, 0, ctx, fmp, b_0, b_1, fn_hash[0..3])to the block stack table. - Sends a memory read request to the memory chiplet, using
s0as the memory address. The resulthash of calleeis placed in the decoder hasher trace at . - Adds the tuple
(blk, hash of callee, 0, 0)to the block hash table. - Initiates a 2-to-1 hash computation in the hash chiplet (as described here) using
blkas row address in the auxiliary hashing table and[ZERO; 8]as input values. - Performs a stack left shift
- Above
s16was pulled from the stack overflow table if present; otherwise set to0.
- Above
Similar to CALL, DYNCALL resets the fmp, sets up a new ctx, and sets the fn_hash registers to the callee hash. in_syscall needs to be 0, since calls are not allowed during a syscall.
END operation
Before an END operation is executed by the VM, the prover populates registers with the hash of the block which is about to end. The prover also sets values in and registers as follows:
- is set to if the block is a body of a loop block. We denote this value as
f0. - is set to if the block is a loop block. We denote this value as
f1. - is set to if the block is a call block. We denote this value as
f2. - is set to if the block is a syscall block. We denote this value as
f3.
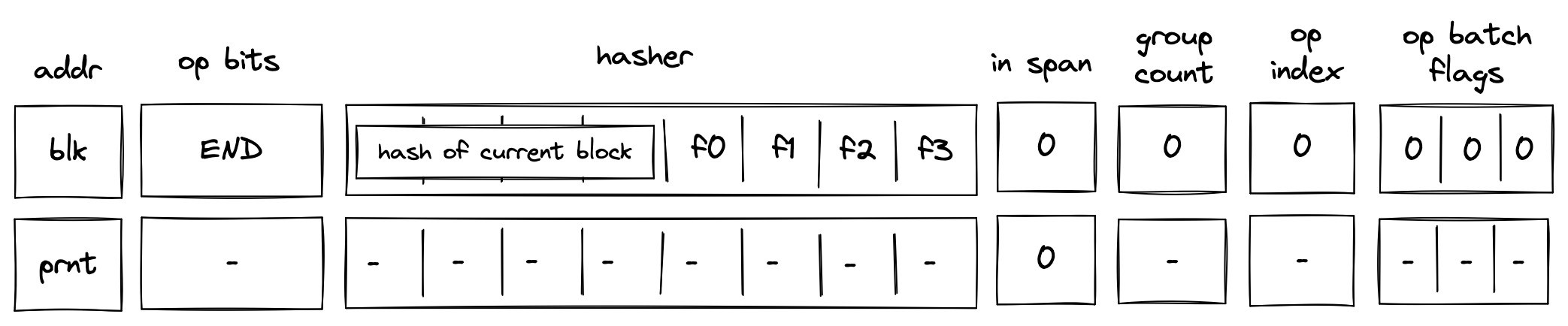
In the above diagram, blk is the ID of the block which is about to finish executing. prnt is the ID of the block's parent.
When the VM executes an END operation, it does the following:
- Removes a tuple from the block stack table.
- if
f2orf3is set, we remove a row(blk, prnt, 0, ctx_next, fmp_next, b0_next, b1_next, fn_hash_next[0..4])- in the above, the
x_nextvariables denote the columnxin the next row
- in the above, the
- else, we remove a row
(blk, prnt, f1, 0, 0, 0, 0, 0)
- if
- Removes a tuple
(prnt, current_block_hash, nxt, f0)from the block hash table, where if the next operation is eitherENDorREPEAT, and otherwise. - Reads the hash result from the hash chiplet (as described here) using
blk + 7as row address in the auxiliary hashing table. - If (i.e., we are exiting a loop block), pops the value off the top of the stack and verifies that the value is .
- Verifies that
group_countregister is set to .
HALT operation
Before a HALT operation is executed by the VM, the VM copies values in registers to the next row as illustrated in the diagram below:
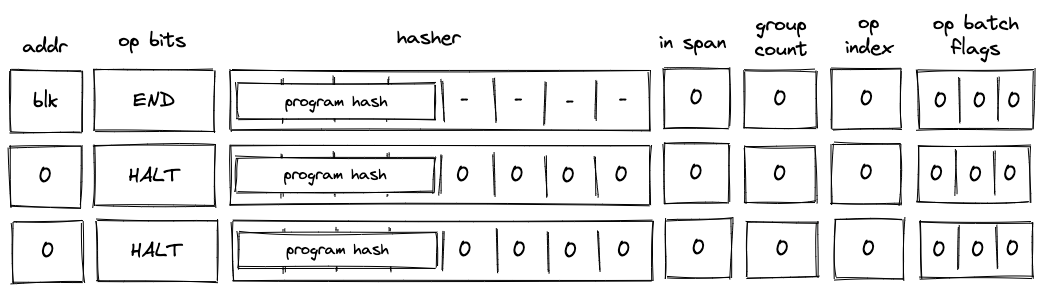
In the above diagram, blk is the ID of the block which is about to finish executing.
When the VM executes a HALT operation, it does the following:
- Verifies that block address register is set to .
- If we are not at the last row of the trace, verifies that the next operation is
HALT. - Copies values of registers to the next row.
- Populates all other decoder registers with 's in the next row.
REPEAT operation
Before a REPEAT operation is executed by the VM, the VM copies values in registers to the next row as shown in the diagram below.
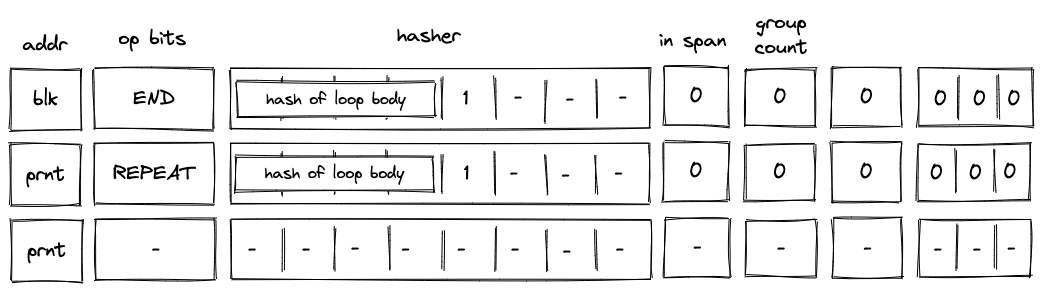
In the above diagram, blk is the ID of the loop's body and prnt is the ID of the loop.
When the VM executes a REPEAT operation, it does the following:
- Checks whether register is set to . If it isn't (i.e., we are not in a loop), the execution fails.
- Pops the stack and if the popped value is , adds a tuple
(prnt, loop_body_loop 0, 1)to the block hash table. If the popped value is not , the execution fails.
The effect of the above is that the VM needs to execute the loop's body again to clear the block hash table.
RESPAN operation
Before a RESPAN operation is executed by the VM, the VM copies the ID of the current block blk and the number of remaining operation groups in the span to the next row, and sets the value of in_span column to . The prover also sets the value of register for the next row to the ID of the current block's parent prnt as shown in the diagram below:
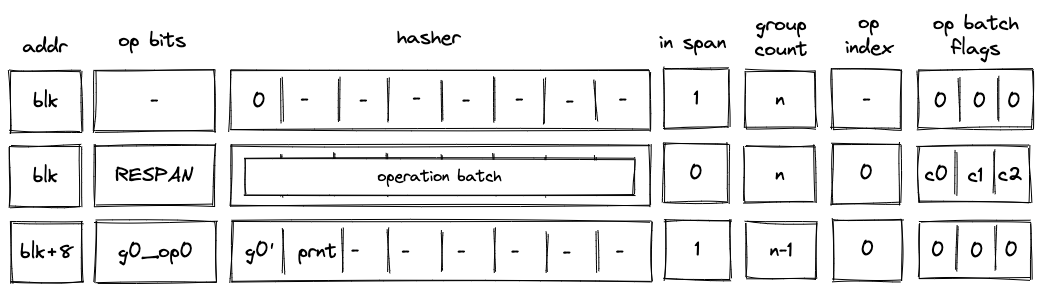
In the above diagram, g0_op0 is the first operation of the new operation batch, and g0' is the first operation group of the batch with g0_op0 operation removed.
When the VM executes a RESPAN operation, it does the following:
- Increments block address by .
- Removes the tuple
(blk, prnt, 0, 0...)from the block stack table. - Adds the tuple
(blk+8, prnt, 0, 0...)to the block stack table. - Absorbs values in registers into the hasher state of the hash chiplet (as described here).
- Sets the
in_spanregister to . - Adds groups of the operation batch, as specified by op batch flags (see here) to the op group table using
blk+8as batch ID.
The net result of the above is that we incremented the ID of the current block by and added the next set of operation groups to the op group table.
CALL operation
Recall that the purpose of a CALL operation is to execute a procedure in a new execution context. Specifically, this means that the entire memory is zero'd in the new execution context, and the stack is truncated to a depth of 16 (i.e. any element in the stack overflow table is not available in the new context). On the corresponding END instruction, the prover will restore the previous execution context (verified by the block stack table).
Before a CALL operation, the prover populates registers with the hash of the procedure being called. In the next row, the prover
- resets the FMP register (free memory pointer),
- sets the context ID to the next row's CLK value
- sets the
fn hashregisters to the hash of the callee- This register is what the
callerinstruction uses to return the hash of the caller in a syscall
- This register is what the
- resets the stack
B0register to 16 (which tracks the current stack depth) - resets the overflow address to 0 (which tracks the "address" of the last element added to the overflow table)
- it is set to 0 to indicate that the overflow table is empty

In the above diagram, blk is the ID of the call block which is about to be executed. blk is also the address of the hasher row in the auxiliary hasher table. prnt is the ID of the block's parent.
When the VM executes a CALL operation, it does the following:
- Adds a tuple
(blk, prnt, 0, p_ctx, p_fmp, p_b0, p_b1, prnt_fn_hash[0..4])to the block stack table. - Initiates a 2-to-1 hash computation in the hash chiplet (as described here) using
blkas row address in the auxiliary hashing table and as input values.
SYSCALL operation
Similarly to the CALL operation, a SYSCALL changes the execution context. However, it always jumps back to the root context, and executes kernel procedures only.
Before a SYSCALL operation, the prover populates registers with the hash of the procedure being called. In the next row, the prover
- resets the FMP register (free memory pointer),
- sets the context ID to 0,
- does NOT modify the
fn hashregister- Hence, the
fn hashregister contains the procedure hash of the caller, to be accessed by thecallerinstruction,
- Hence, the
- resets the stack
B0register to 16 (which tracks the current stack depth) - resets the overflow address to 0 (which tracks the "address" of the last element added to the overflow table)
- it is set to 0 to indicate that the overflow table is empty

In the above diagram, blk is the ID of the syscall block which is about to be executed. blk is also the address of the hasher row in the auxiliary hasher table. prnt is the ID of the block's parent.
When the VM executes a SYSCALL operation, it does the following:
- Adds a tuple
(blk, prnt, 0, p_ctx, p_fmp, p_b0, p_b1, prnt_fn_hash[0..4])to the block stack table. - Sends a request to the kernel ROM chiplet indicating that
hash of calleeis being accessed.- this results in a fault if
hash of calleedoes not correspond to the hash of a kernel procedure
- this results in a fault if
- Initiates a 2-to-1 hash computation in the hash chiplet (as described here) using
blkas row address in the auxiliary hashing table and as input values.
Program decoding
When decoding a program, we start at the root block of the program. We can compute the hash of the root block directly from hashes of its children. The prover provides hashes of the child blocks non-deterministically, and we use them to compute the program's hash (here we rely on the hash chiplet). We then verify the program hash via boundary constraints. Thus, if the prover provided valid hashes for the child blocks, we will get the expected program hash.
Now, we need to verify that the VM executed the child blocks correctly. We do this recursively similar to what is described above: for each of the blocks, the prover provides hashes of its children non-deterministically and we verify that the hash has been computed correctly. We do this until we get to the leaf nodes (i.e., span blocks). Hashes of span blocks are computed sequentially from the instructions executed by the VM.
The sections below illustrate how different types of code blocks are decoded by the VM.
JOIN block decoding
When decoding a join bock, the VM first executes a JOIN operation, then executes the first child block, followed by the second child block. Once the children of the join block are executed, the VM executes an END operation. This is illustrated in the diagram below.
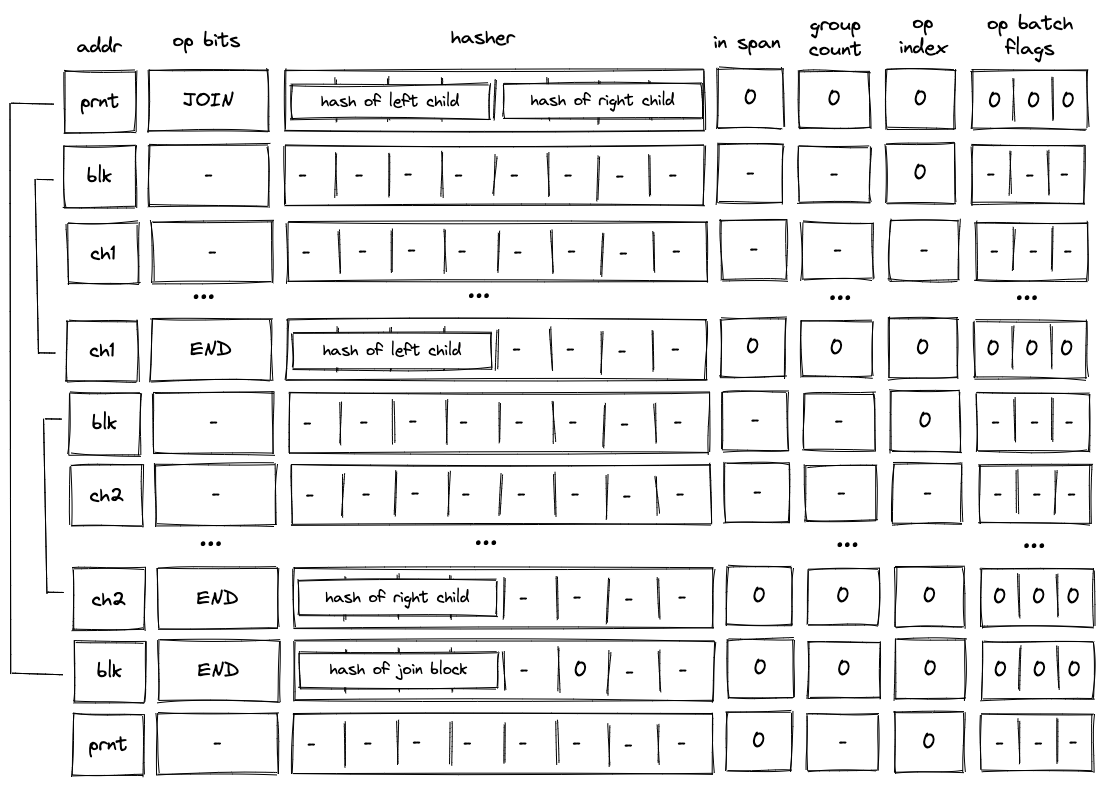
As described previously, when the VM executes a JOIN operation, hashes of both children are added to the block hash table. These hashes are removed only when the END operations for the child blocks are executed. Thus, until both child blocks are executed, the block hash table is not cleared.
SPLIT block decoding
When decoding a split block, the decoder pops an element off the top of the stack, and if the popped element is , executes the block corresponding to the true branch. If the popped element is , the decoder executes the block corresponding to the false branch. This is illustrated on the diagram below.
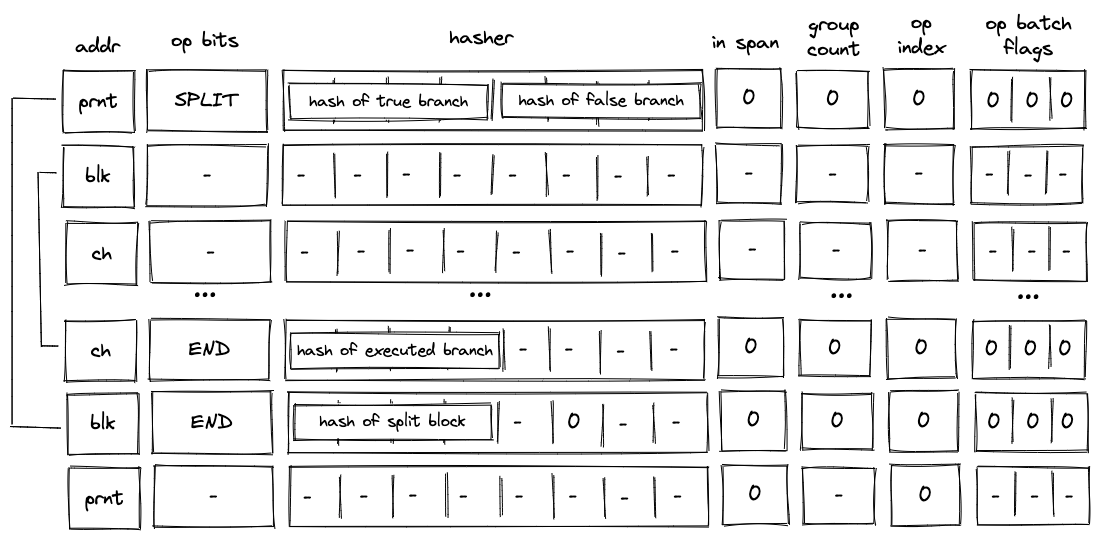
As described previously, when the VM executes a SPLIT operation, only the hash of the branch to be executed is added to the block hash table. Thus, until the child block corresponding to the required branch is executed, the block hash table is not cleared.
LOOP block decoding
When decoding a loop bock, we need to consider two possible scenarios:
- When the top of the stack is , we need to enter the loop and execute loop body at least once.
- When the top of the stack is, we need to skip the loop.
In both cases, we need to pop an element off the top of the stack.
Executing the loop
If the top of the stack is , the VM executes a LOOP operation. This removes the top element from the stack and adds the hash of the loop's body to the block hash table. It also adds a row to the block stack table setting the is_loop value to .
To clear the block hash table, the VM needs to execute the loop body (executing the END operation for the loop body block will remove the corresponding row from the block hash table). After loop body is executed, if the top of the stack is , the VM executes a REPEAT operation (executing REPEAT operation when the top of the stack is will result in an error). This operation again adds the hash of the loop's body to the block hash table. Thus, the VM needs to execute the loop body again to clear the block hash table.
This process is illustrated on the diagram below.
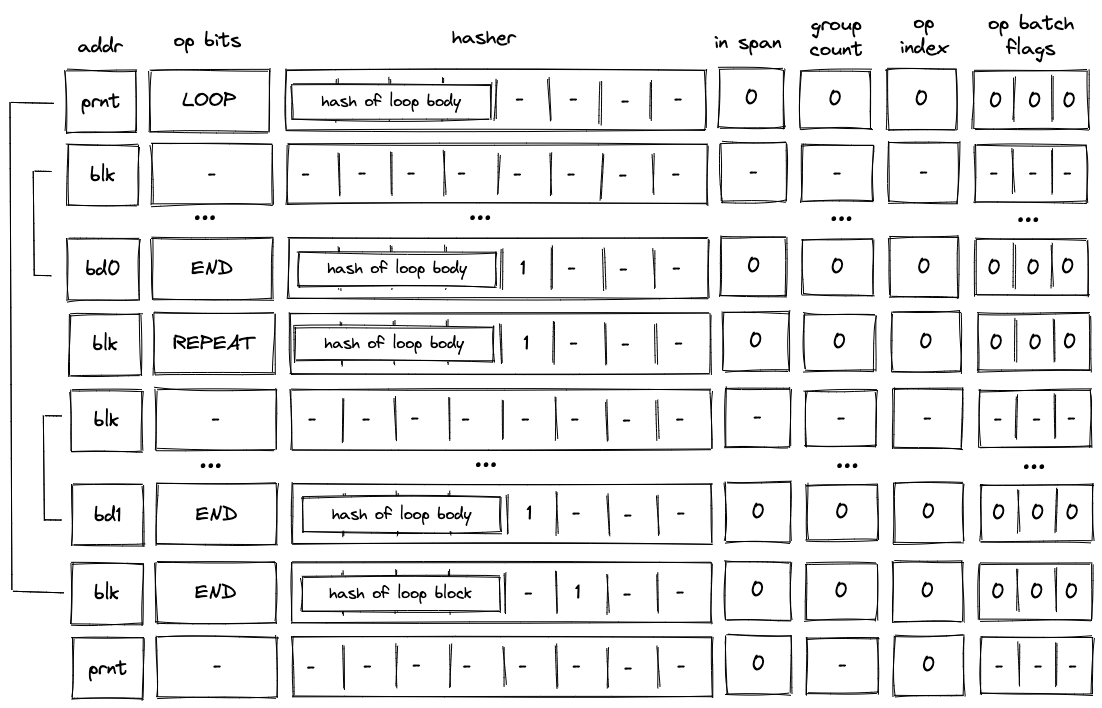
The above steps are repeated until the top of the stack becomes , at which point the VM executes the END operation. Since in the beginning we set is_loop column in the block stack table to , column will be set to when the END operation is executed. Thus, executing the END operation will also remove the top value from the stack. If the removed value is not , the operation will fail. Thus, the VM can exit the loop block only when the top of the stack is .
Skipping the loop
If the top of the stack is , the VM still executes the LOOP operation. But unlike in the case when we need to enter the loop, the VM sets is_loop flag to in the block stack table, and does not add any rows to the block hash table. The last point means that the only possible operation to be executed after the LOOP operation is the END operation. This is illustrated in the diagram below.
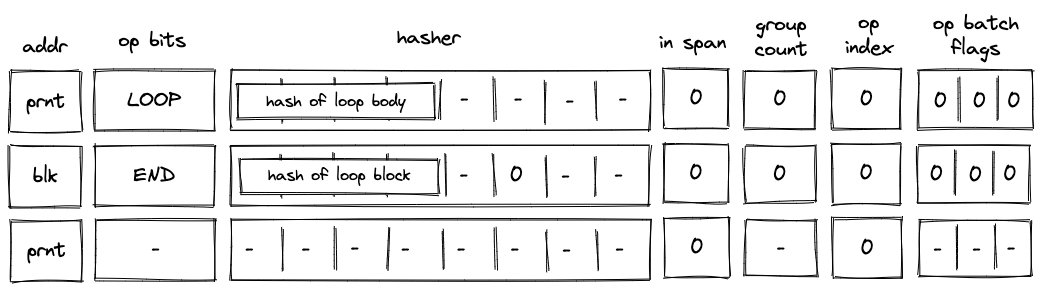
Moreover, since we've set the is_loop flag to , executing the END operation does not remove any items from the stack.
DYN block decoding
When decoding a dyn bock, the VM first executes a DYN operation, then executes the child block dynamically specified by the top of the stack. Once the child of the dyn block has been executed, the VM executes an END operation. This is illustrated in the diagram below.
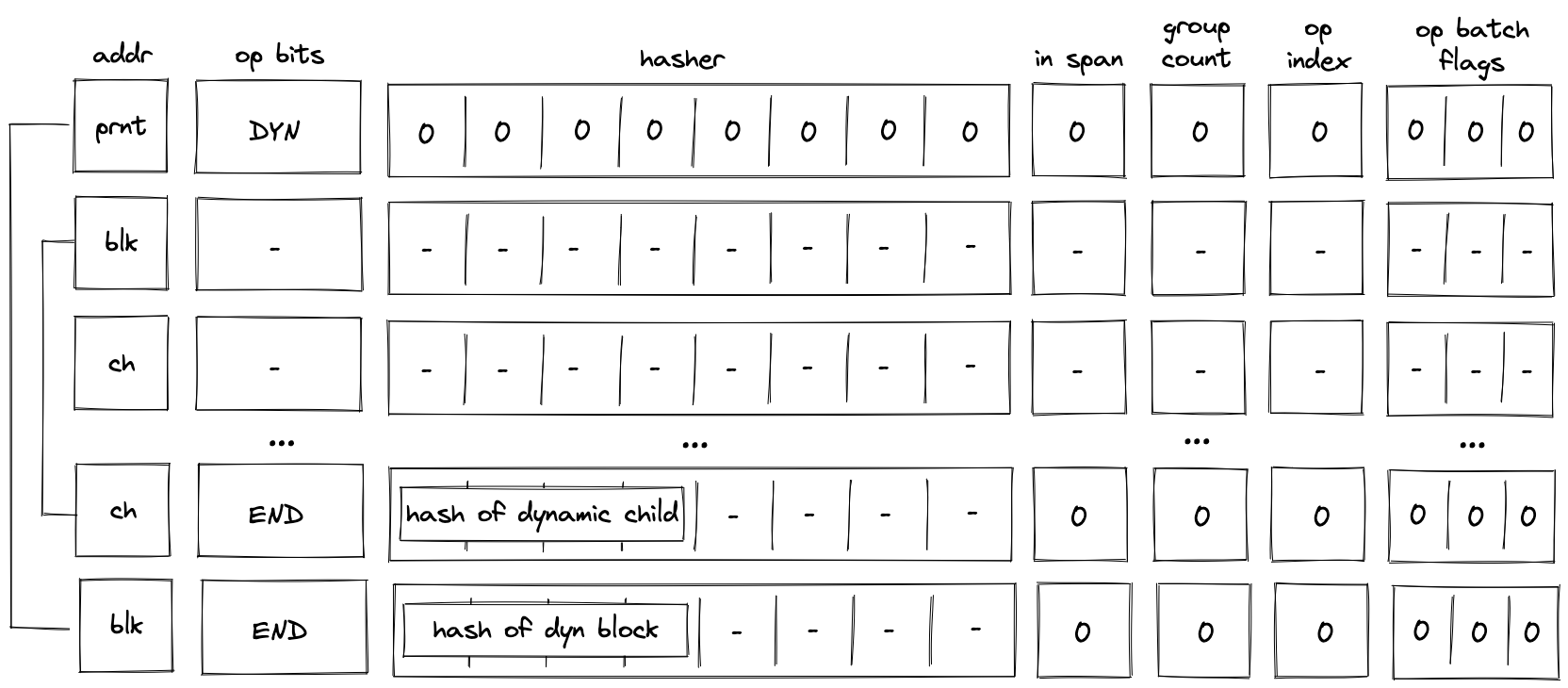
As described previously, when the VM executes a DYN operation, the hash of the child is added to the block hash table. This hash is removed only when the END operation for the child block is executed. Thus, until the child block corresponding to the dynamically specified target is executed, the block hash table is not cleared.
SPAN block decoding
As described here, a span block can contain one or more operation batches, each batch containing up to operation groups. At the high level, decoding of a span block is done as follows:
- At the beginning of the block, we make a request to the hash chiplet which initiates the hasher, absorbs the first operation batch ( field elements) into the hasher, and returns the row address of the hasher, which we use as the unique ID for the span block (see here).
- We then add groups of the operation batch, as specified by op batch flags (but always skipping the first one) to the op group table.
- We then remove operation groups from the op group table in the FIFO order one by one, and decode them in the manner similar to the one described here.
- Once all operation groups in a batch have been decoded, we absorb the next batch into the hasher and repeat the process described above.
- Once all batches have been decoded, we return the hash of the span block from the hasher.
Overall, three control flow operations are used when decoding a span block:
SPANoperation is used to initialize a hasher and absorbs the first operation batch into it.RESPANoperation is used to absorb any additional batches in the span block.ENDoperation is used to end the decoding of a span block and retrieve its hash from the hash chiplet.
Operation group decoding
As described here, an operation group is a sequence of operations which can be encoded into a single field element. For a field element of bits, we can fit up to operations into a group. We do this by concatenating binary representations of opcodes together with the first operation located in the least significant position.
We can read opcodes from the group by simply subtracting them from the op group value and then dividing the result by . Once the value of the op group reaches , we know that all opcodes have been read. Graphically, this can be illustrated like so:
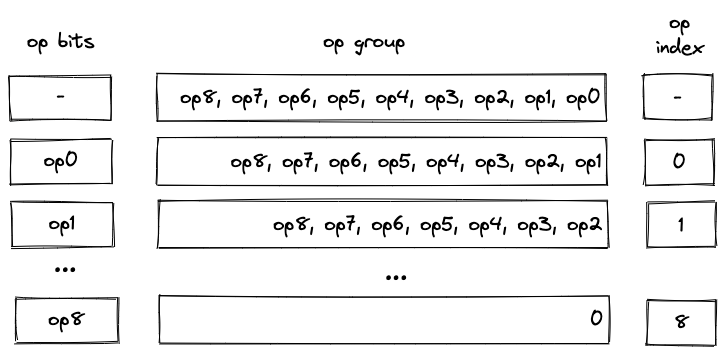
Notice that despite their appearance, op bits is actually separate registers, while op group is just a single register.
We also need to make sure that at most operations are executed as a part of a single group. For this purpose we use the op_index column. Values in this column start out at for each operation group, and are incremented by for each executed operation. To make sure that at most operations can be executed in a group, the value of the op_index column is not allowed to exceed .
Operation batch flags
Operation batch flags are used to specify how many operation groups comprise a given operation batch. For most batches, the number of groups will be equal to . However, for the last batch in a block (or for the first batch, if the block consists of only a single batch), the number of groups may be less than . Since processing of new batches starts only on SPAN and RESPAN operations, only for these operations the flags can be set to non-zero values.
To simplify the constraint system, the number of groups in a batch can be only one of the following values: , , , and . If the number of groups in a batch does not match one of these values, the batch is simply padded with NOOP's (one NOOP per added group). Consider the diagram below.

In the above, the batch contains operation groups. To bring the count up to , we consider the -th group (i.e., ) to be a part of the batch. Since a numeric value for NOOP operation is , op group value of can be interpreted as a single NOOP.
Operation batch flags (denoted as ), encode the number of groups and define how many groups are added to the op group table as follows:
(1, -, -)- groups. Groups in are added to the op group table.(0, 1, 0)- groups. Groups in are added to the op group table(0, 0, 1)- groups. Groups in is added to the op group table.(0, 1, 1)- group. Nothing is added to the op group table(0, 0, 0)- not aSPANorRESPANoperation.
Single-batch span
The simplest example of a span block is a block with a single batch. This batch may contain up to operation groups (e.g., ). Decoding of such a block is illustrated in the diagram below.
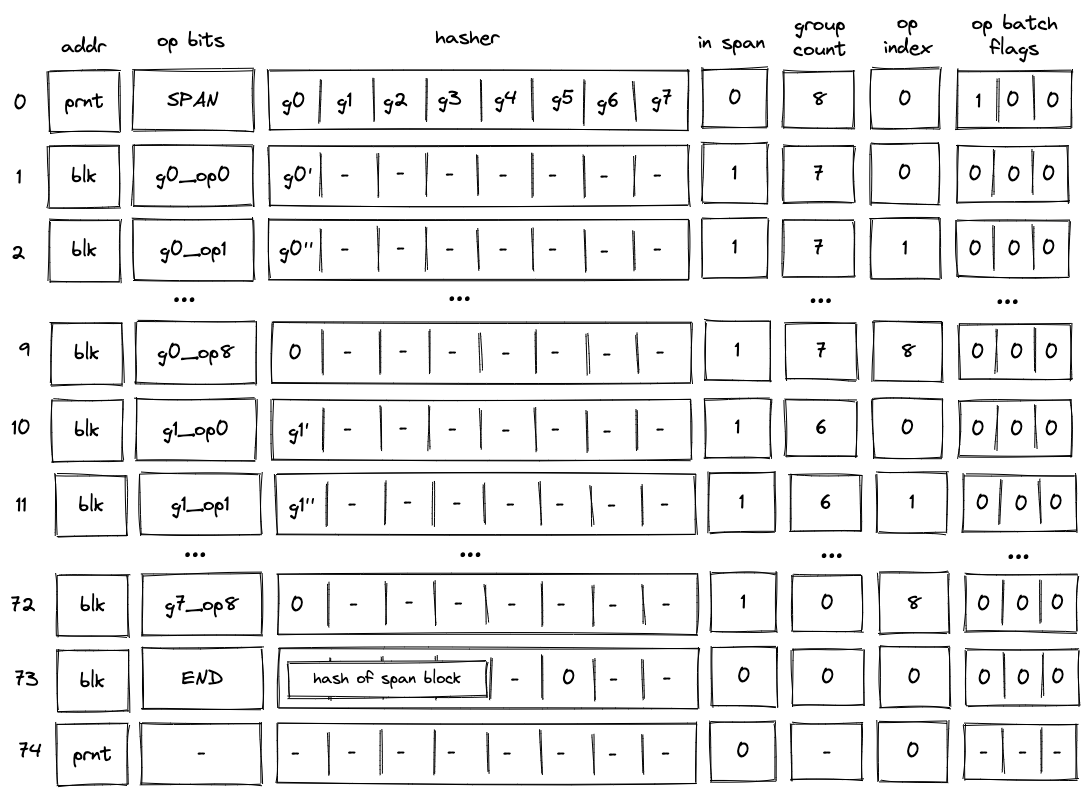
Before the VM starts processing this span block, the prover populates registers with operation groups . The prover also puts the total number of groups into the group_count register . In this case, the total number of groups is .
When the VM executes a SPAN operation, it does the following:
- Initiates hashing of elements using hash chiplet. The hasher address is used as the block ID
blk, and it is inserted intoaddrregister in the next row. - Adds a tuple
(blk, prnt, 0)to the block stack table. - Sets the
is_spanregister to in the next row. - Sets the
op_indexregister to in the next row. - Decrements
group_countregister by . - Sets
op bitsregisters at the next step to the first operation of , and also copies with the first operation removed (denoted as ) to the next row. - Adds groups to the op group table. Thus, after the
SPANoperation is executed, op group table looks as shown below.

Then, with every step the next operation is removed from , and by step , the value of is . Once this happens, the VM does the following:
- Decrements
group_countregister by . - Sets
op bitsregisters at the next step to the first operation of . - Sets
hasherregister to the value of with the first operation removed (denoted as ). - Removes row
(blk, 7, g1)from the op group table. This row can be obtained by taking values from registers:addr,group_count, and for , where and refer to values in the next row for the first hasher column andop_bitscolumns respectively.
Note that we rely on the group_count column to construct the row to be removed from the op group table. Since group count is decremented from the total number of groups to , to remove groups from the op group table in correct order, we need to assign group position to groups in the op group table in the reverse order. For example, the first group to be removed should have position , the second group to be removed should have position etc.
Decoding of is performed in the same manner as decoding of : with every subsequent step the next operation is removed from until its value reaches , at which point, decoding of group begins.
The above steps are executed until value of group_count reaches . Once group_count reaches and the last operation group is executed, the VM executes the END operation. Semantics of the END operation are described here.
Notice that by the time we get to the END operation, all rows are removed from the op group table.
Multi-batch span
A span block may contain an unlimited number of operation batches. As mentioned previously, to absorb a new batch into the hasher, the VM executes a RESPAN operation. The diagram below illustrates decoding of a span block consisting of two operation batches.
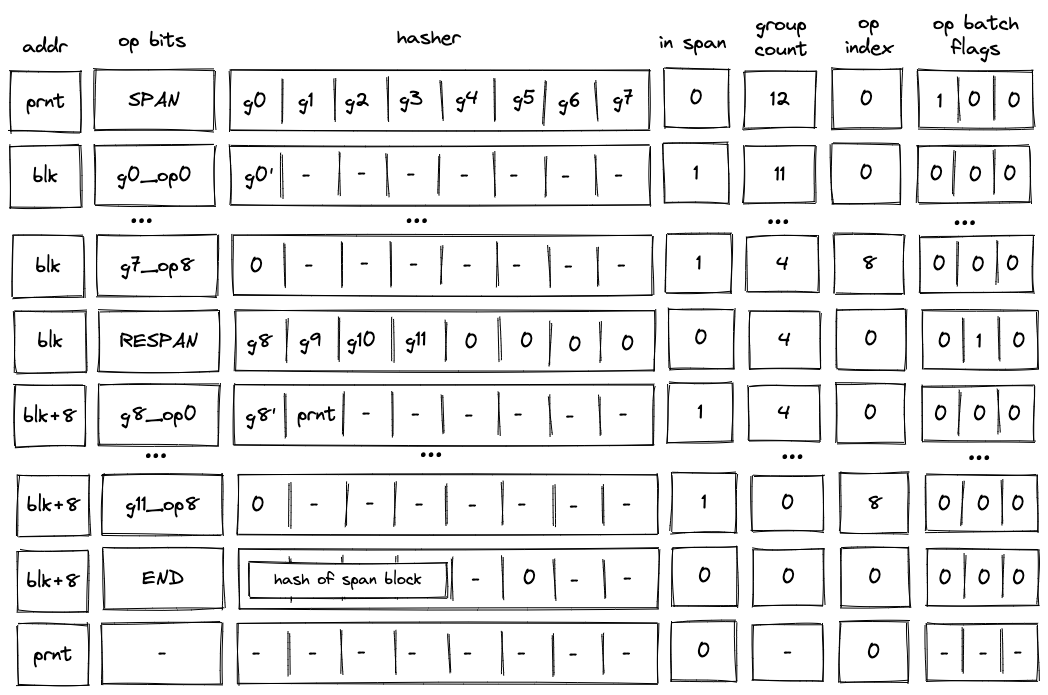
Decoding of such a block will look very similar to decoding of the single-span block described previously, but there also will be some differences.
First, after the SPAN operation is executed, the op group table will look as follows:
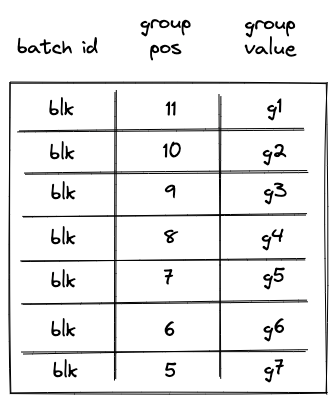
Notice that while the same groups () are added to the table, their positions now reflect the total number of groups in the span block.
Second, executing a RESPAN operation increments hasher address by . This is done because absorbing additional elements into the hasher state requires more rows in the auxiliary hasher table.
Incrementing value of addr register actually changes the ID of the span block (though, for a span block, it may be more appropriate to view values in this column as IDs of individual operation batches). This means that we also need to update the block stack table. Specifically, we need to remove row (blk, prnt, 0) from it, and replace it with row (blk + 8, prnt, 0). To perform this operation, the prover sets the value of in the next row to prnt.
Executing a RESPAN operation also adds groups to the op group table, which now would look as follows:

Then, the execution of the second batch proceeds in a manner similar to the first batch: we remove operations from the current op group, execute them, and when the value of the op group reaches , we start executing the next group in the batch. Thus, by the time we get to the END operation, the op group table should be empty.
When executing the END operation, the hash of the span block will be read from hasher row at address addr + 7, which, in our example, will be equal to blk + 15.
Handling immediate values
Miden VM operations can carry immediate values. Currently, the only such operation is a PUSH operation. Since immediate values can be thought of as constants embedded into program code, we need to make sure that changing immediate values affects program hash.
To achieve this, we treat immediate values in a manner similar to how we treat operation groups. Specifically, when computing hash of a span block, immediate values are absorbed into the hasher state in the same way as operation groups are. As mentioned previously, an immediate value is represented by a single field element, and thus, an immediate value takes place of a single operation group.
The diagram below illustrates decoding of a span block with operations one of which is a PUSH operation.
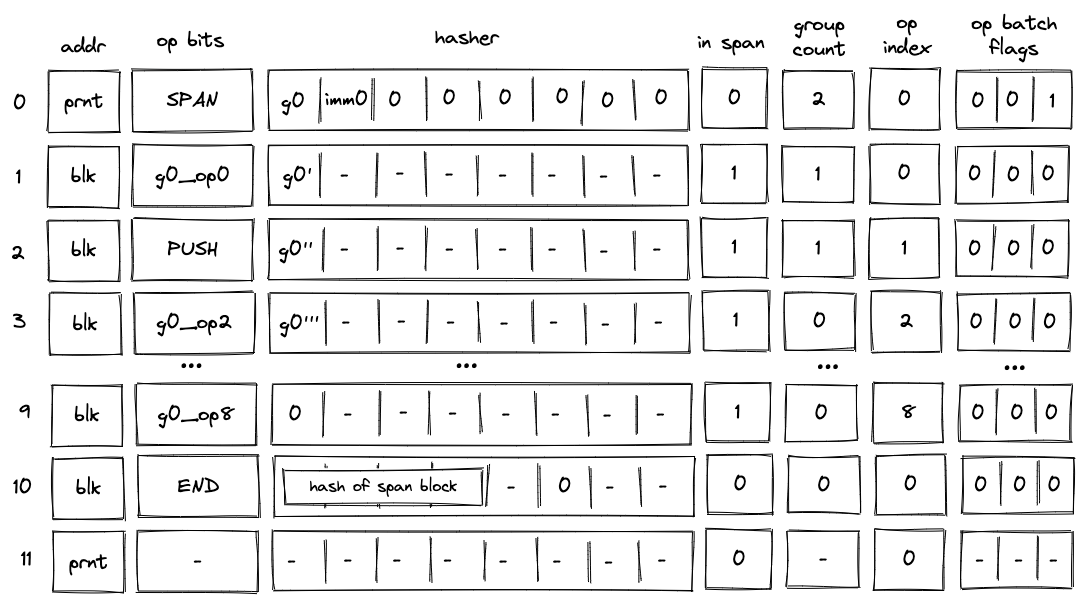
In the above, when the SPAN operation is executed, immediate value imm0 will be added to the op group table, which will look as follows:
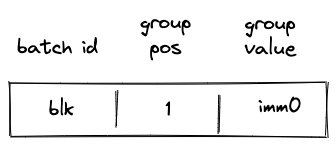
Then, when the PUSH operation is executed, the VM will do the following:
- Decrement
group_countby . - Remove a row from the op group table equal to
(addr, group_count, s0'), where is the value of the top of the stack at the next row (i.e., it is the value that is pushed onto the stack).
Thus, after the PUSH operation is executed, the op group table is cleared, and group count decreases to (which means that there are no more op groups to execute). Decoding of the rest of the op group proceeds as described in the previous sections.
Program decoding example
Let's run through an example of decoding a simple program shown previously:
begin
<operations1>
if.true
<operations2>
else
<operations3>
end
end
Translating this into code blocks with IDs assigned, we get the following:
b0: JOIN
b1: SPAN
<operations1>
b1: END
b2: SPLIT
b3: SPAN
<operations2>
b3: END
b4: SPAN
<operations3>
b4: END
b2: END
b0: END
The root of the program is a join block . This block contains two children: a span bock and a split block . In turn, the split block contains two children: a span block and a span block .
When this program is executed on the VM, the following happens:
- Before the program starts executing, block hash table is initialized with a single row containing the hash of .
- Then,
JOINoperation for is executed. It adds hashes of and to the block hash table. It also adds an entry for to the block stack table. States of both tables after this step are illustrated below. - Then, span is executed and a sequential hash of its operations is computed. Also, when
SPANoperation for is executed, an entry for is added to the block stack table. At the end of (whenENDis executed), entries for are removed from both the block hash and block stack tables. - Then,
SPLIToperation for is executed. It adds an entry for to the block stack table. Also, depending on whether the top of the stack is or , either hash of or hash of is added to the block hash table. Let's say the top of the stack is . Then, at this point, the block hash and block stack tables will look like in the second picture below. - Then, span is executed and a sequential hash of its instructions is computed. Also, when
SPANoperation for is executed, an entry for is added to the block stack table. At the end of (whenENDis executed), entries for are removed from both the block hash and block stack tables. - Then,
ENDoperation for is executed. It removes the hash of from the block hash table, and also removes the entry for from the block stack table. The third picture below illustrates the states of block stack and block hash tables after this step. - Then,
ENDfor is executed, which removes entries for from the block stack and block hash tables. At this point both tables are empty. - Finally, a sequence of
HALToperations is executed until the length of the trace reaches a power of two.
States of block hash and block stack tables after step 2:
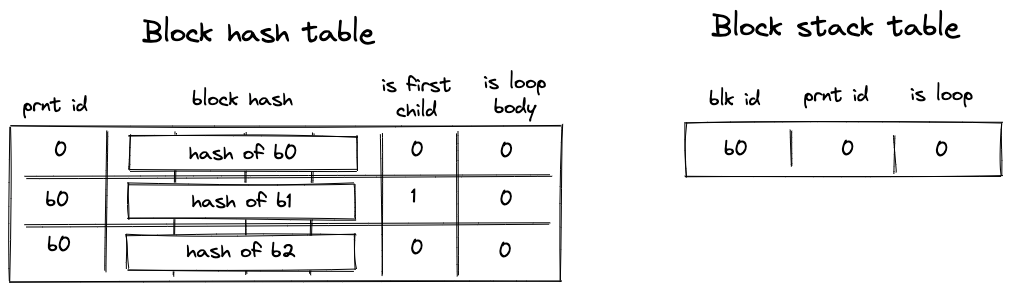
States of block hash and block stack tables after step 4:
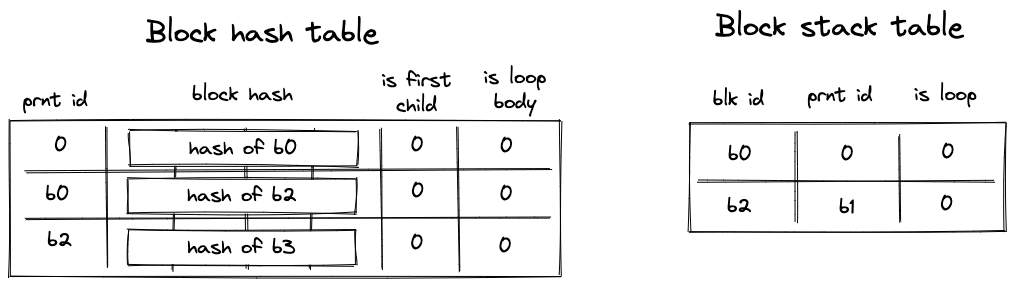
States of block hash and block stack tables after step 6:

Miden VM decoder AIR constraints
In this section we describe AIR constraints for Miden VM program decoder. These constraints enforce that the execution trace generated by the prover when executing a particular program complies with the rules described in the previous section.
To refer to decoder execution trace columns, we use the names shown on the diagram below (these are the same names as in the previous section). Additionally, we denote the register containing the value at the top of the stack as .

We assume that the VM exposes a flag per operation which is set to when the operation is executed, and to otherwise. The notation for such flags is . For example, when the VM executes a PUSH operation, flag . All flags are mutually exclusive - i.e., when one flag is set to all other flags are set to . The flags are computed based on values in op_bits columns.
AIR constraints for the decoder involve operations listed in the table below. For each operation we also provide the degree of the corresponding flag and the effect that the operation has on the operand stack (however, in this section we do not cover the constraints needed to enforce the correct transition of the operand stack).
| Operation | Flag | Degree | Effect on stack |
|---|---|---|---|
JOIN | 5 | Stack remains unchanged. | |
SPLIT | 5 | Top stack element is dropped. | |
LOOP | 5 | Top stack element is dropped. | |
REPEAT | 4 | Top stack element is dropped. | |
SPAN | 5 | Stack remains unchanged. | |
RESPAN | 4 | Stack remains unchanged. | |
DYN | 5 | Stack remains unchanged. | |
CALL | 4 | Stack remains unchanged. | |
SYSCALL | 4 | Stack remains unchanged. | |
END | 4 | When exiting a loop block, top stack element is dropped; otherwise, the stack remains unchanged. | |
HALT | 4 | Stack remains unchanged. | |
PUSH | 5 | An immediate value is pushed onto the stack. | |
EMIT | 5 | Stack remains unchanged. |
We also use the control flow flag exposed by the VM, which is set when any one of the above control flow operations is being executed. It has degree .
As described previously, the general idea of the decoder is that the prover provides the program to the VM by populating some of cells in the trace non-deterministically. Values in these are then used to update virtual tables (represented via multiset checks) such as block hash table, block stack table etc. Transition constraints are used to ensure that the tables are updates correctly, and we also apply boundary constraints to enforce the correct initial and final states of these tables. One of these boundary constraints binds the execution trace to the hash of the program being executed. Thus, if the virtual tables were updated correctly and boundary constraints hold, we can be convinced that the prover executed the claimed program on the VM.
In the sections below, we describe constraints according to their logical grouping. However, we start out with a set of general constraints which are applicable to multiple parts of the decoder.
General constraints
When SPLIT or LOOP operation is executed, the top of the operand stack must contain a binary value:
When a DYN operation is executed, the hasher registers must all be set to :
When REPEAT operation is executed, the value at the top of the operand stack must be :
Also, when REPEAT operation is executed, the value in column (the is_loop_body flag), must be set to . This ensures that REPEAT operation can be executed only inside a loop:
When RESPAN operation is executed, we need to make sure that the block ID is incremented by :
When END operation is executed and we are exiting a loop block (i.e., is_loop, value which is stored in , is ), the value at the top of the operand stack must be :
Also, when END operation is executed and the next operation is REPEAT, values in (the hash of the current block and the is_loop_body flag) must be copied to the next row:
A HALT instruction can be followed only by another HALT instruction:
When a HALT operation is executed, block address column must be :
Values in op_bits columns must be binary (i.e., either or ):
When the value in in_span column is set to , control flow operations cannot be executed on the VM, but when in_span flag is , only control flow operations can be executed on the VM:
Block hash computation constraints
As described previously, when the VM starts executing a new block, it also initiates computation of the block's hash. There are two separate methodologies for computing block hashes.
For join, split, and loop blocks, the hash is computed directly from the hashes of the block's children. The prover provides these child hashes non-deterministically by populating registers . For dyn, the hasher registers are populated with zeros, so the resulting hash is a constant value. The hasher is initialized using the hash chiplet, and we use the address of the hasher as the block's ID. The result of the hash is available rows down in the hasher table (i.e., at row with index equal to block ID plus ). We read the result from the hasher table at the time the END operation is executed for a given block.
For span blocks, the hash is computed by absorbing a linear sequence of instructions (organized into operation groups and batches) into the hasher and then returning the result. The prover provides operation batches non-deterministically by populating registers . Similarly to other blocks, the hasher is initialized using the hash chiplet at the start of the block, and we use the address of the hasher as the ID of the first operation batch in the block. As we absorb additional operation batches into the hasher (by executing RESPAN operation), the batch address is incremented by . This moves the "pointer" into the hasher table rows down with every new batch. We read the result from the hasher table at the time the END operation is executed for a given block.
Chiplets bus constraints
The decoder communicates with the hash chiplet via the chiplets bus. This works by dividing values of the multiset check column by the values of operations providing inputs to or reading outputs from the hash chiplet. A constraint to enforce this would look as , where is the value which defines the operation.
In constructing value of for decoder AIR constraints, we will use the following labels (see here for an explanation of how values for these labels are computed):
- this label specifies that we are starting a new hash computation.
- this label specifies that we are absorbing the next sequence of elements into an ongoing hash computation.
- this label specifies that we are reading the result of a hash computation.
To simplify constraint description, we define the following variables:
In the above, can be thought of as initiating a hasher with address and absorbing elements from the hasher state () into it. Control blocks are always padded to fill the hasher rate and as such the (first capacity register) term is set to .
It should be noted that refers to a column in the decoder, as depicted. The addresses in this column are set using the address from the hasher chiplet for the corresponding hash initialization / absorption / return. In the case of the value of the address in column in the current row of the decoder is set to equal the value of the address of the row in the hasher chiplet where the previous absorption (or initialization) occurred. is the address of the next row of the decoder, which is set to equal the address in the hasher chiplet where the absorption referred to by the label is happening.
In the above, represents the address value in the decoder which corresponds to the hasher chiplet address at which the hasher was initialized (or the last absorption took place). As such, corresponds to the hasher chiplet address at which the result is returned.
In the above, is set to when a control flow operation that signifies the initialization of a control block is being executed on the VM (only those control blocks that don't do any concurrent requests to the chiplets but). Otherwise, it is set to . An exception is made for the DYN, DYNCALL, and SYSCALL operations, since although they initialize a control block, they also run another concurrent bus request, and so are handled separately.
In the above, represents the opcode value of the opcode being executed on the virtual machine. It is calculated via a bitwise combination of the op bits. We leverage the opcode value to achieve domain separation when hashing control blocks. This is done by populating the second capacity register of the hasher with the value via the term when initializing the hasher.
Using the above variables, we define operation values as described below.
When a control block initializer operation (JOIN, SPLIT, LOOP, CALL) is executed, a new hasher is initialized and the contents of are absorbed into the hasher. As mentioned above, the opcode value is populated in the second capacity register via the term.
As mentioned previously, the value sent by the SYSCALL operation is defined separately, since in addition to communicating with the hash chiplet it must also send a kernel procedure access request to the kernel ROM chiplet. This value of this kernel procedure request is described by .
In the above, is the unique operation label of the kernel procedure call operation. The values contain the root hash of the procedure being called, which is the procedure that must be requested from the kernel ROM chiplet.
The above value sends both the hash initialization request and the kernel procedure access request to the chiplets bus when the SYSCALL operation is executed.
Similar to SYSCALL, DYN and DYNCALL are handled separately, since in addition to communicating with the hash chiplet they must also issue a memory read operation for the hash of the procedure being called.
In the above, can be thought of as , but where the values used for the hasher decoder trace registers is all 0's. represents a memory read request from memory address (the top stack element), where the result is placed in the first half of the decoder hasher trace, and where is a label that represents a memory read request.
When SPAN operation is executed, a new hasher is initialized and contents of are absorbed into the hasher. The number of operation groups to be hashed is padded to a multiple of the rate width () and so the is set to 0:
When RESPAN operation is executed, contents of (which contain the new operation batch) are absorbed into the hasher:
When END operation is executed, the hash result is copied into registers :
Using the above definitions, we can describe the constraint for computing block hashes as follows:
We need to add and subtract the sum of the relevant operation flags to ensure that when none of the flags is set to , the above constraint reduces to .
The degree of this constraint is .
Block stack table constraints
As described previously, block stack table keeps track of program blocks currently executing on the VM. Thus, whenever the VM starts executing a new block, an entry for this block is added to the block stack table. And when execution of a block completes, it is removed from the block stack table.
Adding and removing entries to/from the block stack table is accomplished as follows:
- To add an entry, we multiply the value in column by a value representing a tuple
(blk, prnt, is_loop, ctx_next, fmp_next, b0_next, b1_next, fn_hash_next). A constraint to enforce this would look as , where is the value representing the row to be added. - To remove an entry, we divide the value in column by a value representing a tuple
(blk, prnt, is_loop, ctx_next, fmp_next, b0_next, b1_next, fn_hash_next). A constraint to enforce this would look as , where is the value representing the row to be removed.
Recall that the columns
ctx_next, fmp_next, b0_next, b1_next, fn_hash_nextare only set onCALL,SYSCALL, and their correspondingENDblock. Therefore, for simplicity, we will ignore them when documenting all other block types (such that their values are set to0).
Before describing the constraints for the block stack table, we first describe how we compute the values to be added and removed from the table for each operation. In the below, for block start operations (JOIN, SPLIT, LOOP, SPAN) refers to the ID of the parent block, and refers to the ID of the starting block. For END operation, the situation is reversed: is the ID of the ending block, and is the ID of the parent block. For RESPAN operation, refers to the ID of the current operation batch, refers to the ID of the next batch, and the parent ID for both batches is set by the prover non-deterministically in register .
When JOIN operation is executed, row is added to the block stack table:
When SPLIT operation is executed, row is added to the block stack table:
When LOOP operation is executed, row is added to the block stack table if the value at the top of the operand stack is , and row is added to the block stack table if the value at the top of the operand stack is :
When SPAN operation is executed, row is added to the block stack table:
When RESPAN operation is executed, row is removed from the block stack table, and row is added to the table. The prover sets the value of register at the next row to the ID of the parent block:
When a DYN operation is executed, row is added to the block stack table:
When a DYNCALL operation is executed, row is added to the block stack table:
When a CALL or SYSCALL operation is executed, row is added to the block stack table:
When END operation is executed, how we construct the row will depend on whether the IS_CALL or IS_SYSCALL values are set (stored in registers and respectively). If they are not set, then row is removed from the block span table (where contains the is_loop flag); otherwise, row .
Using the above definitions, we can describe the constraint for updating the block stack table as follows:
We need to add and subtract the sum of the relevant operation flags from each side to ensure that when none of the flags is set to , the above constraint reduces to .
The degree of this constraint is .
In addition to the above transition constraint, we also need to impose boundary constraints against the column to make sure the first and the last values in the column are set to . This enforces that the block stack table starts and ends in an empty state.
Block hash table constraints
As described previously, when the VM starts executing a new program block, it adds hashes of the block's children to the block hash table. And when the VM finishes executing a block, it removes the block's hash from the block hash table. This means that the block hash table gets updated when we execute the JOIN, SPLIT, LOOP, REPEAT, DYN, and END operations (executing SPAN operation does not affect the block hash table because a span block has no children).
Adding and removing entries to/from the block hash table is accomplished as follows:
- To add an entry, we multiply the value in column by a value representing a tuple
(prnt_id, block_hash, is_first_child, is_loop_body). A constraint to enforce this would look as , where is the value representing the row to be added. - To remove an entry, we divide the value in column by a value representing a tuple
(prnt_id, block_hash, is_first_child, is_loop_body). A constraint to enforce this would look as , where is the value representing the row to be removed.
To simplify constraint descriptions, we define values representing left and right children of a block as follows:
Graphically, this looks like so:
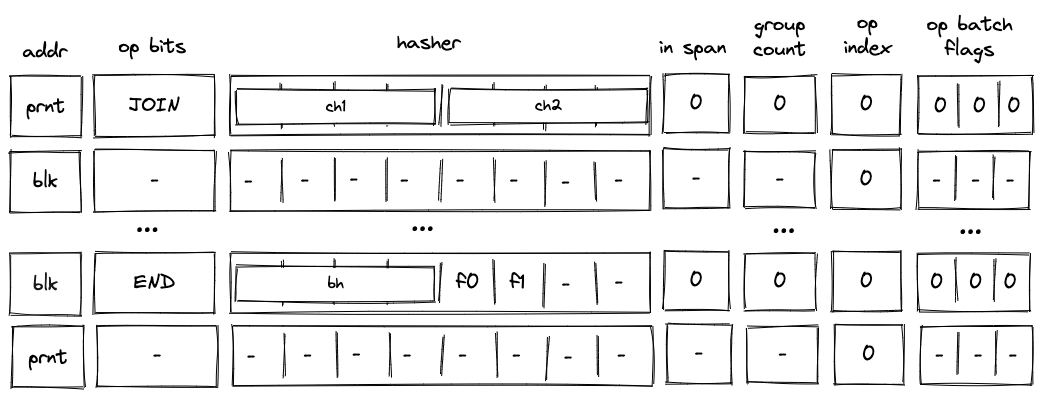
In a similar manner, we define a value representing the result of hash computation as follows:
1
Above, refers to the value in the IS_LOOP_BODY column (already constrained to be 0 or 1), located in . Also, note that we are not adding a flag indicating whether the block is the first child of a join block (i.e., term is missing). It will be added later on.
Using the above variables, we define row values to be added to and removed from the block hash table as follows.
When JOIN operation is executed, hashes of both child nodes are added to the block hash table. We add term to the first child value to differentiate it from the second child (i.e., this sets is_first_child to ):
When SPLIT operation is executed and the top of the stack is , hash of the true branch is added to the block hash table, but when the top of the stack is , hash of the false branch is added to the block hash table:
When LOOP operation is executed and the top of the stack is , hash of loop body is added to the block hash table. We add term to indicate that the child is a body of a loop. The below also means that if the top of the stack is , nothing is added to the block hash table as the expression evaluates to :
When REPEAT operation is executed, hash of loop body is added to the block hash table. We add term to indicate that the child is a body of a loop:
When DYN, DYNCALL, CALL or SYSCALL operation is executed, the hash of the child is added to the block hash table. In all cases, this child is found in the first half of the decoder hasher state.
When END operation is executed, hash of the completed block is removed from the block hash table. However, we also need to differentiate between removing the first and the second child of a join block. We do this by looking at the next operation. Specifically, if the next operation is neither END nor REPEAT nor HALT, we know that another block is about to be executed, and thus, we have just finished executing the first child of a join block. Thus, if the next operation is neither END nor REPEAT nor HALT we need to set the term for coefficient to as shown below:
Using the above definitions, we can describe the constraint for updating the block hash table as follows:
We need to add and subtract the sum of the relevant operation flags from each side to ensure that when none of the flags is set to , the above constraint reduces to .
The degree of this constraint is .
In addition to the above transition constraint, we also need to set the following boundary constraints against the column:
- The first value in the column represents a row for the entire program. Specifically, the row tuple would be
(0, program_hash, 0, 0). This row should be removed from the table when the lastENDoperation is executed. - The last value in the column is - i.e., the block hash table is empty.
Span block
Span block constraints ensure proper decoding of span blocks. In addition to the block stack table constraints and block hash table constraints described previously, decoding of span blocks requires constraints described below.
In-span column constraints
The in_span column (denoted as ) is used to identify rows which execute non-control flow operations. The values in this column are set as follows:
- Executing a
SPANoperation sets the value ofin_spancolumn to . - The value remains until the
ENDoperation is executed. - If
RESPANoperation is executed betweenSPANandENDoperations, in the row at whichRESPANoperation is executedin_spanis set to . It is then reset to in the following row. - In all other cases, value in the
in_spancolumn should be .
The picture below illustrates the above rules.

To enforce the above rules we need the following constraints.
When executing SPAN or RESPAN operation, the next value in column must be set to :
When the next operation is END or RESPAN, the next value in column must be set .
In all other cases, the value in column must be copied over to the next row:
Additionally, we will need to impose a boundary constraint which specifies that the first value in . Note, however, that we do not need to impose a constraint ensuring that values in are binary - this will follow naturally from the above constraints.
Also, note that the combination of the above constraints makes it impossible to execute END or RESPAN operations right after SPAN or RESPAN operations.
Block address constraints
When we are inside a span block, values in block address columns (denoted as ) must remain the same. This can be enforced with the following constraint:
Notice that this constraint does not apply when we execute any of the control flow operations. For such operations, the prover sets the value of the column non-deterministically, except for the RESPAN operation. For the RESPAN operation the value in the column is incremented by , which is enforced by a constraint described previously.
Notice also that this constraint implies that when the next operation is the END operation, the value in the column must also be copied over to the next row. This is exactly the behavior we want to enforce so that when the END operation is executed, the block address is set to the address of the current span batch.
Group count constraints
The group_count column (denoted as ) is used to keep track of the number of operation groups which remains to be executed in a span block.
In the beginning of a span block (i.e., when SPAN operation is executed), the prover sets the value of non-deterministically. This value is subsequently decremented according to the rules described below. By the time we exit the span block (i.e., when END operation is executed), the value in must be .
The rules for decrementing values in the column are as follows:
- The count cannot be decremented by more than in a single row.
- When an operation group is fully executed (which happens when inside a span block), the count is decremented by .
- When
SPAN,RESPAN,EMITorPUSHoperations are executed, the count is decremented by .
Note that these rules imply that the EMIT and PUSH operations cannot be the last operation in an operation group (otherwise the count would have to be decremented by ).
To simplify the description of the constraints, we will define the following variable:
Using this variable, we can describe the constraints against the column as follows:
Inside a span block, group count can either stay the same or decrease by one:
When group count is decremented inside a span block, either must be (we consumed all operations in a group) or we must be executing an operation with an immediate value:
Notice that the above constraint does not preclude and from being true at the same time. If this happens, op group decoding constraints (described here) will force that the operation following the operation with an immediate value is a NOOP.
When executing a SPAN, a RESPAN, or an operation with an immediate value, group count must be decremented by :
If the next operation is either an END or a RESPAN, group count must remain the same:
When an END operation is executed, group count must be :
Op group decoding constraints
Inside a span block, register is used to keep track of operations to be executed in the current operation group. The value of this register is set by the prover non-deterministically at the time when the prover executes a SPAN or a RESPAN operation, or when processing of a new operation group within a batch starts. The picture below illustrates this.
In the above:
- The prover sets the value of non-deterministically at row . The value is set to an operation group containing operations
op0throughop8. - As we start executing the group, at every row we "remove" the least significant operation from the group. This can be done by subtracting opcode of the operation from the group, and then dividing the result by .
- By row the group is fully executed. This decrements the group count and set
op_indexto (constraints againstop_indexcolumn are described in the next section). - At row we start executing the next group with operations
op9throughop11. In this case, the prover populates with the group having its first operation (op9) already removed, and sets theop_bitsregisters to the value encodingop9. - By row this group is also fully executed.
To simplify the description of the constraints, we define the following variables:
is just an opcode value implied by the values in op_bits registers. is a flag which is set to when the group count within a span block does not change. We multiply it by to make sure the flag is when we are about to end decoding of an operation batch. Note that flag is mutually exclusive with , , and flags as these three operations decrement the group count.
Using these variables, we can describe operation group decoding constraints as follows:
When a SPAN, a RESPAN, or an operation with an immediate value is executed or when the group count does not change, the value in should be decremented by the value of the opcode in the next row.
Notice that when the group count does change, and we are not executing , , or operations, no constraints are placed against , and thus, the prover can populate this register non-deterministically.
When we are in a span block and the next operation is END or RESPAN, the current value in column must be .
Op index constraints
The op_index column (denoted as ) tracks index of an operation within its operation group. It is used to ensure that the number of operations executed per group never exceeds . The index is zero-based, and thus, the possible set of values for is between and (both inclusive).
To simplify the description of the constraints, we will define the following variables:
The value of is set to when we are about to start executing a new operation group (i.e., group count is decremented but we did not execute an operation with an immediate value). Using these variables, we can describe the constraints against the column as follows.
When executing SPAN or RESPAN operations the next value of op_index must be set to :
When starting a new operation group inside a span block, the next value of op_index must be set to . Note that we multiply by to exclude the cases when the group count is decremented because of SPAN or RESPAN operations:
When inside a span block but not starting a new operation group, op_index must be incremented by . Note that we multiply by to exclude the cases when we are about to exit processing of an operation batch (i.e., the next operation is either END or RESPAN):
Values of op_index must be in the range .
Op batch flags constraints
Operation batch flag columns (denoted , , and ) are used to specify how many operation groups are present in an operation batch. This is relevant for the last batch in a span block (or the first batch if there is only one batch in a block) as all other batches should be completely full (i.e., contain 8 operation groups).
These columns are used to define the following 4 flags:
- : there are 8 operation groups in the batch.
- : there are 4 operation groups in the batch.
- : there are 2 operation groups in the batch.
- : there is only 1 operation groups in the batch.
Notice that the degree of is , while the degree of the remaining flags is .
These flags can be set to only when we are executing SPAN or RESPAN operations as this is when the VM starts processing new operation batches. Also, for a given flag we need to ensure that only the specified number of operations groups are present in a batch. This can be done with the following constraints.
All batch flags must be binary:
When SPAN or RESPAN operations is executed, one of the batch flags must be set to .
When neither SPAN nor RESPAN is executed, all batch flags must be set to .
When we have at most 4 groups in a batch, registers should be set to 's.
When we have at most 2 groups in a batch, registers and should also be set to 's.
When we have at most 1 groups in a batch, register should also be set to .
Op group table constraints
Op group table is used to ensure that all operation groups in a given batch are consumed before a new batch is started (i.e., via a RESPAN operation) or the execution of a span block is complete (i.e., via an END operation). The op group table is updated according to the following rules:
- When a new operation batch is started, we add groups from this batch to the table. To add a group to the table, we multiply the value in column by a value representing a tuple
(batch_id, group_pos, group). A constraint to enforce this would look as , where is the value representing the row to be added. Depending on the batch, we may need to add multiple groups to the table (i.e., ). Flags , , , and are used to define how many groups to add. - When a new operation group starts executing or when an immediate value is consumed, we remove the corresponding group from the table. To do this, we divide the value in column by a value representing a tuple
(batch_id, group_pos, group). A constraint to enforce this would look as , where is the value representing the row to be removed.
To simplify constraint descriptions, we first define variables representing the rows to be added to and removed from the op group table.
When a SPAN or a RESPAN operation is executed, we compute the values of the rows to be added to the op group table as follows:
Where . Thus, defines row value for group in , defines row value for group etc. Note that batch address column comes from the next row of the block address column ().
We compute the value of the row to be removed from the op group table as follows:
In the above, the value of the group is computed as . This basically says that when we execute a PUSH or EMIT operation we need to remove the immediate value from the table. For PUSH, this value is at the top of the stack (column ) in the next row; for EMIT, it is found in . However, when we are executing neither a PUSH nor EMIT operation, the value to be removed is an op group value which is a combination of values in and op_bits columns (also in the next row). Note also that value for batch address comes from the current value in the block address column (), and the group position comes from the current value of the group count column ().
We also define a flag which is set to when a group needs to be removed from the op group table.
The above says that we remove groups from the op group table whenever group count is decremented. We multiply by to exclude the cases when the group count is decremented due to SPAN or RESPAN operations.
Using the above variables together with flags , , defined in the previous section, we describe the constraint for updating op group table as follows (note that we do not use flag as when a batch consists of a single group, nothing is added to the op group table):
The above constraint specifies that:
- When
SPANorRESPANoperations are executed, we add between and groups to the op group table; else, leave untouched. - When group count is decremented inside a span block, we remove a group from the op group table; else, leave untouched.
The degree of this constraint is .
In addition to the above transition constraint, we also need to impose boundary constraints against the column to make sure the first and the last value in the column is set to . This enforces that the op group table table starts and ends in an empty state.
Operand stack
Miden VM is a stack machine. The stack is a push-down stack of practically unlimited depth (in practical terms, the depth will never exceed ), but only the top items are directly accessible to the VM. Items on the stack are elements in a prime field with modulus .
To keep the constraint system for the stack manageable, we impose the following rules:
- All operations executed on the VM can shift the stack by at most one item. That is, the end result of an operation must be that the stack shrinks by one item, grows by one item, or the number of items on the stack stays the same.
- Stack depth must always be greater than or equal to . At the start of program execution, the stack is initialized with exactly input values, all of which could be 's.
- By the end of program execution, exactly items must remain on the stack (again, all of them could be 's). These items comprise the output of the program.
To ensure that managing stack depth does not impose significant burden, we adopt the following rule:
- When the stack depth is , removing additional items from the stack does not change its depth. To keep the depth at , 's are inserted into the deep end of the stack for each removed item.
Stack representation
The VM allocates trace columns for the stack. The layout of the columns is illustrated below.

The meaning of the above columns is as follows:
- are the columns representing the top slots of the stack.
- Column contains the number of items on the stack (i.e., the stack depth). In the above picture, there are 16 items on the stacks, so .
- Column contains an address of a row in the "overflow table" in which we'll store the data that doesn't fit into the top slots. When , it means that all stack data fits into the top slots of the stack.
- Helper column is used to ensure that stack depth does not drop below . Values in this column are set by the prover non-deterministically to when , and to any other value otherwise.
Overflow table
To keep track of the data which doesn't fit into the top stack slots, we'll use an overflow table. This will be a virtual table. To represent this table, we'll use a single auxiliary column .
The table itself can be thought of as having 3 columns as illustrated below.
The meaning of the columns is as follows:
- Column contains row address. Every address in the table must be unique.
- Column contains the value that overflowed the stack.
- Column contains the address of the row containing the value that overflowed the stack right before the value in the current row. For example, in the picture above, first value overflowed the stack, then overflowed the stack, and then value overflowed the stack. Thus, row with value points back to the row with value , and row with value points back to the row with value .
To reduce a table row to a single value, we'll compute a randomized product of column values as follows:
Then, when row is added to the table, we'll update the value in the column like so:
Analogously, when row is removed from the table, we'll update the value in column like so:
The initial value of is set to . Thus, if by the time Miden VM finishes executing a program the table is empty (we added and then removed exactly the same set of rows), will also be equal to .
There are a couple of other rules we'll need to enforce:
- We can delete a row only after the row has been inserted into the table.
- We can't insert a row with the same address twice into the table (even if the row was inserted and then deleted).
How these are enforced will be described a bit later.
Right shift
If an operation adds data to the stack, we say that the operation caused a right shift. For example, PUSH and DUP operations cause a right shift. Graphically, this looks like so:
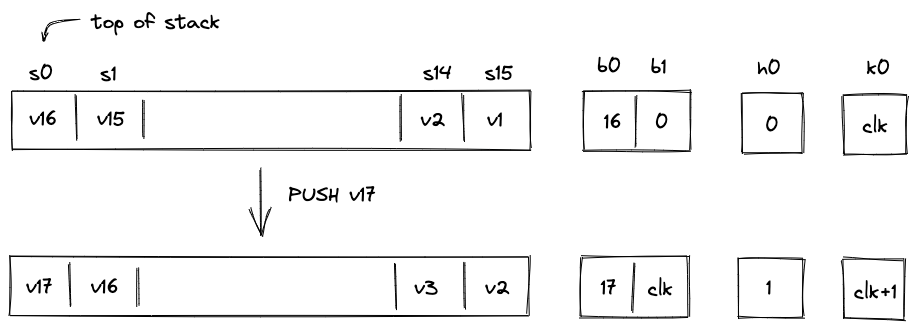
Here, we pushed value onto the stack. All other values on the stack are shifted by one slot to the right and the stack depth increases by . There is not enough space at the top of the stack for all values, thus, needs to be moved to the overflow table.
To do this, we need to rely on another column: . This is a system column which keeps track of the current VM cycle. The value in this column is simply incremented by with every step.
The row we want to add to the overflow table is defined by tuple , and after it is added, the table would look like so:

The reason we use VM clock cycle as row address is that the clock cycle is guaranteed to be unique, and thus, the same row can not be added to the table twice.
Let's push another item onto the stack:
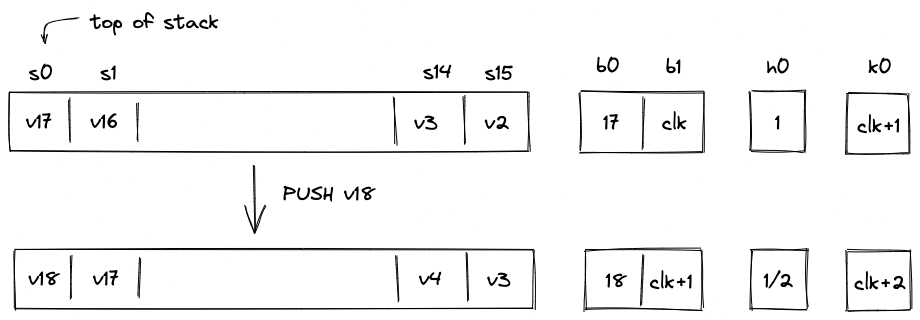
Again, as we push onto the stack, all items on the stack are shifted to the right, and now needs to be moved to the overflow table. The tuple we want to insert into the table now is . After the operation, the overflow table will look like so:

Notice that for row which contains value points back to the row with address .
Overall, during a right shift we do the following:
- Increment stack depth by .
- Shift stack columns right by slot.
- Add a row to the overflow table described by tuple .
- Set the next value of to the current value of .
Also, as mentioned previously, the prover sets values in non-deterministically to .
Left shift
If an operation removes an item from the stack, we say that the operation caused a left shift. For example, a DROP operation causes a left shift. Assuming the stack is in the state we left it at the end of the previous section, graphically, this looks like so:
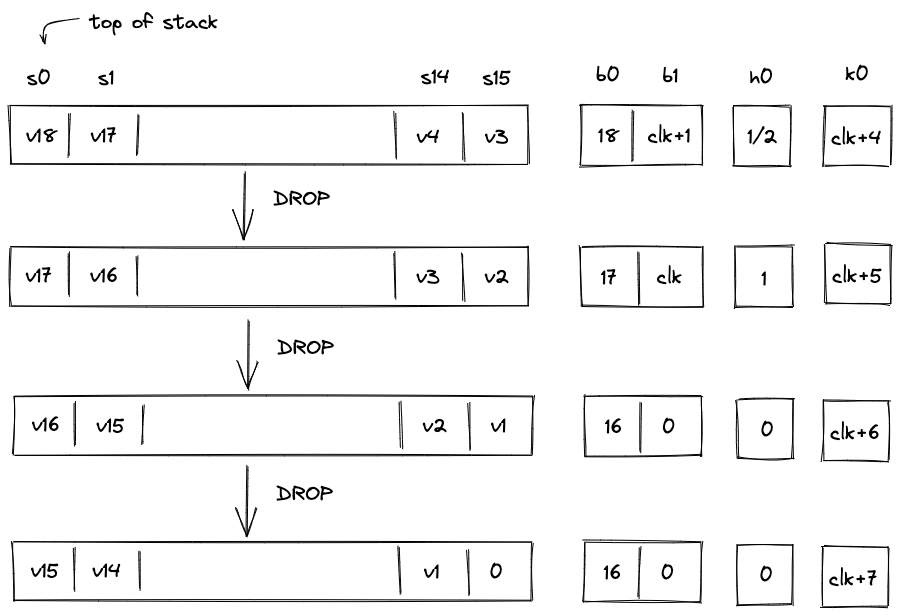
Overall, during the left shift we do the following:
- When stack depth is greater than :
- Decrement stack depth by .
- Shift stack columns left by slot.
- Remove a row from the overflow table with equal to the current value of .
- Set the next value of to the value in of the removed overflow table row.
- Set the next value of to the value in of the removed overflow table row.
- When the stack depth is equal to :
- Keep the stack depth the same.
- Shift stack columns left by slot.
- Set the value of to .
- Set the value to to (or any other value).
If the stack depth becomes (or remains) , the prover can set to any value (e.g., ). But if the depth is greater than the prover sets to .
AIR Constraints
To simplify constraint descriptions, we'll assume that the VM exposes two binary flag values described below.
| Flag | Degree | Description |
|---|---|---|
| 6 | When this flag is set to , the instruction executing on the VM is performing a "right shift". | |
| 5 | When this flag is set to , the instruction executing on the VM is performing a "left shift". |
These flags are mutually exclusive. That is, if , then and vice versa. However, both flags can be set to simultaneously. This happens when the executed instruction does not shift the stack. How these flags are computed is described here.
Stack overflow flag
Additionally, we'll define a flag to indicate whether the overflow table contains values. This flag will be set to when the overflow table is empty, and to otherwise (i.e., when stack depth ). This flag can be computed as follows:
To ensure that this flag is set correctly, we need to impose the following constraint:
The above constraint can be satisfied only when either of the following holds:
- , in which case evaluates to , regardless of the value of .
- , in which case cannot be equal to (and must be set to ).
Stack depth constraints
To make sure stack depth column is updated correctly, we need to impose the following constraints:
| Condition | Constraint__ | Description |
|---|---|---|
| When the stack is shifted to the right, stack depth should be incremented by . | ||
| | When the stack is shifted to the left and the overflow table is not empty, stack depth should be decremented by . | |
| otherwise | In all other cases, stack depth should not change. |
We can combine the above constraints into a single expression as follows:
Overflow table constraints
When the stack is shifted to the right, a tuple should be added to the overflow table. We will denote value of the row to be added to the table as follows:
When the stack is shifted to the left, a tuple should be removed from the overflow table. We will denote value of the row to be removed from the table as follows.
Using the above variables, we can ensure that right and left shifts update the overflow table correctly by enforcing the following constraint:
The above constraint reduces to the following under various flag conditions:
| Condition | Applied constraint |
|---|---|
| , , | |
| , , | |
| , , | |
| , , |
Notice that in the case of the left shift, the constraint forces the prover to set the next values of and to values and of the row removed from the overflow table.
In case of a right shift, we also need to make sure that the next value of is set to the current value of . This can be done with the following constraint:
In case of a left shift, when the overflow table is empty, we need to make sure that a is "shifted in" from the right (i.e., is set to ). This can be done with the following constraint:
Boundary constraints
In addition to the constraints described above, we also need to enforce the following boundary constraints:
- at the first and at the last row of execution trace.
- at the first and at the last row of execution trace.
- at the first and at the last row of execution trace.
Stack operation constraints
In addition to the constraints described in the previous section, we need to impose constraints to check that each VM operation is executed correctly.
For this purpose the VM exposes a set of operation-specific flags. These flags are set to when a given operation is executed, and to otherwise. The naming convention for these flags is . For example, would be set to when DUP operation is executed, and to otherwise. Operation flags are discussed in detail in the section below.
To describe how operation-specific constraints work, let's use an example with DUP operation. This operation pushes a copy of the top stack item onto the stack. The constraints we need to impose for this operation are as follows:
The first constraint enforces that the top stack item in the next row is the same as the top stack item in the current row. The second constraint enforces that all stack items (starting from item ) are shifted to the right by . We also need to impose all the constraints discussed in the previous section, be we omit them here.
Let's write similar constraints for DUP1 operation, which pushes a copy of the second stack item onto the stack:
It is easy to notice that while the first constraint changed, the second constraint remained the same - i.e., we are still just shifting the stack to the right.
In fact, for most operations it makes sense to make a distinction between constraints unique to the operation vs. more general constraints which enforce correct behavior for the stack items not affected by the operation. In the subsequent sections we describe in detail only the former constraints, and provide high-level descriptions of the more general constraints. Specifically, we indicate how the operation affects the rest of the stack (e.g., shifts right starting from position ).
Operation flags
As mentioned above, operation flags are used as selectors to enforce operation-specific constraints. That is, they turn on relevant constraints for a given operation. In total, the VM provides unique operations, and thus, there are operation flags (not all of them currently used).
Operation flags are mutually exclusive. That is, if one flag is set to , all other flags are set to . Also, one of the flags is always guaranteed to be set to .
To compute values of operation flags we use op bits registers located in the decoder. These registers contain binary representations of operation codes (opcodes). Each opcode consists of bits, and thus, there are op bits registers. We denote these registers as . The values are computed by multiplying the op bit registers in various combinations. Notice that binary encoding down below is showed in big-endian order, so the flag bits correspond to the reverse order of the op bits registers, from to .
For example, the value of the flag for NOOP, which is encoded as 0000000, is computed as follows:
While the value of the DROP operation, which is encoded as 0101001 is computed as follows:
As can be seen from above, the degree for both of these flags is . Since degree of constraints in Miden VM can go up to , this means that operation-specific constraints cannot exceed degree . However, there are some operations which require constraints of higher degree (e.g., or even ). To support such constraints, we adopt the following scheme.
We organize the operations into groups as shown below and also introduce two extra registers and for degree reduction:
| # of ops | degree | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | x | x | x | x | x | x | 0 | 0 | 64 | 7 |
| 1 | 0 | 0 | x | x | x | - | 0 | 0 | 8 | 6 |
| 1 | 0 | 1 | x | x | x | x | 1 | 0 | 16 | 5 |
| 1 | 1 | x | x | x | - | - | 0 | 1 | 8 | 4 |
In the above:
- Operation flags for operations in the first group (with prefix
0), are computed using all op bits, and thus their degree is . - Operation flags for operations in the second group (with prefix
100), are computed using only the first op bits, and thus their degree is . - Operation flags for operations in the third group (with prefix
101), are computed using all op bits. We use the extra register (which is set to ) to reduce the degree by . Thus, the degree of op flags in this group is . - Operation flags for operations in the fourth group (with prefix
11), are computed using only the first op bits. We use the extra register (which is set to ) to reduce the degree by . Thus, the degree of op flags in this group is .
How operations are distributed between these groups is described in the sections below.
No stack shift operations
This group contains operations which do not shift the stack (this is almost all such operations). Since the op flag degree for these operations is , constraints for these operations cannot exceed degree .
| Operation | Opcode value | Binary encoding | Operation group | Flag degree |
|---|---|---|---|---|
NOOP | 000_0000 | System ops | ||
EQZ | 000_0001 | Field ops | ||
NEG | 000_0010 | Field ops | ||
INV | 000_0011 | Field ops | ||
INCR | 000_0100 | Field ops | ||
NOT | 000_0101 | Field ops | ||
FMPADD | 000_0110 | System ops | ||
MLOAD | 000_0111 | I/O ops | ||
SWAP | 000_1000 | Stack ops | ||
CALLER | 000_1001 | System ops | ||
MOVUP2 | 000_1010 | Stack ops | ||
MOVDN2 | 000_1011 | Stack ops | ||
MOVUP3 | 000_1100 | Stack ops | ||
MOVDN3 | 000_1101 | Stack ops | ||
ADVPOPW | 000_1110 | I/O ops | ||
EXPACC | 000_1111 | Field ops | ||
MOVUP4 | 001_0000 | Stack ops | ||
MOVDN4 | 001_0001 | Stack ops | ||
MOVUP5 | 001_0010 | Stack ops | ||
MOVDN5 | 001_0011 | Stack ops | ||
MOVUP6 | 001_0100 | Stack ops | ||
MOVDN6 | 001_0101 | Stack ops | ||
MOVUP7 | 001_0110 | Stack ops | ||
MOVDN7 | 001_0111 | Stack ops | ||
SWAPW | 001_1000 | Stack ops | ||
EXT2MUL | 001_1001 | Field ops | ||
MOVUP8 | 001_1010 | Stack ops | ||
MOVDN8 | 001_1011 | Stack ops | ||
SWAPW2 | 001_1100 | Stack ops | ||
SWAPW3 | 001_1101 | Stack ops | ||
SWAPDW | 001_1110 | Stack ops | ||
<unused> | 001_1111 |
Left stack shift operations
This group contains operations which shift the stack to the left (i.e., remove an item from the stack). Most of left-shift operations are contained in this group. Since the op flag degree for these operations is , constraints for these operations cannot exceed degree .
| Operation | Opcode value | Binary encoding | Operation group | Flag degree |
|---|---|---|---|---|
ASSERT | 010_0000 | System ops | ||
EQ | 010_0001 | Field ops | ||
ADD | 010_0010 | Field ops | ||
MUL | 010_0011 | Field ops | ||
AND | 010_0100 | Field ops | ||
OR | 010_0101 | Field ops | ||
U32AND | 010_0110 | u32 ops | ||
U32XOR | 010_0111 | u32 ops | ||
FRIE2F4 | 010_1000 | Crypto ops | ||
DROP | 010_1001 | Stack ops | ||
CSWAP | 010_1010 | Stack ops | ||
CSWAPW | 010_1011 | Stack ops | ||
MLOADW | 010_1100 | I/O ops | ||
MSTORE | 010_1101 | I/O ops | ||
MSTOREW | 010_1110 | I/O ops | ||
FMPUPDATE | 010_1111 | System ops |
Right stack shift operations
This group contains operations which shift the stack to the right (i.e., push a new item onto the stack). Most of right-shift operations are contained in this group. Since the op flag degree for these operations is , constraints for these operations cannot exceed degree .
| Operation | Opcode value | Binary encoding | Operation group | Flag degree |
|---|---|---|---|---|
PAD | 011_0000 | Stack ops | ||
DUP | 011_0001 | Stack ops | ||
DUP1 | 011_0010 | Stack ops | ||
DUP2 | 011_0011 | Stack ops | ||
DUP3 | 011_0100 | Stack ops | ||
DUP4 | 011_0101 | Stack ops | ||
DUP5 | 011_0110 | Stack ops | ||
DUP6 | 011_0111 | Stack ops | ||
DUP7 | 011_1000 | Stack ops | ||
DUP9 | 011_1001 | Stack ops | ||
DUP11 | 011_1010 | Stack ops | ||
DUP13 | 011_1011 | Stack ops | ||
DUP15 | 011_1100 | Stack ops | ||
ADVPOP | 011_1101 | I/O ops | ||
SDEPTH | 011_1110 | I/O ops | ||
CLK | 011_1111 | System ops |
u32 operations
This group contains u32 operations. These operations are grouped together because all of them require range checks. The constraints for range checks are of degree , however, since all these operations require them, we can define a flag with common prefix 100 to serve as a selector for the range check constraints. The value of this flag is computed as follows:
The degree of this flag is , which is acceptable for a selector for degree constraints.
| Operation | Opcode value | Binary encoding | Operation group | Flag degree |
|---|---|---|---|---|
U32ADD | 100_0000 | u32 ops | ||
U32SUB | 100_0010 | u32 ops | ||
U32MUL | 100_0100 | u32 ops | ||
U32DIV | 100_0110 | u32 ops | ||
U32SPLIT | 100_1000 | u32 ops | ||
U32ASSERT2 | 100_1010 | u32 ops | ||
U32ADD3 | 100_1100 | u32 ops | ||
U32MADD | 100_1110 | u32 ops |
As mentioned previously, the last bit of the opcode is not used in computation of the flag for these operations. We force this bit to always be set to with the following constraint:
Putting these operations into a group with flag degree is important for two other reasons:
- Constraints for the
U32SPLIToperation have degree . Thus, the degree of the op flag for this operation cannot exceed . - Operations
U32ADD3andU32MADDshift the stack to the left. Thus, having these two operations in this group and putting them under the common prefix10011allows us to create a common flag for these operations of degree (recall that the left-shift flag cannot exceed degree ).
High-degree operations
This group contains operations which require constraints with degree up to . All operation bits are used for these flags. The extra column is used for degree reduction of the three high-degree bits.
| Operation | Opcode value | Binary encoding | Operation group | Flag degree |
|---|---|---|---|---|
HPERM | 101_0000 | Crypto ops | ||
MPVERIFY | 101_0001 | Crypto ops | ||
PIPE | 101_0010 | I/O ops | ||
MSTREAM | 101_0011 | I/O ops | ||
SPLIT | 101_0100 | Flow control ops | ||
LOOP | 101_0101 | Flow control ops | ||
SPAN | 101_0110 | Flow control ops | ||
JOIN | 101_0111 | Flow control ops | ||
DYN | 101_1000 | Flow control ops | ||
HORNEREXT | 101_1001 | Crypto ops | ||
EMIT | 101_1010 | System ops | ||
PUSH | 101_1011 | I/O ops | ||
DYNCALL | 101_1100 | Flow control ops | ||
<unused> | 101_1101 | |||
<unused> | 101_1110 | |||
<unused> | 101_1111 |
Note that the SPLIT and LOOP operations are grouped together under the common prefix 101010, and thus can have a common flag of degree (using for degree reduction). This is important because both of these operations shift the stack to the left.
Also, we need to make sure that extra register , which is used to reduce the flag degree by , is set to when , , and :
Very high-degree operations
This group contains operations which require constraints with degree up to .
| Operation | Opcode value | Binary encoding | Operation group | Flag degree |
|---|---|---|---|---|
MRUPDATE | 110_0000 | Crypto ops | ||
HORNERBASE | 110_0100 | Crypto ops | ||
SYSCALL | 110_1000 | Flow control ops | ||
CALL | 110_1100 | Flow control ops | ||
END | 111_0000 | Flow control ops | ||
REPEAT | 111_0100 | Flow control ops | ||
RESPAN | 111_1000 | Flow control ops | ||
HALT | 111_1100 | Flow control ops |
As mentioned previously, the last two bits of the opcode are not used in computation of the flag for these operations. We force these bits to always be set to with the following constraints:
Also, we need to make sure that extra register , which is used to reduce the flag degree by , is set to when both and columns are set to :
Composite flags
Using the operation flags defined above, we can compute several composite flags which are used by various constraints in the VM.
Shift right flag
The right-shift flag indicates that an operation shifts the stack to the right. This flag is computed as follows:
In the above, evaluates to for all right stack shift operations described previously. This works because all these operations have a common prefix 011. We also need to add in flags for other operations which shift the stack to the right but are not a part of the above group (e.g., PUSH operation).
Shift left flag
The left-shift flag indicates that a given operation shifts the stack to the left. To simplify the description of this flag, we will first compute the following intermediate variables:
A flag which is set to when or :
A flag which is set to when or :
Using the above variables, we compute left-shift flag as follows:
In the above:
- evaluates to for all left stack shift operations described previously. This works because all these operations have a common prefix
010. - is the helper register in the decoder which is set to when we are exiting a
LOOPblock, and to otherwise.
Thus, similarly to the right-shift flag, we compute the value of the left-shift flag based on the prefix of the operation group which contains most left shift operations, and add in flag values for other operations which shift the stack to the left but are not a part of this group.
Control flow flag
The control flow flag is set to when a control flow operation is being executed by the VM, and to otherwise. Naively, this flag can be computed as follows:
However, this can be computed more efficiently via the common operation prefixes for the two groups of control flow operations as follows.
Immediate value flag
The immediate value flag is set to 1 when an operation has an immediate value, and 0 otherwise:
Note that the ASSERT, MPVERIFY and other operations have immediate values too. However, these immediate values are not included in the MAST digest, and hence are not considered for the flag.
System Operations
In this section we describe the AIR constraints for Miden VM system operations.
NOOP
The NOOP operation advances the cycle counter but does not change the state of the operand stack (i.e., the depth of the stack and the values on the stack remain the same).
The NOOP operation does not impose any constraints besides the ones needed to ensure that the entire state of the stack is copied over. This constraint looks like so:
EMIT
Similarly to NOOP, the EMIT operation advances the cycle counter but does not change the state of the operand stack (i.e., the depth of the stack and the values on the stack remain the same).
The EMIT operation does not impose any constraints besides the ones needed to ensure that the entire state of the stack is copied over. This constraint looks like so:
Additionally, the prover puts EMIT's immediate value in the first user op helper register non-deterministically. The Op Group Table is responsible for ensuring that the prover sets the appropriate value.
ASSERT
The ASSERT operation pops an element off the stack and checks if the popped element is equal to . If the element is not equal to , program execution fails.
Stack transition for this operation must satisfy the following constraints:
The effect on the rest of the stack is:
- Left shift starting from position .
FMPADD
The FMPADD operation pops an element off the stack, adds the current value of the fmp register to it, and pushes the result back onto the stack. The diagram below illustrates this graphically.
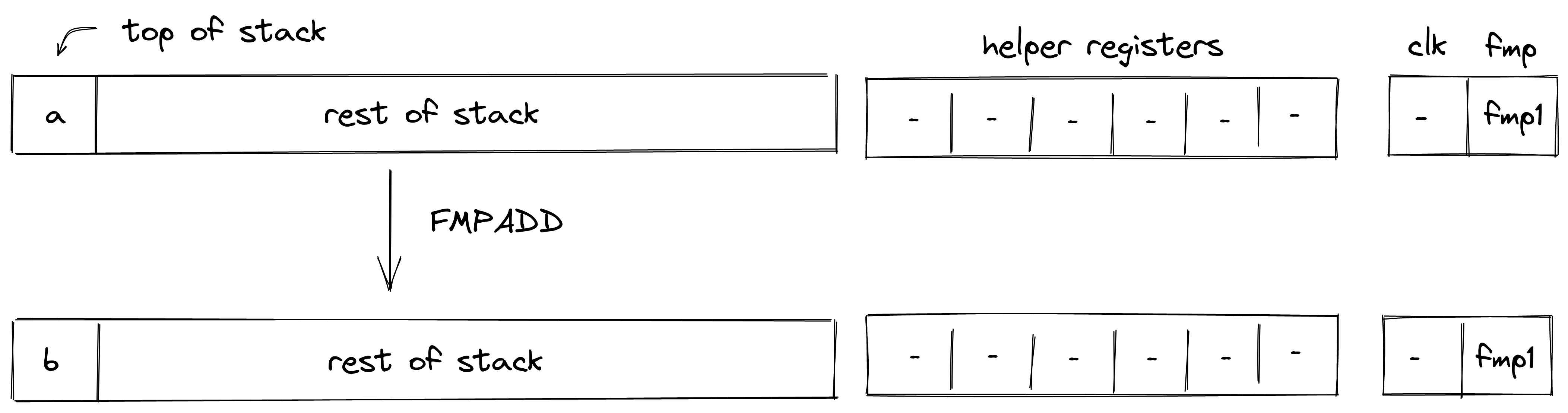
Stack transition for this operation must satisfy the following constraints:
The effect on the rest of the stack is:
- No change starting from position .
FMPUPDATE
The FMPUPDATE operation pops an element off the stack and adds it to the current value of the fmp register. The diagram below illustrates this graphically.
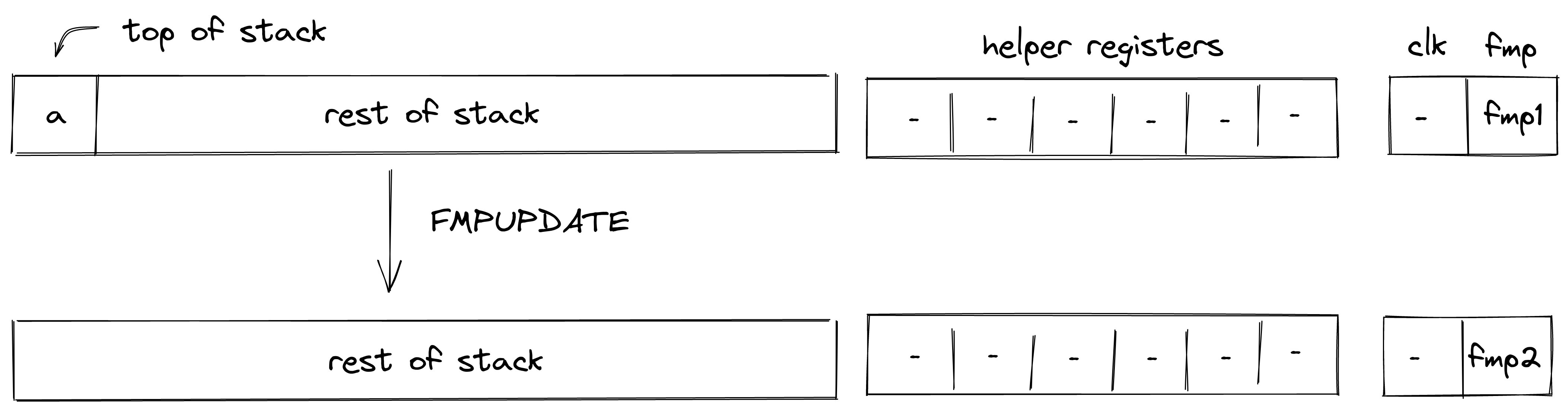
The stack transition for this operation must follow the following constraint:
The effect on the rest of the stack is:
- Left shift starting from position .
CLK
The CLK operation pushes the current value of the clock cycle onto the stack. The diagram below illustrates this graphically.
The stack transition for this operation must follow the following constraint:
The effect on the rest of the stack is:
- Right shift starting from position .
Field Operations
In this section we describe the AIR constraints for Miden VM field operations (i.e., arithmetic operations over field elements).
ADD
Assume and are the elements at the top of the stack. The ADD operation computes . The diagram below illustrates this graphically.
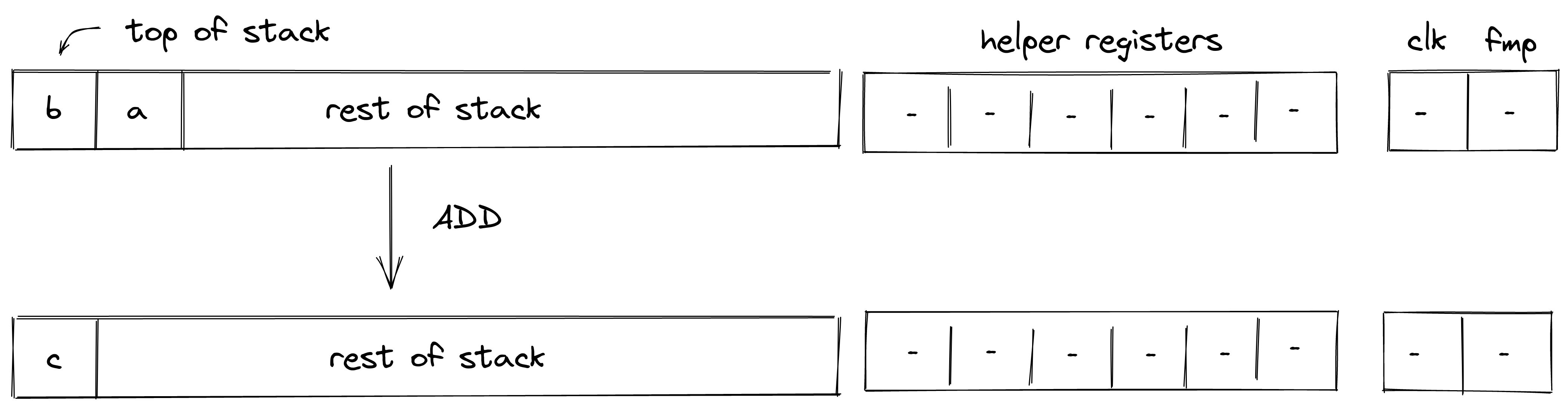
Stack transition for this operation must satisfy the following constraints:
The effect on the rest of the stack is:
- Left shift starting from position .
NEG
Assume is the element at the top of the stack. The NEG operation computes . The diagram below illustrates this graphically.
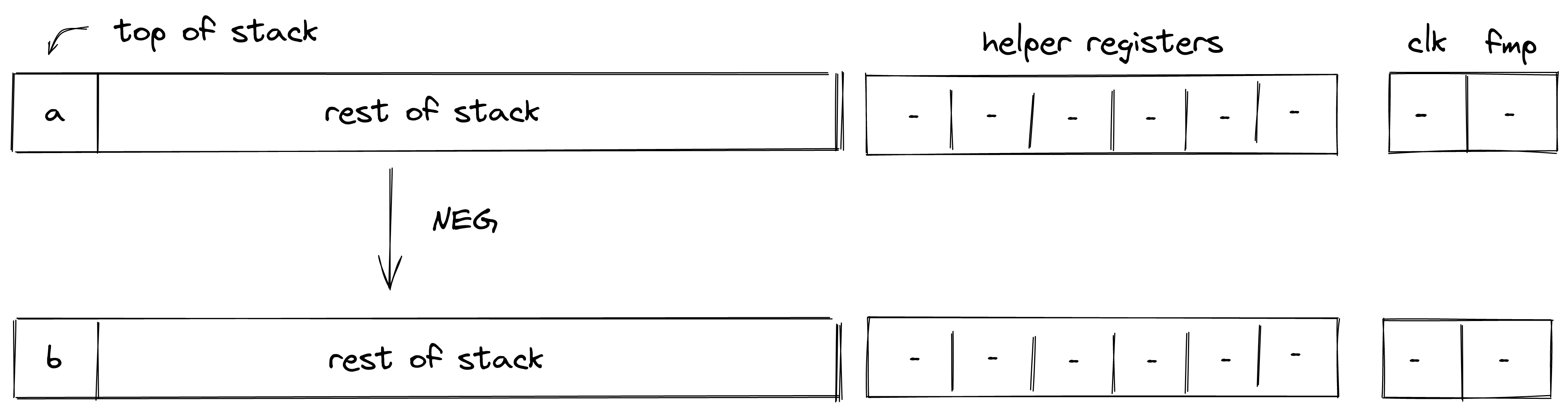
Stack transition for this operation must satisfy the following constraints:
The effect on the rest of the stack is:
- No change starting from position .
MUL
Assume and are the elements at the top of the stack. The MUL operation computes . The diagram below illustrates this graphically.
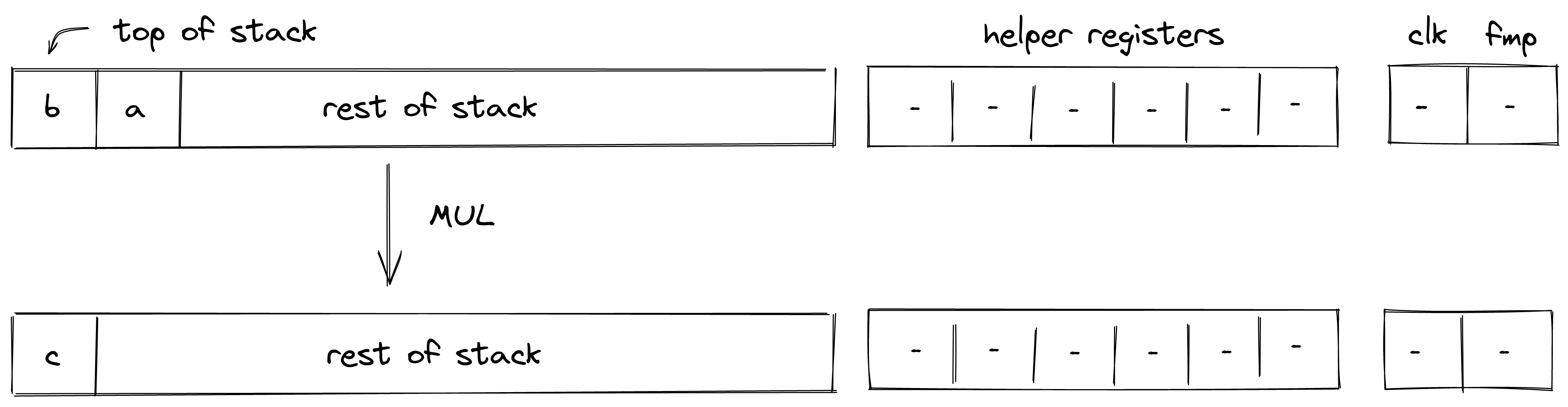
Stack transition for this operation must satisfy the following constraints:
The effect on the rest of the stack is:
- Left shift starting from position .
INV
Assume is the element at the top of the stack. The INV operation computes . The diagram below illustrates this graphically.
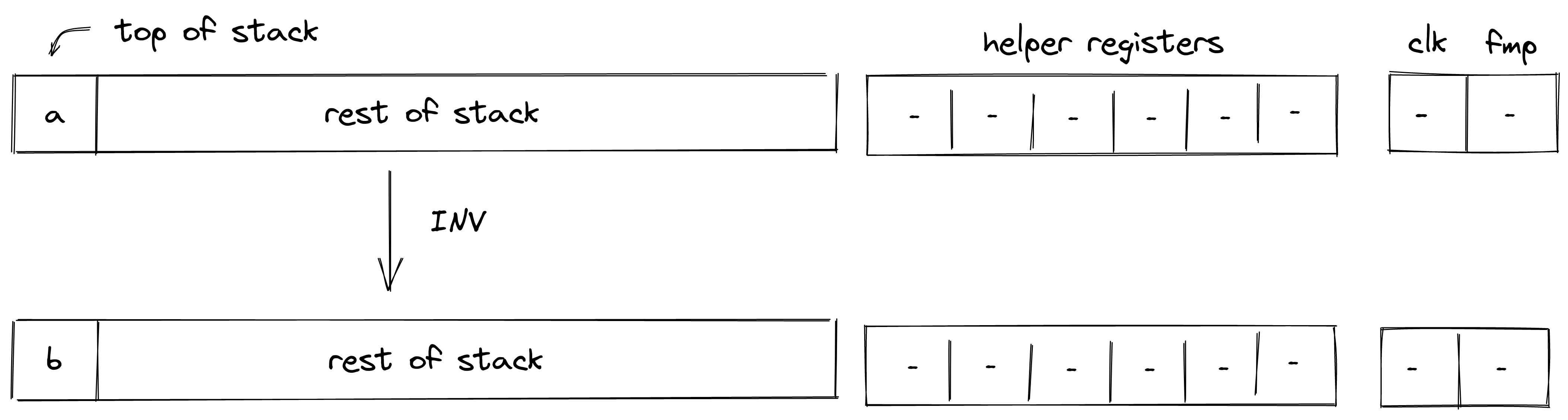
Stack transition for this operation must satisfy the following constraints:
Note that the above constraint can be satisfied only if the value in .
The effect on the rest of the stack is:
- No change starting from position .
INCR
Assume is the element at the top of the stack. The INCR operation computes . The diagram below illustrates this graphically.
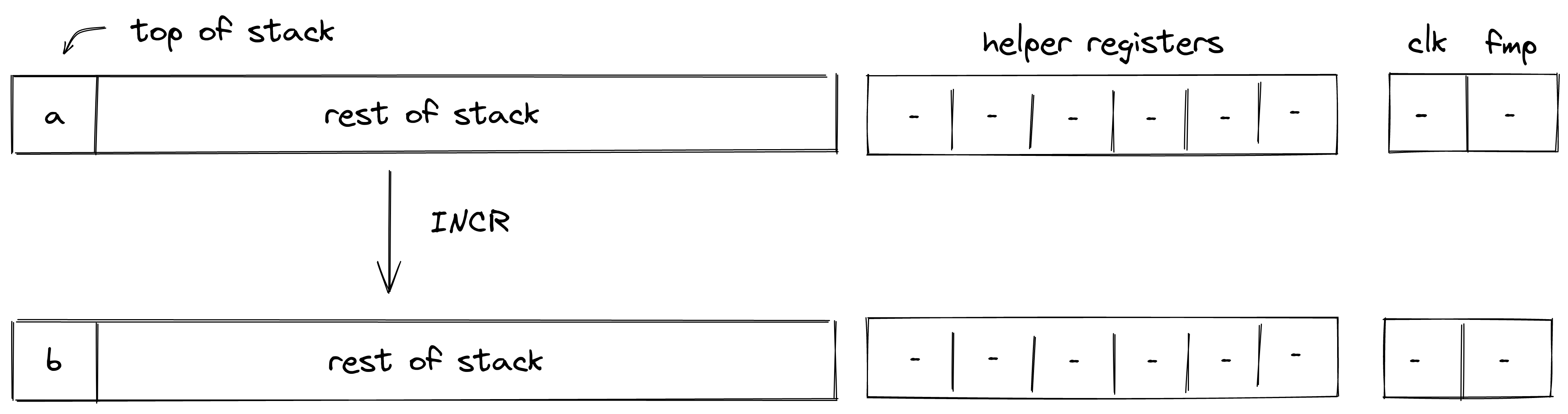
Stack transition for this operation must satisfy the following constraints:
The effect on the rest of the stack is:
- No change starting from position .
NOT
Assume is a binary value at the top of the stack. The NOT operation computes . The diagram below illustrates this graphically.
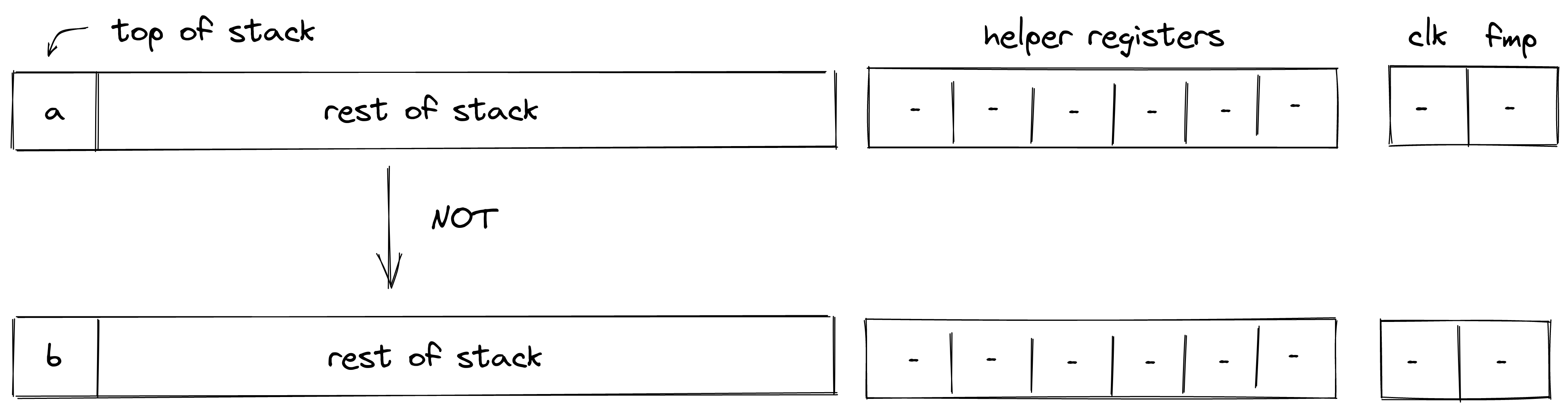
Stack transition for this operation must satisfy the following constraints:
The first constraint ensures that the value in is binary, and the second constraint ensures the correctness of the boolean NOT operation.
The effect on the rest of the stack is:
- No change starting from position .
AND
Assume and are binary values at the top of the stack. The AND operation computes . The diagram below illustrates this graphically.
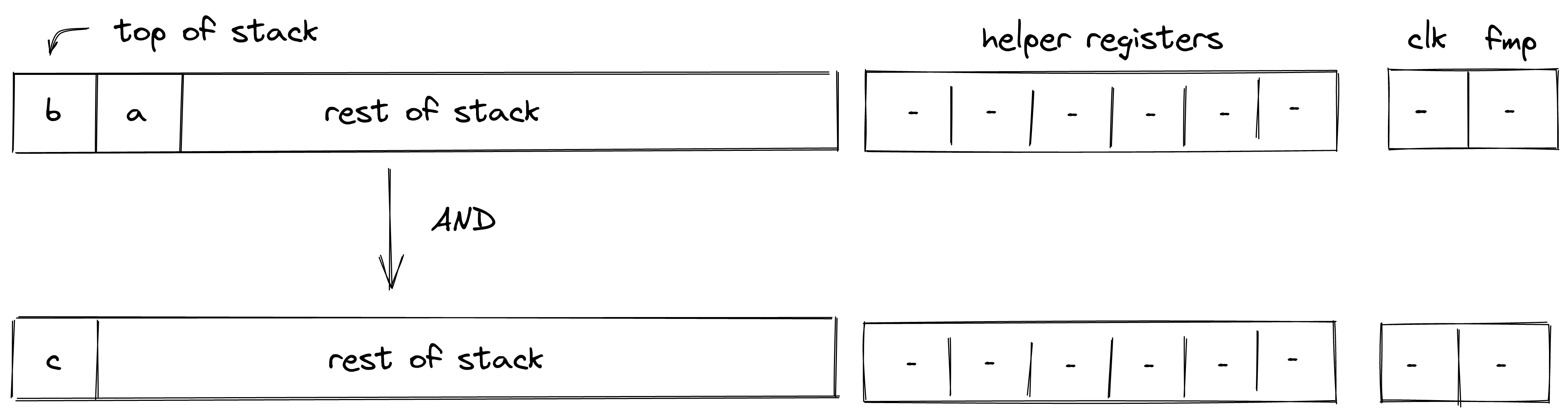
Stack transition for this operation must satisfy the following constraints:
The first two constraints ensure that the value in and are binary, and the third constraint ensures the correctness of the boolean AND operation.
The effect on the rest of the stack is:
- Left shift starting from position .
OR
Assume and are binary values at the top of the stack. The OR operation computes The diagram below illustrates this graphically.
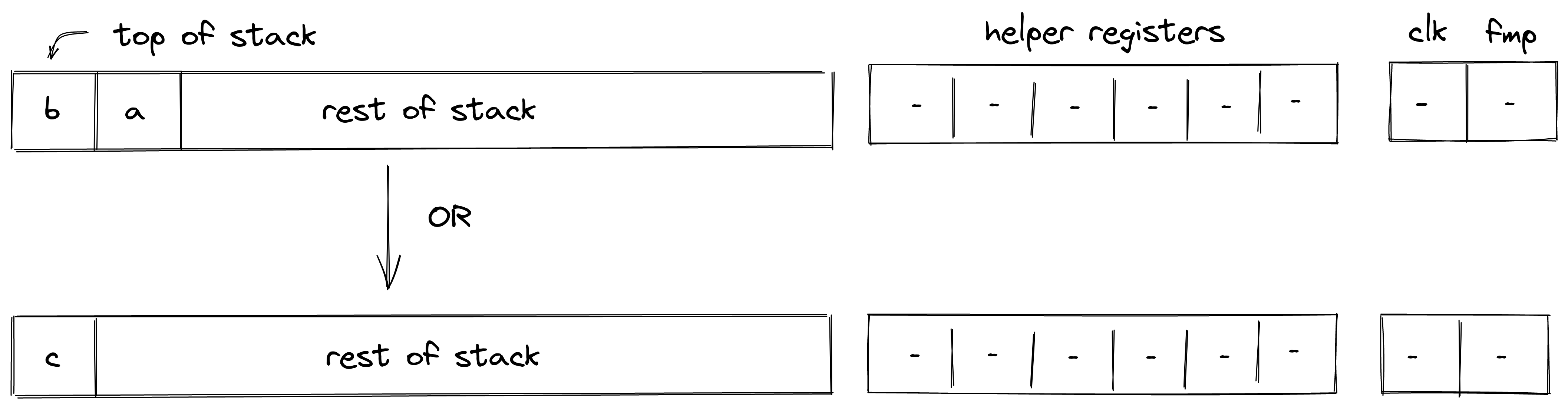
Stack transition for this operation must satisfy the following constraints:
The first two constraints ensure that the value in and are binary, and the third constraint ensures the correctness of the boolean OR operation.
The effect on the rest of the stack is:
- Left shift starting from position .
EQ
Assume and are the elements at the top of the stack. The EQ operation computes such that if , and otherwise. The diagram below illustrates this graphically.
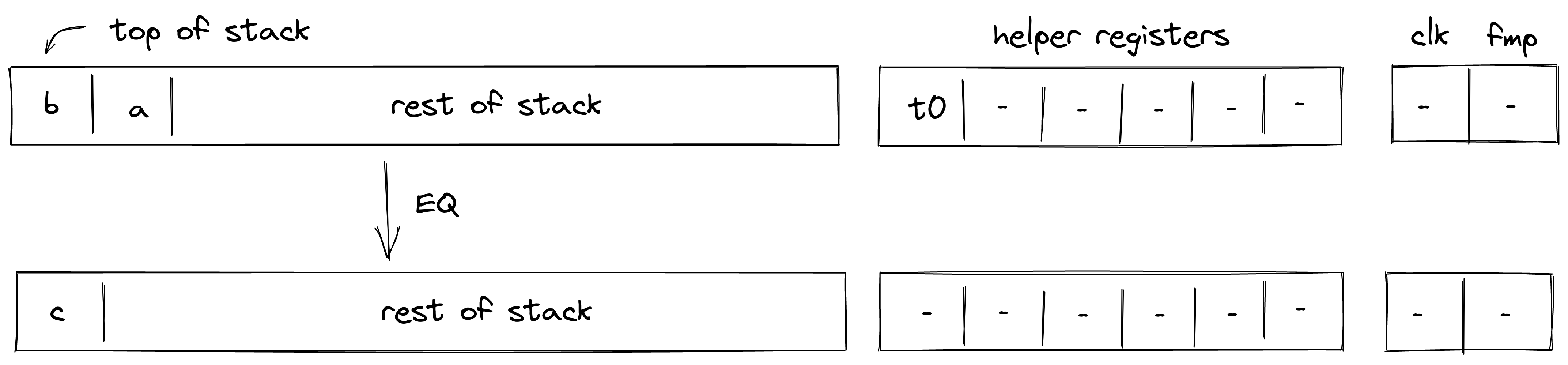
Stack transition for this operation must satisfy the following constraints:
To satisfy the above constraints, the prover must populate the value of helper register as follows:
- If , set .
- Otherwise, set to any value (e.g., ).
The effect on the rest of the stack is:
- Left shift starting from position .
EQZ
Assume is the element at the top of the stack. The EQZ operation computes such that if , and otherwise. The diagram below illustrates this graphically.
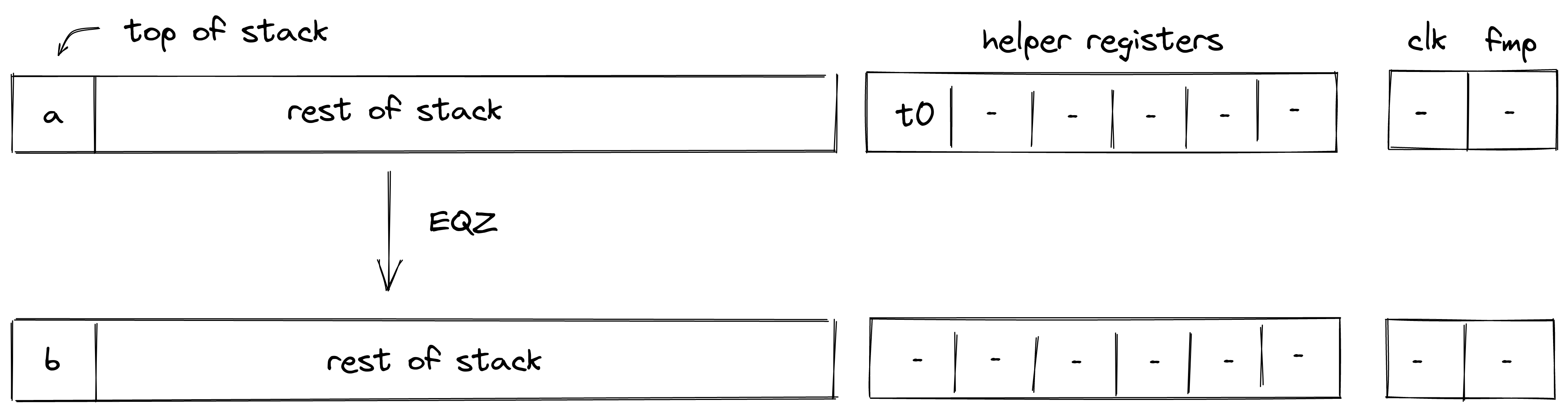
Stack transition for this operation must satisfy the following constraints:
To satisfy the above constraints, the prover must populate the value of helper register as follows:
- If , set .
- Otherwise, set to any value (e.g., ).
The effect on the rest of the stack is:
- No change starting from position .
EXPACC
The EXPACC operation computes one round of the expression . It is expected that Expacc is called at least num_exp_bits times, where num_exp_bits is the number of bits required to represent exp.
It pops elements from the top of the stack, performs a single round of exponent aggregation, and pushes the resulting values onto the stack. The diagram below illustrates this graphically.
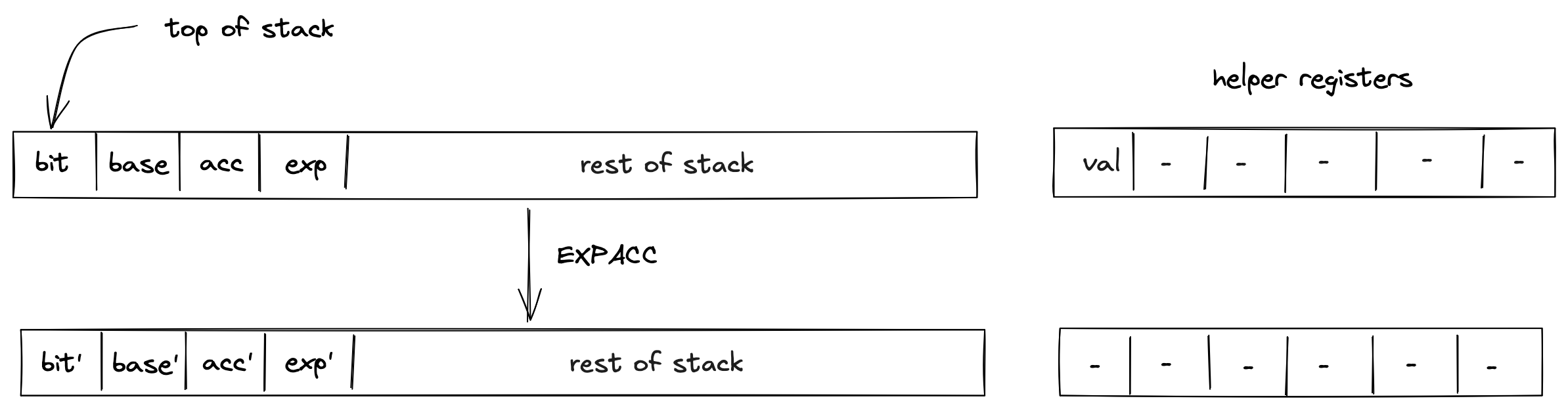
Expacc is based on the observation that the exponentiation of a number can be computed by repeatedly squaring the base and multiplying those powers of the base by the accumulator, for the powers of the base which correspond to the exponent's bits which are set to 1.
For example, take . Over the course of 3 iterations ( is in binary), the algorithm will compute , and (placed in base_acc). Hence, we want to multiply base_acc in acc when and when , which occurs on the first and third iterations (corresponding to the bits in the binary representation of 5).
Stack transition for this operation must satisfy the following constraints:
bit' should be a binary.
The base in the next frame should be the square of the base in the current frame.
The value val in the helper register is computed correctly using the bit and exp in next and current frame respectively.
The acc in the next frame is the product of val and acc in the current frame.
exp in the next frame is half of exp in the current frame (accounting for even/odd).
The effect on the rest of the stack is:
- No change starting from position .
EXT2MUL
The EXT2MUL operation pops top values from the top of the stack, performs multiplication between the two extension field elements, and pushes the resulting values onto the stack. The diagram below illustrates this graphically.
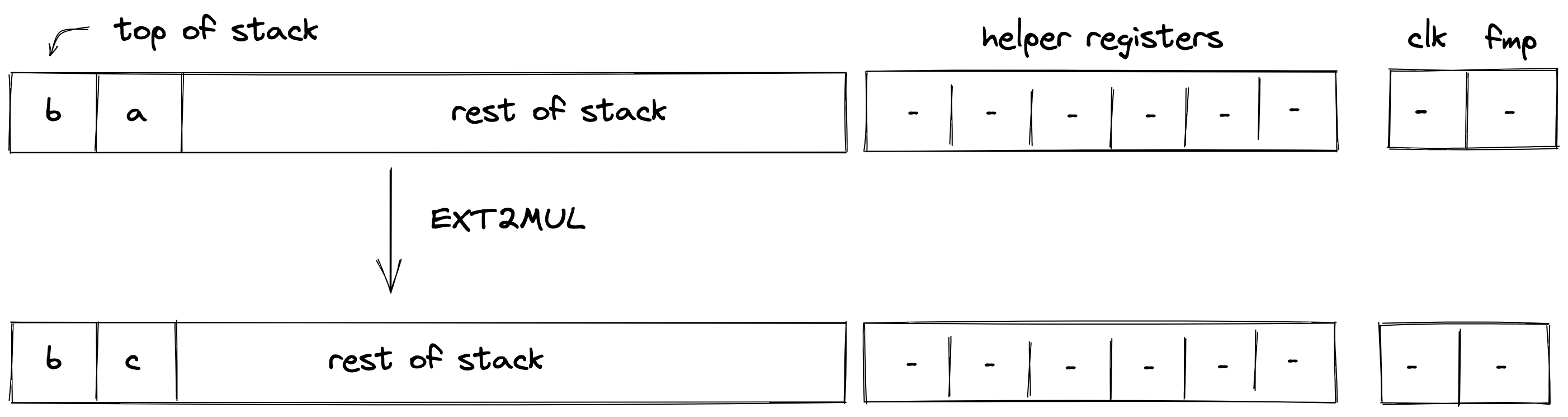
Stack transition for this operation must satisfy the following constraints:
The first stack element should be unchanged in the next frame.
The second stack element should be unchanged in the next frame.
The third stack element should satisfy the following constraint.
The fourth stack element should satisfy the following constraint.
The effect on the rest of the stack is:
- No change starting from position .
u32 Operations
In this section we describe semantics and AIR constraints of operations over u32 values (i.e., 32-bit unsigned integers) as they are implemented in Miden VM.
Range checks
Most operations described below require some number of 16-bit range checks (i.e., verifying that the value of a field element is smaller than ). The number of required range checks varies between and , depending on the operation. However, to simplify the constraint system, we force each relevant operation to consume exactly range checks.
To perform these range checks, the prover puts the values to be range-checked into helper registers , and then updates the range checker bus column according to the LogUp construction described in the range checker documentation, using multiplicity for each value.
This operation is enforced via the following constraint. Note that since constraints cannot include divisions, the actual constraint which is enforced will be expressed equivalently with all denominators multiplied through, resulting in a constraint of degree 5.
The above is just a partial constraint as it does not show the range checker's part of the constraint, which adds the required values into the bus column. It also omits the selector flag which is used to turn this constraint on only when executing relevant operations.
Checking element validity
Another primitive which is required by most of the operations described below is checking whether four 16-bit values form a valid field element. Assume , , , and are known to be 16-bit values, and we want to verify that is a valid field element.
For simplicity, let's denote:
We can then impose the following constraint to verify element validity:
Where is a value set non-deterministically by the prover.
The above constraint should hold only if either of the following hold:
To satisfy the latter equation, the prover needs to set , which is possible only when .
This constraint is sufficient because modulus in binary representation is 32 ones, followed by 31 zeros, followed by a single one:
This implies that the largest possible 64-bit value encoding a valid field element would be 32 ones, followed by 32 zeros:
Thus, for a 64-bit value to encode a valid field element, either the lower 32 bits must be all zeros, or the upper 32 bits must not be all ones (which is ).
U32SPLIT
Assume is the element at the top of the stack. The U32SPLIT operation computes , where contains the lower 32 bits of , and contains the upper 32 bits of . The diagram below illustrates this graphically.
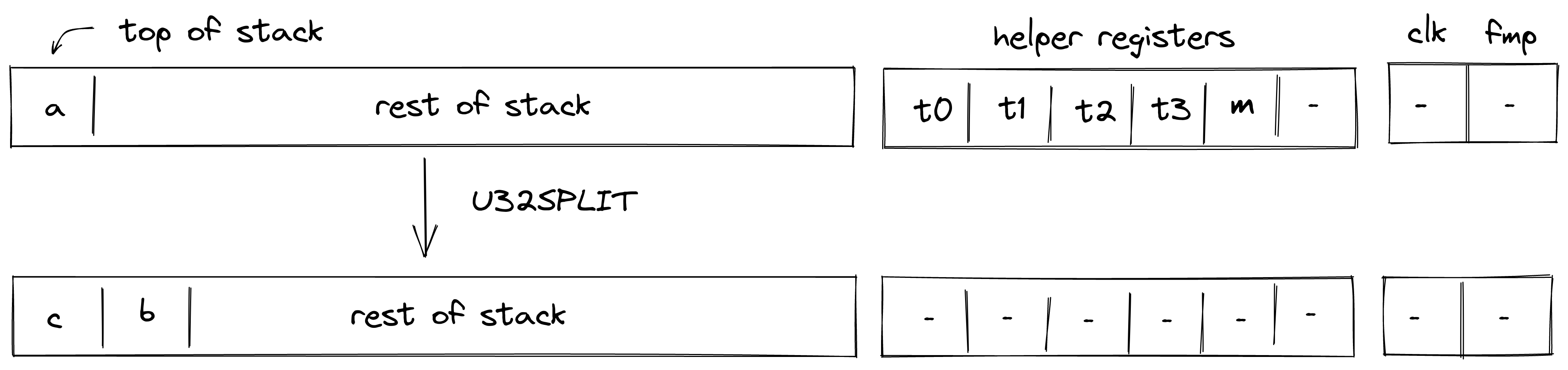
To facilitate this operation, the prover sets values in to 16-bit limbs of with being the least significant limb. Thus, stack transition for this operation must satisfy the following constraints:
In addition to the above constraints, we also need to verify that values in are smaller than , which we can do using 16-bit range checks as described previously. Also, we need to make sure that values in , when combined, form a valid field element, which we can do by putting a nondeterministic value into helper register and using the technique described here.
The effect of this operation on the rest of the stack is:
- Right shift starting from position .
U32ASSERT2
Assume and are the elements at the top of the stack. The U32ASSERT2 verifies that both and are smaller than . The diagram below illustrates this graphically.
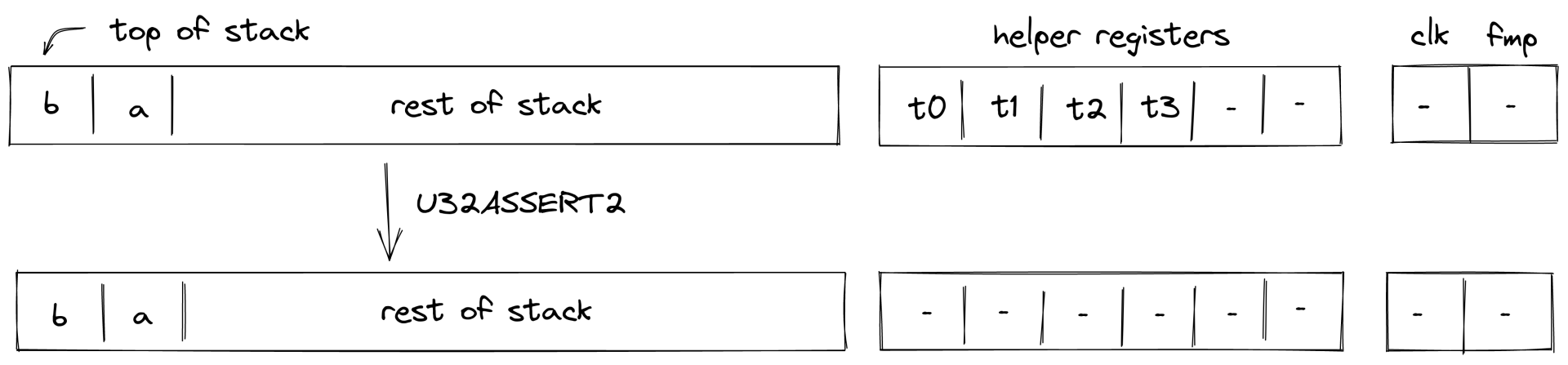
To facilitate this operation, the prover sets values in and to low and high 16-bit limbs of , and values in and to to low and high 16-bit limbs of . Thus, stack transition for this operation must satisfy the following constraints:
In addition to the above constraints, we also need to verify that values in are smaller than , which we can do using 16-bit range checks as described previously.
The effect of this operation on the rest of the stack is:
- No change starting from position - i.e., the state of the stack does not change.
U32ADD
Assume and are the values at the top of the stack which are known to be smaller than . The U32ADD operation computes , where contains the low 32-bits of the result, and is the carry bit. The diagram below illustrates this graphically.
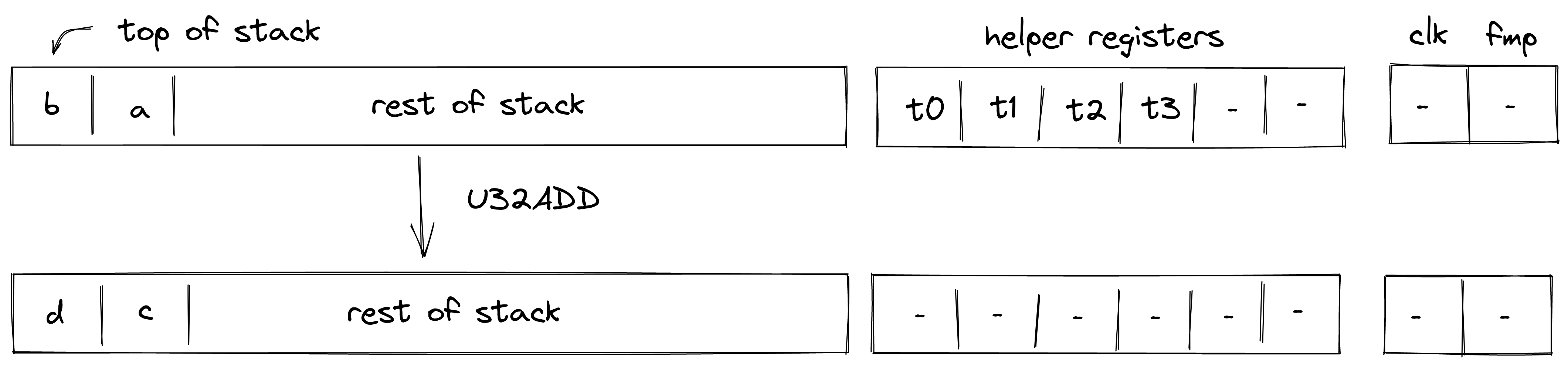
To facilitate this operation, the prover sets values in , , and to 16-bit limbs of with being the least significant limb. Value in is set to . Thus, stack transition for this operation must satisfy the following constraints:
In addition to the above constraints, we also need to verify that values in are smaller than , which we can do using 16-bit range checks as described previously.
The effect of this operation on the rest of the stack is:
- No change starting from position .
U32ADD3
Assume , , are the values at the top of the stack which are known to be smaller than . The U32ADD3 operation computes , where and contains the low and the high 32-bits of the result respectively. The diagram below illustrates this graphically.
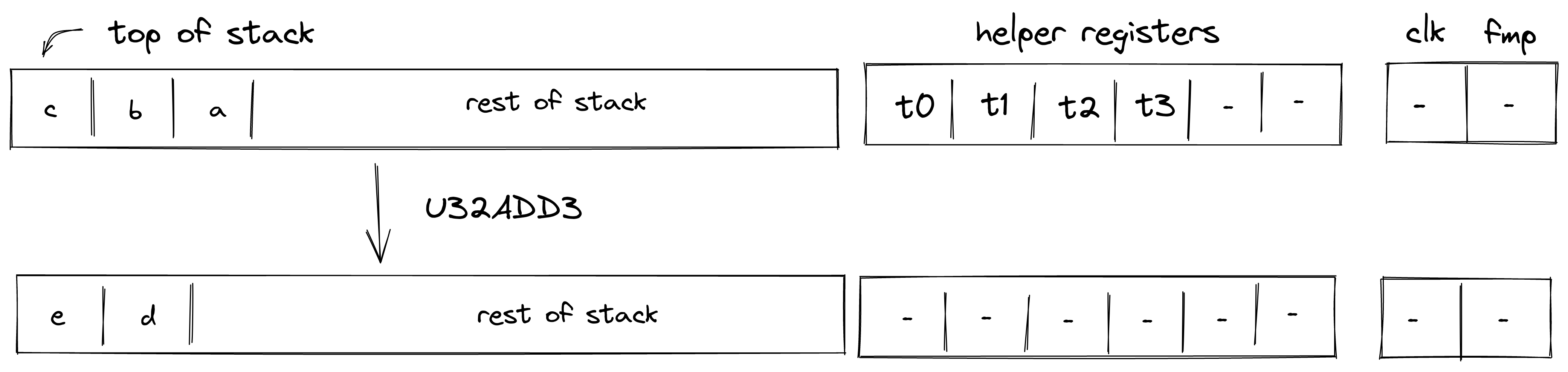
To facilitate this operation, the prover sets values in , , and to 16-bit limbs of with being the least significant limb. Value in is set to . Thus, stack transition for this operation must satisfy the following constraints:
In addition to the above constraints, we also need to verify that values in are smaller than , which we can do using 16-bit range checks as described previously.
The effect of this operation on the rest of the stack is:
- Left shift starting from position .
U32SUB
Assume and are the values at the top of the stack which are known to be smaller than . The U32SUB operation computes , where contains the 32-bit result in two's complement, and is the borrow bit. The diagram below illustrates this graphically.
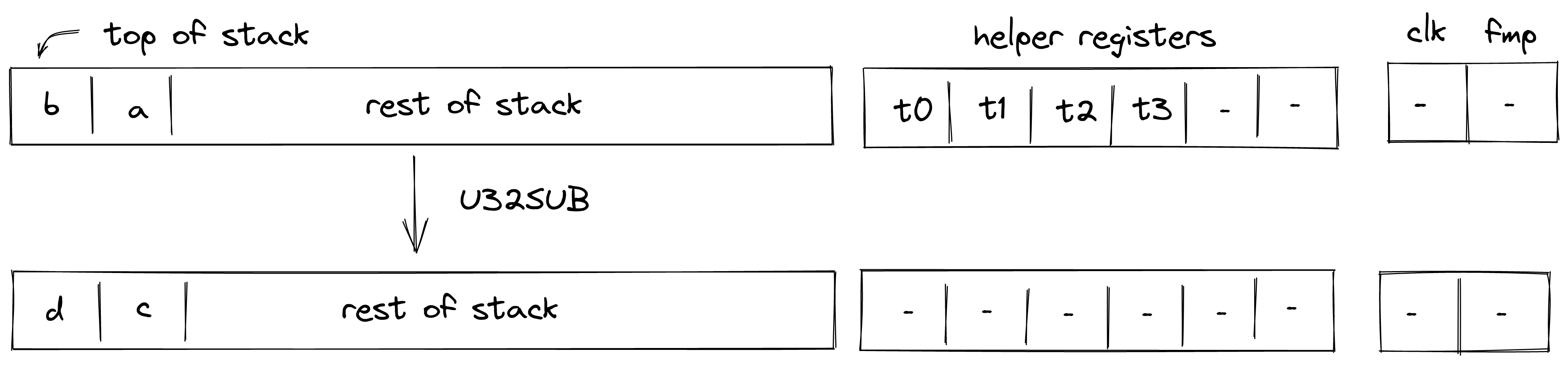
To facilitate this operation, the prover sets values in and to the low and the high 16-bit limbs of respectively. Values in and are set to . Thus, stack transition for this operation must satisfy the following constraints:
In addition to the above constraints, we also need to verify that values in are smaller than , which we can do using 16-bit range checks as described previously.
The effect of this operation on the rest of the stack is:
- No change starting from position .
U32MUL
Assume and are the values at the top of the stack which are known to be smaller than . The U32MUL operation computes , where and contain the low and the high 32-bits of the result respectively. The diagram below illustrates this graphically.
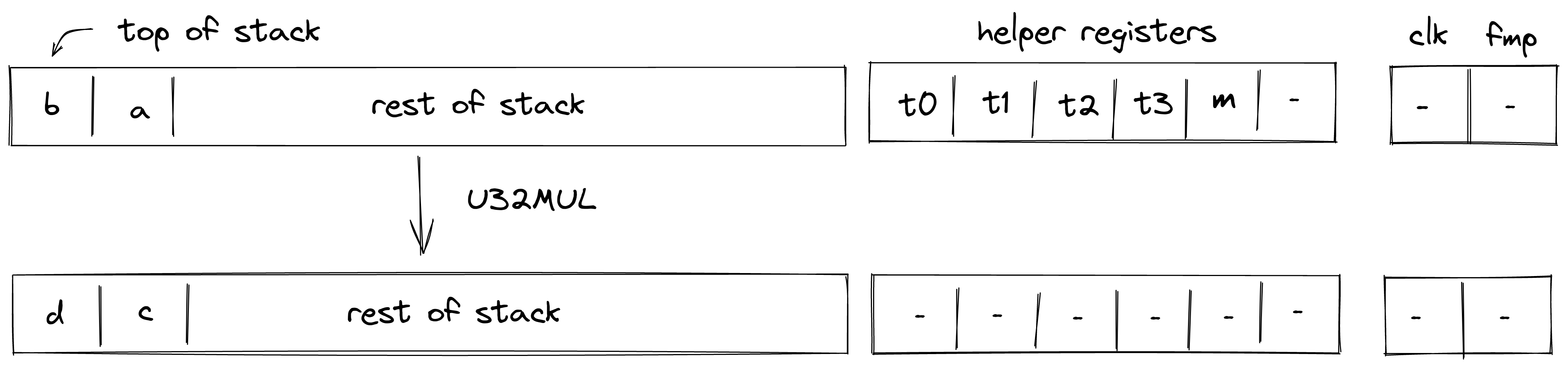
To facilitate this operation, the prover sets values in to 16-bit limbs of with being the least significant limb. Thus, stack transition for this operation must satisfy the following constraints:
In addition to the above constraints, we also need to verify that values in are smaller than , which we can do using 16-bit range checks as described previously. Also, we need to make sure that values in , when combined, form a valid field element, which we can do by putting a nondeterministic value into helper register and using the technique described here.
The effect of this operation on the rest of the stack is:
- No change starting from position .
U32MADD
Assume , , are the values at the top of the stack which are known to be smaller than . The U32MADD operation computes , where and contains the low and the high 32-bits of . The diagram below illustrates this graphically.
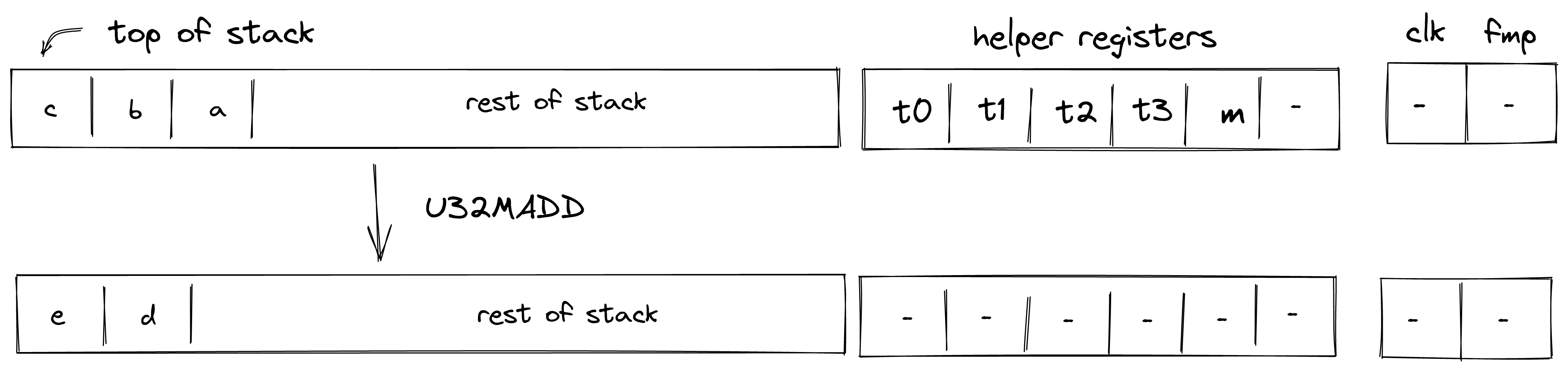
To facilitate this operation, the prover sets values in to 16-bit limbs of with being the least significant limb. Thus, stack transition for this operation must satisfy the following constraints:
In addition to the above constraints, we also need to verify that values in are smaller than , which we can do using 16-bit range checks as described previously. Also, we need to make sure that values in , when combined, form a valid field element, which we can do by putting a nondeterministic value into helper register and using the technique described here.
Note: that the above constraints guarantee the correctness of the operation iff cannot overflow field modules (which is the case for the field with modulus ).
The effect of this operation on the rest of the stack is:
- Left shift starting from position .
U32DIV
Assume and are the values at the top of the stack which are known to be smaller than . The U32DIV operation computes , where contains the quotient and contains the remainder. The diagram below illustrates this graphically.
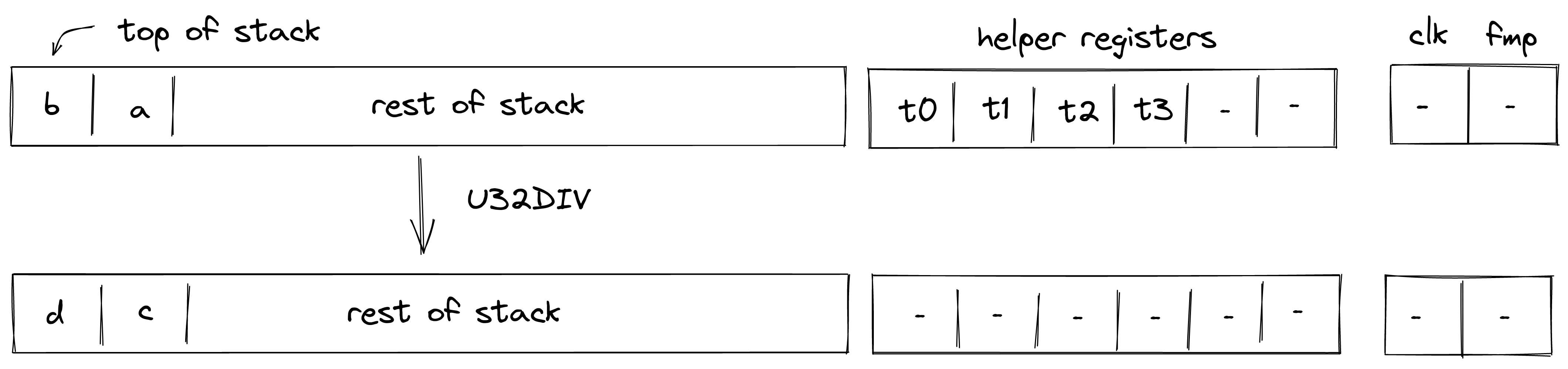
To facilitate this operation, the prover sets values in and to 16-bit limbs of , and values in and to 16-bit limbs of . Thus, stack transition for this operation must satisfy the following constraints:
The second constraint enforces that , while the third constraint enforces that .
The effect of this operation on the rest of the stack is:
- No change starting from position .
U32AND
Assume and are the values at the top of the stack. The U32AND operation computes , where is the result of performing a bitwise AND on and . The diagram below illustrates this graphically.
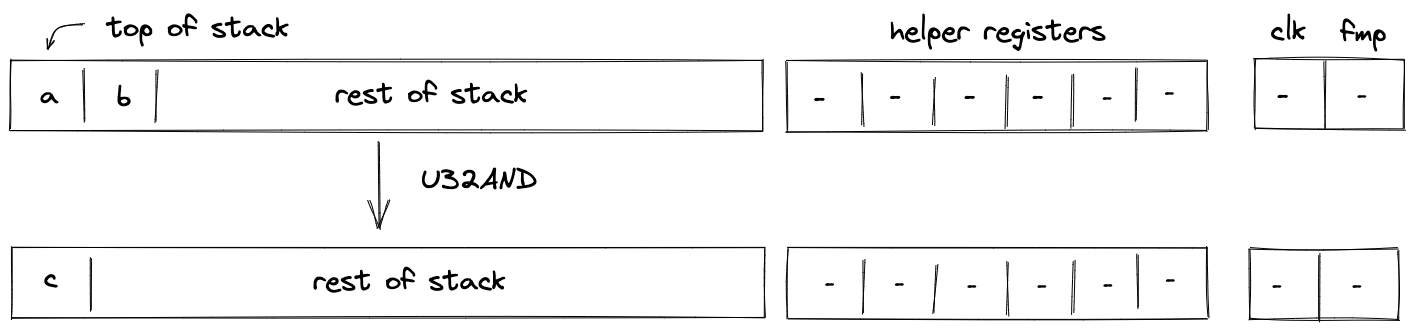
To facilitate this operation, we will need to make a request to the chiplet bus by dividing its current value by the value representing bitwise operation request. This can be enforced with the following constraint:
In the above, is the unique operation label of the bitwise AND operation.
Note: unlike for many other u32 operations, bitwise AND operation does not assume that the values at the top of the stack are smaller than . This is because the lookup will fail for any inputs which are not 32-bit integers.
The effect of this operation on the rest of the stack is:
- Left shift starting from position .
U32XOR
Assume and are the values at the top of the stack. The U32XOR operation computes , where is the result of performing a bitwise XOR on and . The diagram below illustrates this graphically.
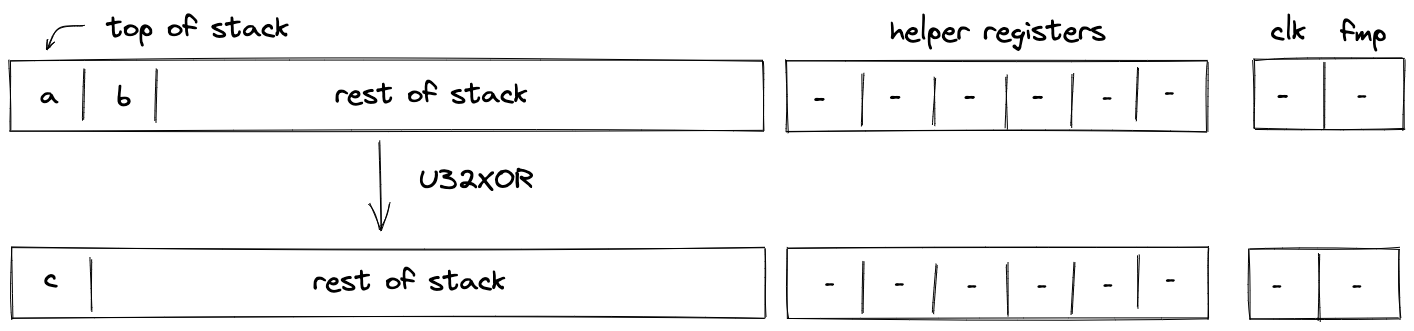
To facilitate this operation, we will need to make a request to the chiplet bus by dividing its current value by the value representing bitwise operation request. This can be enforced with the following constraint:
In the above, is the unique operation label of the bitwise XOR operation.
Note: unlike for many other u32 operations, bitwise XOR operation does not assume that the values at the top of the stack are smaller than . This is because the lookup will fail for any inputs which are not 32-bit integers.
The effect of this operation on the rest of the stack is:
- Left shift starting from position .
Stack Manipulation
In this section we describe the AIR constraints for Miden VM stack manipulation operations.
PAD
The PAD operation pushes a onto the stack. The diagram below illustrates this graphically.
Stack transition for this operation must satisfy the following constraints:
The effect of this operation on the rest of the stack is:
- Right shift starting from position .
DROP
The DROP operation removes an element from the top of the stack. The diagram below illustrates this graphically.
The DROP operation shifts the stack by element to the left, but does not impose any additional constraints. The degree of left shift constraints is .
The effect of this operation on the rest of the stack is:
- Left shift starting from position .
DUP(n)
The DUP(n) operations push a copy of the -th stack element onto the stack. Eg. DUP (same as DUP0) pushes a copy of the top stack element onto the stack. Similarly, DUP5 pushes a copy of the -th stack element onto the stack. This operation is valid for . The diagram below illustrates this graphically.
.png)
Stack transition for this operation must satisfy the following constraints:
where is the depth of the stack from where the element has been copied.
The effect of this operation on the rest of the stack is:
- Right shift starting from position .
SWAP
The SWAP operations swaps the top two elements of the stack. The diagram below illustrates this graphically.
Stack transition for this operation must satisfy the following constraints:
The effect of this operation on the rest of the stack is:
- No change starting from position .
SWAPW
The SWAPW operation swaps stack elements with elements . The diagram below illustrates this graphically.
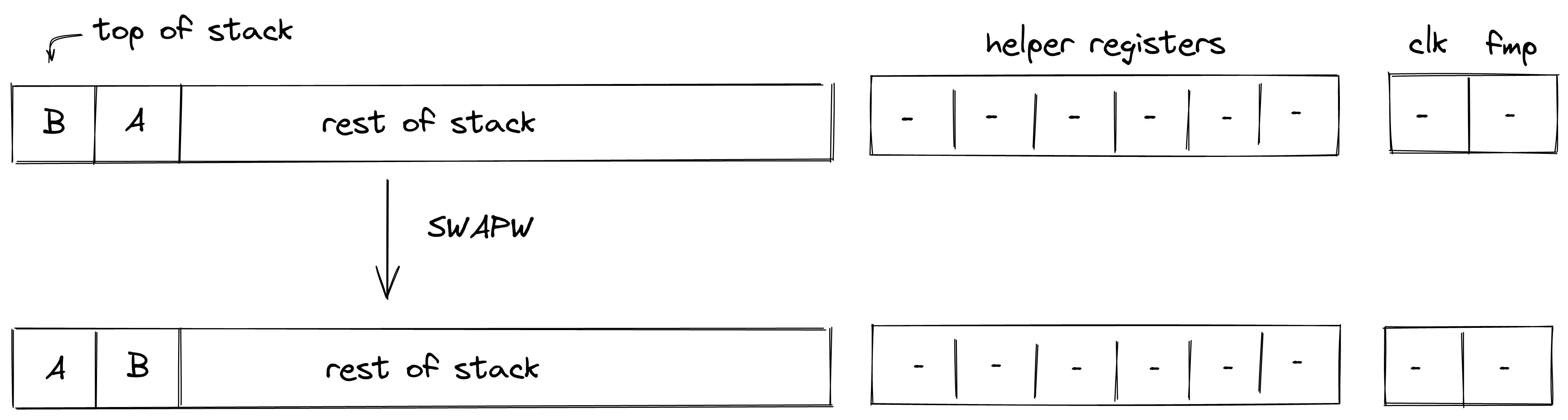
Stack transition for this operation must satisfy the following constraints:
The effect of this operation on the rest of the stack is:
- No change starting from position .
SWAPW2
The SWAPW2 operation swaps stack elements with elements . The diagram below illustrates this graphically.
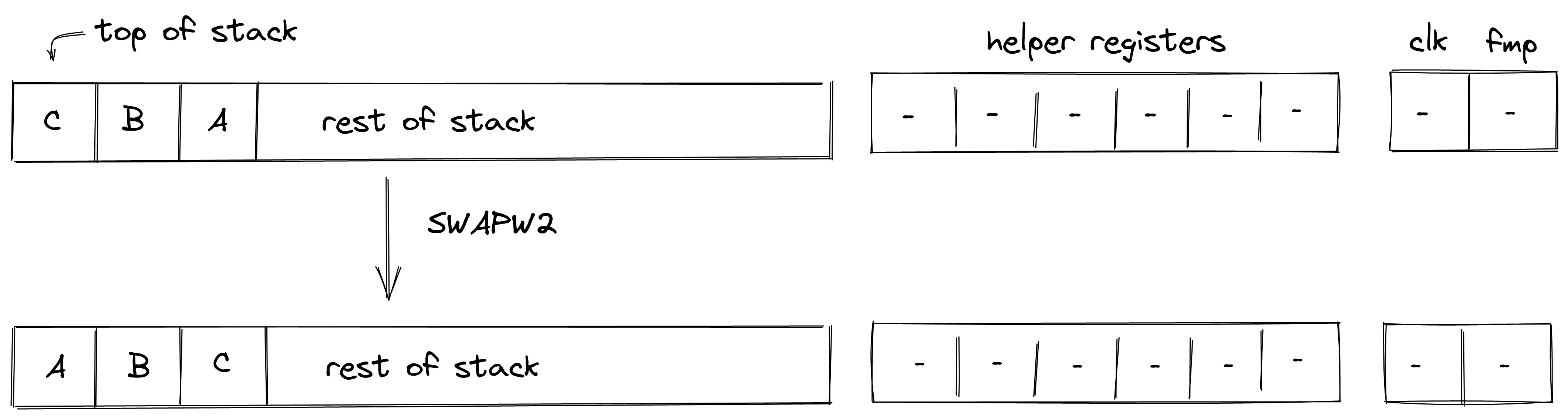
Stack transition for this operation must satisfy the following constraints:
The effect of this operation on the rest of the stack is:
- No change for elements .
- No change starting from position .
SWAPW3
The SWAPW3 operation swaps stack elements with elements . The diagram below illustrates this graphically.
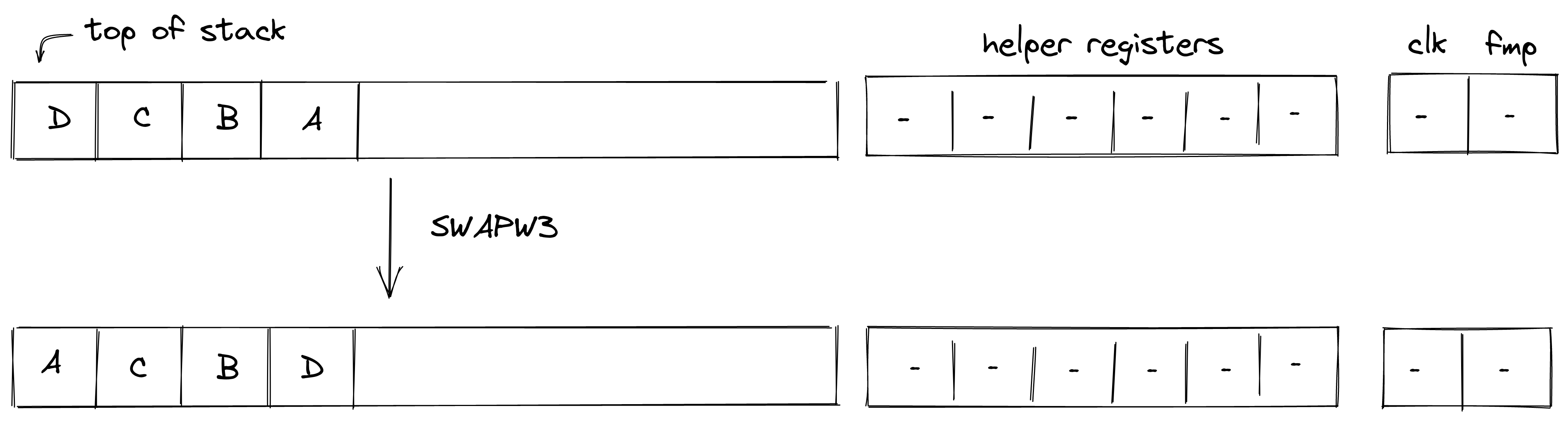
Stack transition for this operation must satisfy the following constraints:
The effect of this operation on the rest of the stack is:
- No change for elements .
- No change starting from position .
SWAPDW
The SWAPDW operation swaps stack elements with elements . The diagram below illustrates this graphically.
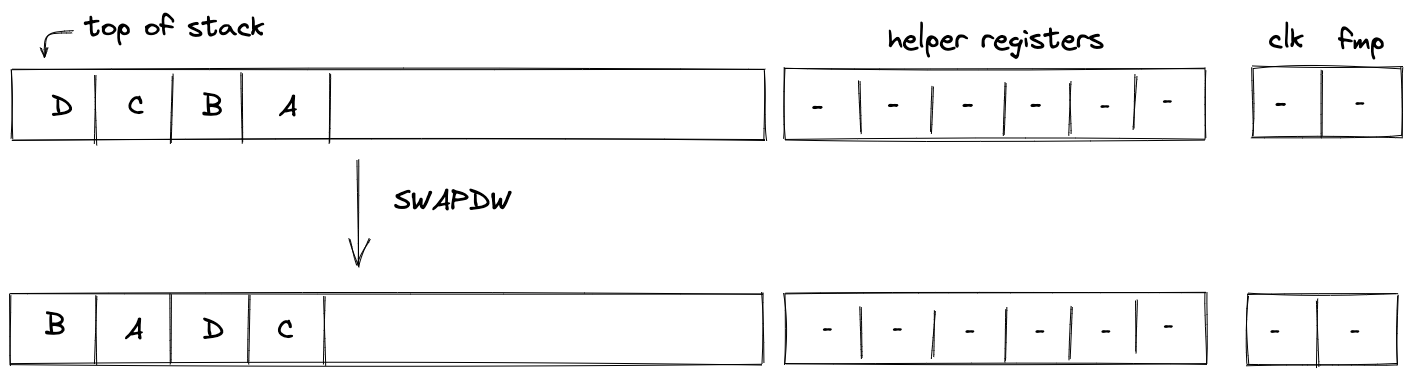
Stack transition for this operation must satisfy the following constraints:
The effect of this operation on the rest of the stack is:
- No change starting from position .
MOVUP(n)
The MOVUP(n) operation moves the -th element of the stack to the top of the stack. For example, MOVUP2 moves element at depth to the top of the stack. All elements with depth less than are shifted to the right by one, while elements with depth greater than remain in place, and the depth of the stack does not change. This operation is valid for . The diagram below illustrates this graphically.
.png)
Stack transition for this operation must satisfy the following constraints:
where is the depth of the element which is moved moved to the top of the stack.
The effect of this operation on the rest of the stack is:
- Right shift for elements between and .
- No change starting from position .
MOVDN(n)
The MOVDN(n) operation moves the top element of the stack to the -th position. For example, MOVDN2 moves the top element of the stack to depth . All the elements with depth less than are shifted to the left by one, while elements with depth greater than remain in place, and the depth of the stack does not change. This operation is valid for . The diagram below illustrates this graphically.
.png)
Stack transition for this operation must satisfy the following constraints:
where is the depth to which the top stack element is moved.
The effect of this operation on the rest of the stack is:
- Left shift for elements between and .
- No change starting from position .
CSWAP
The CSWAP operation pops an element off the stack and if the element is , swaps the top two remaining elements. If the popped element is , the rest of the stack remains unchanged. The diagram below illustrates this graphically.
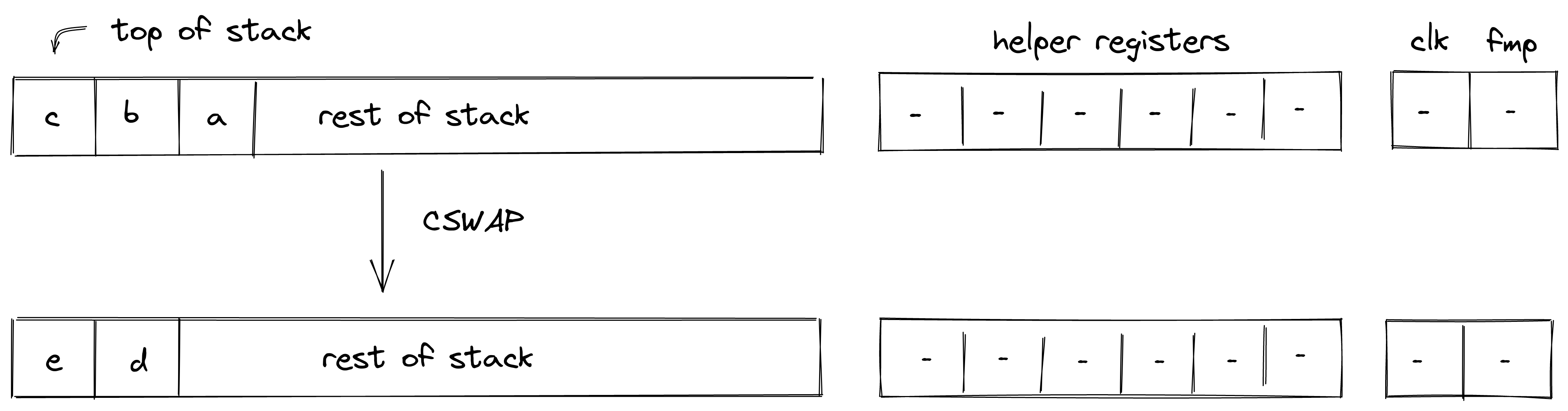
In the above:
Stack transition for this operation must satisfy the following constraints:
We also need to enforce that the value in is binary. This can be done with the following constraint:
The effect of this operation on the rest of the stack is:
- Left shift starting from position .
CSWAPW
The CSWAPW operation pops an element off the stack and if the element is , swaps elements with elements . If the popped element is , the rest of the stack remains unchanged. The diagram below illustrates this graphically.
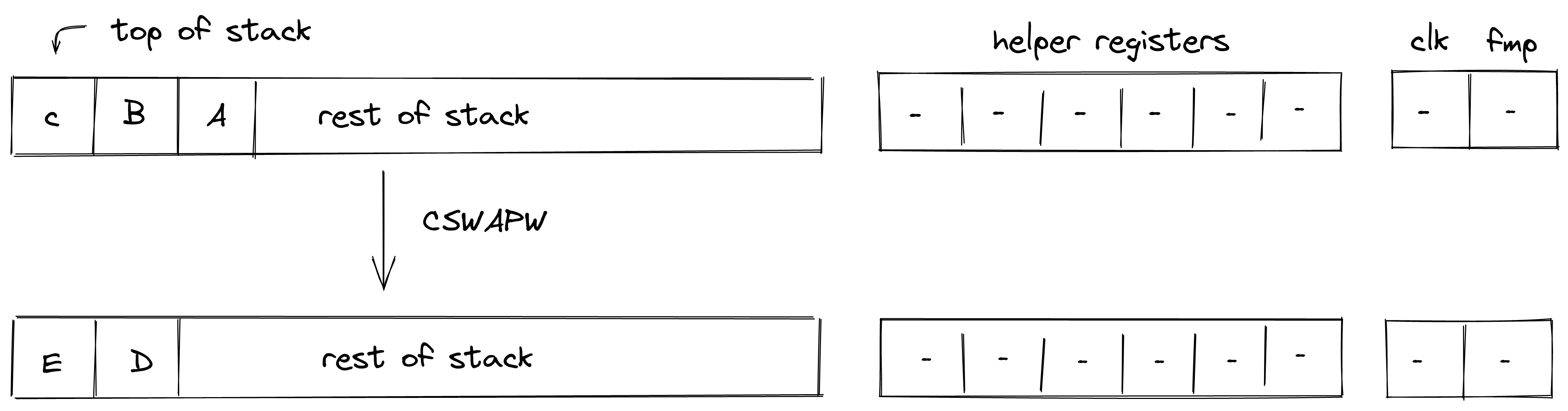
In the above:
Stack transition for this operation must satisfy the following constraints:
We also need to enforce that the value in is binary. This can be done with the following constraint:
The effect of this operation on the rest of the stack is:
- Left shift starting from position .
Input / output operations
In this section we describe the AIR constraints for Miden VM input / output operations. These operations move values between the stack and other components of the VM such as program code (i.e., decoder), memory, and advice provider.
PUSH
The PUSH operation pushes the provided immediate value onto the stack non-deterministically (i.e., sets the value of register); it is the responsibility of the Op Group Table to ensure that the correct value was pushed on the stack. The semantics of this operation are explained in the decoder section.
The effect of this operation on the rest of the stack is:
- Right shift starting from position .
SDEPTH
Assume is the current depth of the stack stored in the stack bookkeeping register (as described here). The SDEPTH pushes onto the stack. The diagram below illustrates this graphically.
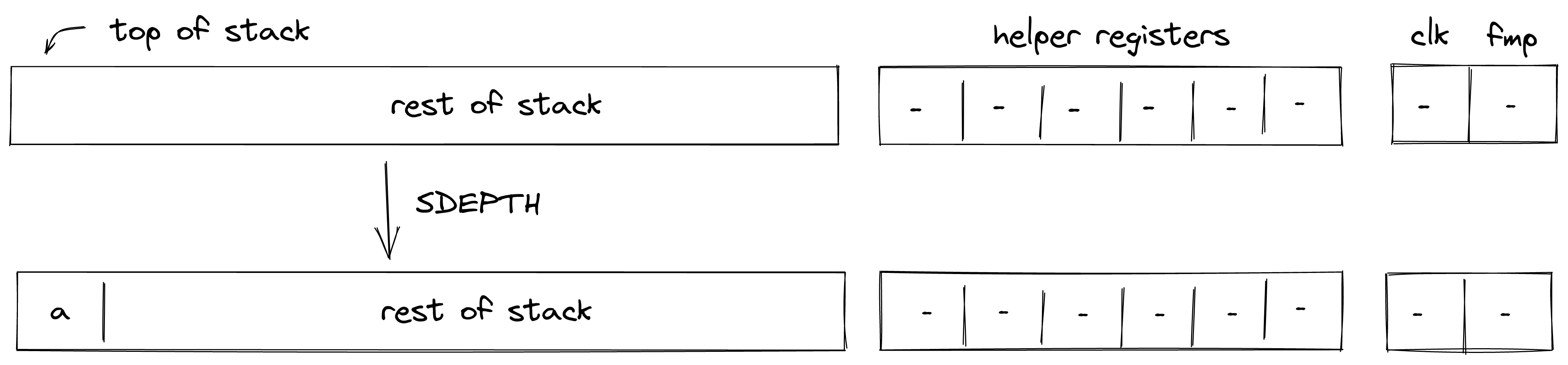
Stack transition for this operation must satisfy the following constraints:
The effect of this operation on the rest of the stack is:
- Right shift starting from position .
ADVPOP
Assume is an element at the top of the advice stack. The ADVPOP operation removes from the advice stack and pushes it onto the operand stack. The diagram below illustrates this graphically.
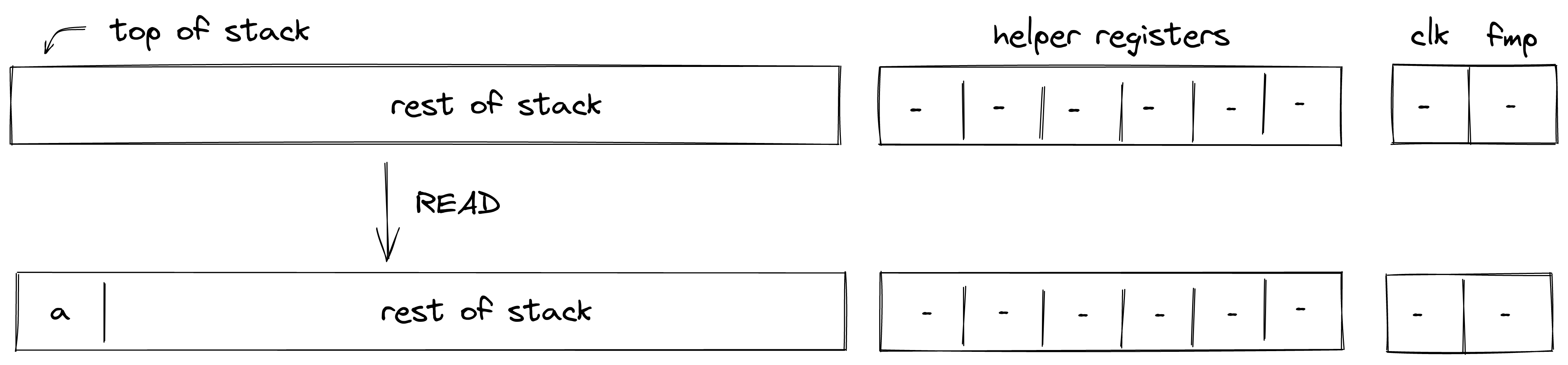
The ADVPOP operation does not impose any constraints against the first element of the operand stack.
The effect of this operation on the rest of the operand stack is:
- Right shift starting from position .
ADVPOPW
Assume , , , and , are the elements at the top of the advice stack (with being on top). The ADVPOPW operation removes these elements from the advice stack and puts them onto the operand stack by overwriting the top stack elements. The diagram below illustrates this graphically.
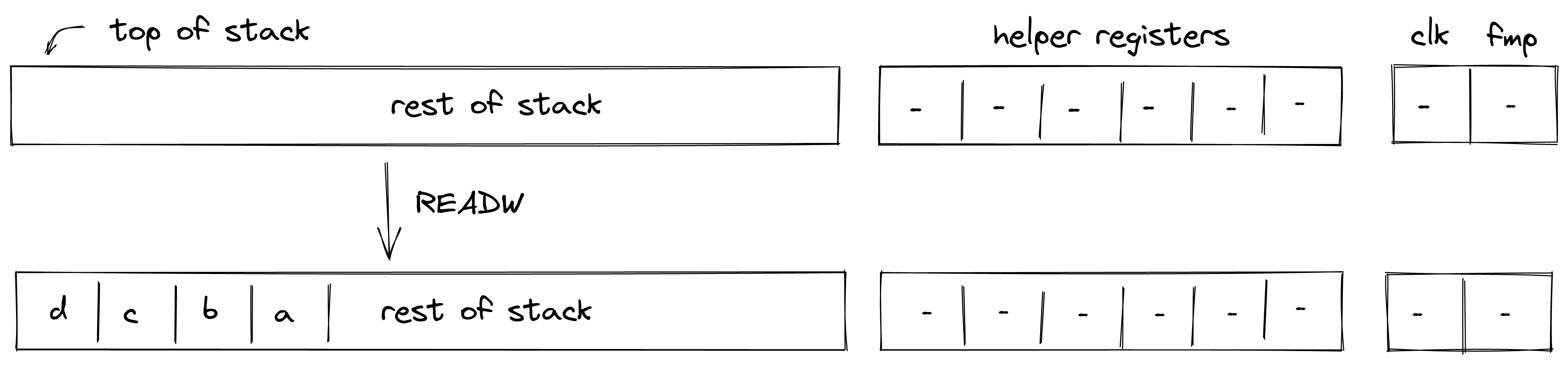
The ADVPOPW operation does not impose any constraints against the top elements of the operand stack.
The effect of this operation on the rest of the operand stack is:
- No change starting from position .
Memory access operations
Miden VM exposes several operations for reading from and writing to random access memory. Memory in Miden VM is managed by the Memory chiplet.
Communication between the stack and the memory chiplet is accomplished via the chiplet bus . To make requests to the chiplet bus we need to divide its current value by the value representing memory access request. The structure of memory access request value is described here.
To enforce the correctness of memory access, we can use the following constraint:
In the above, is the value of memory access request. Thus, to describe AIR constraint for memory operations, it is sufficient to describe how is computed. We do this in the following sections.
MLOADW
Assume that the word with elements is located in memory starting at address . The MLOADW operation pops an element off the stack, interprets it as a memory address, and replaces the remaining 4 elements at the top of the stack with values located at the specified address. The diagram below illustrates this graphically.
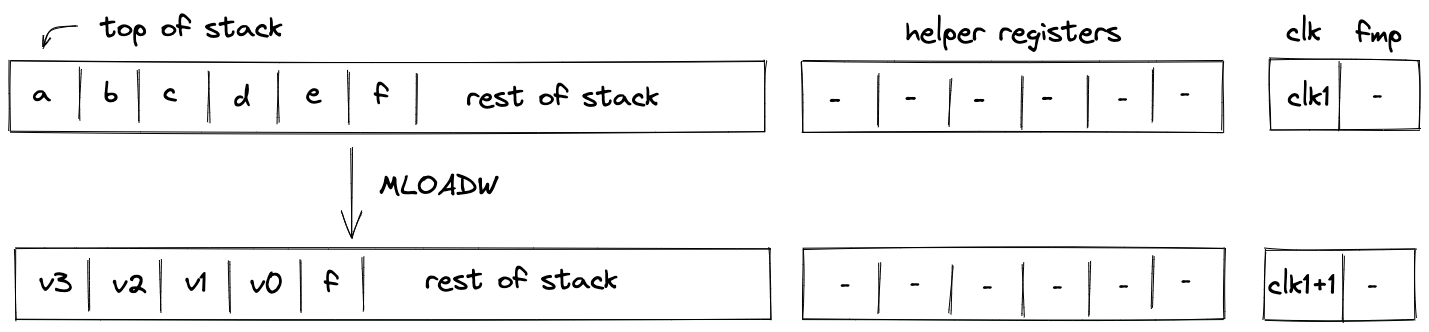
To simplify description of the memory access request value, we first define a variable for the value that represents the state of memory after the operation:
Using the above variable, we define the value representing the memory access request as follows:
In the above:
- is the unique operation label of the memory "read word" operation.
- is the identifier of the current memory context.
- is the memory address from which the values are to be loaded onto the stack.
- is the current clock cycle of the VM.
The effect of this operation on the rest of the stack is:
- Left shift starting from position .
MLOAD
Assume that the element is located in memory at address . The MLOAD operation pops an element off the stack, interprets it as a memory address, and pushes the element located at the specified address to the stack. The diagram below illustrates this graphically.
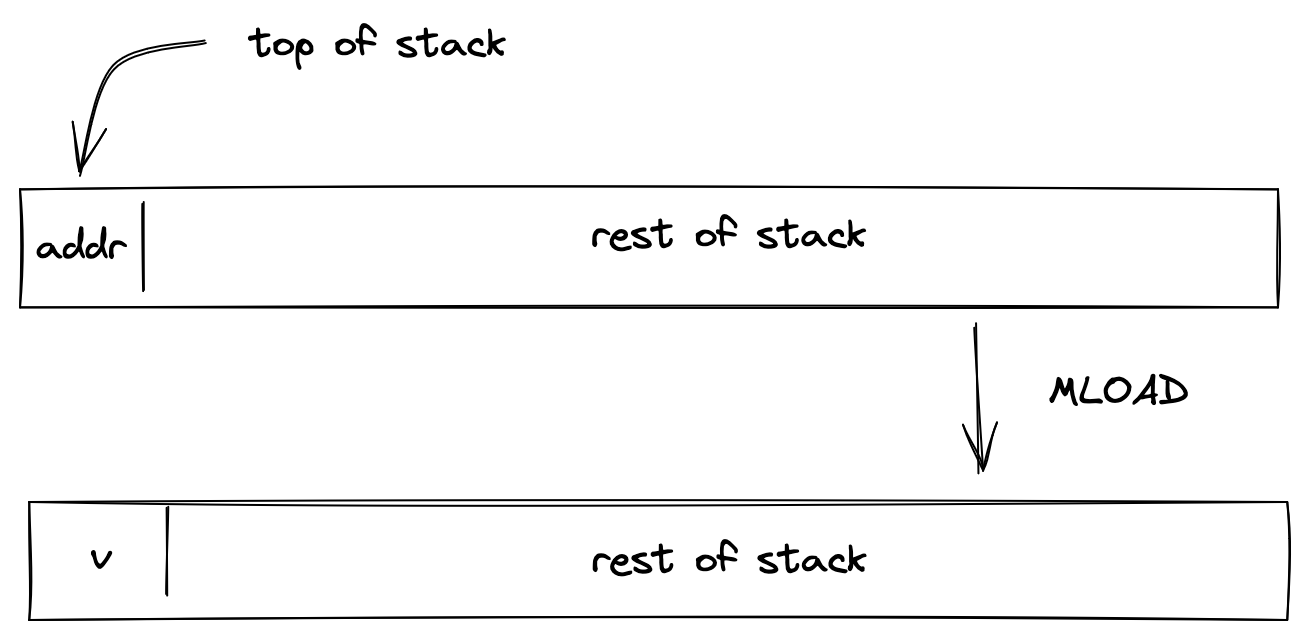
We define the value representing the memory access request as follows:
In the above:
- is the unique operation label of the memory "read element" operation.
- is the identifier of the current memory context.
- is the memory address from which the value is to be loaded onto the stack.
- is the current clock cycle of the VM.
The effect of this operation on the rest of the stack is:
- No change starting from position .
MSTOREW
The MSTOREW operation pops an element off the stack, interprets it as a memory address, and writes the remaining elements at the top of the stack into memory starting at the specified address. The stored elements are not removed from the stack. The diagram below illustrates this graphically.
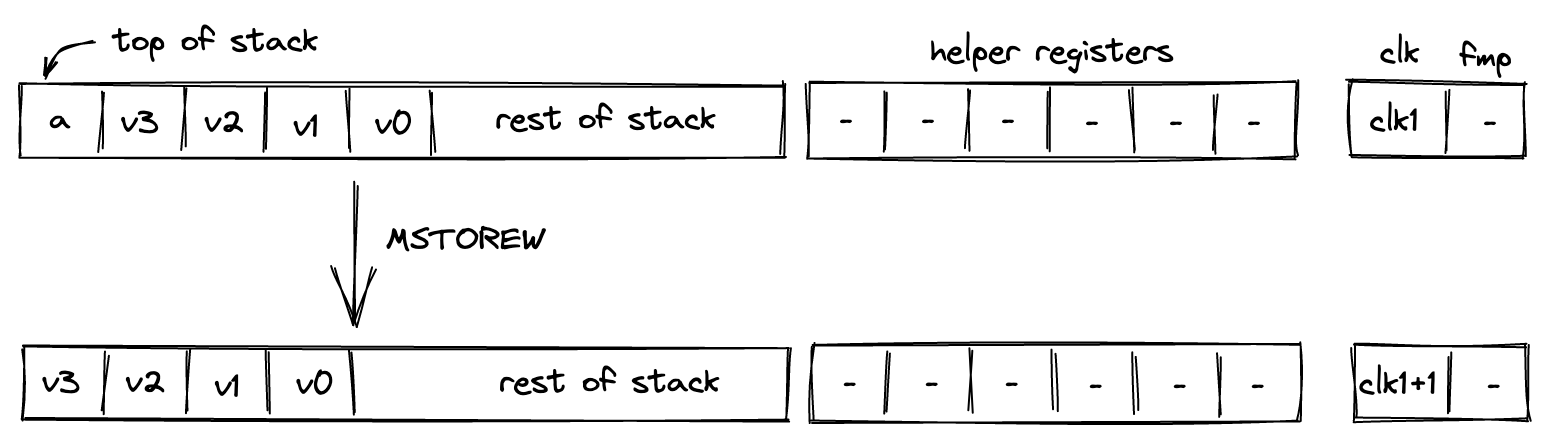
After the operation the contents of memory at addresses , , , would be set to , respectively.
To simplify description of the memory access request value, we first define a variable for the value that represents the state of memory after the operation:
Using the above variable, we define the value representing the memory access request as follows:
In the above:
- is the unique operation label of the memory "write word" operation.
- is the identifier of the current memory context.
- is the memory address into which the values from the stack are to be saved.
- is the current clock cycle of the VM.
The effect of this operation on the rest of the stack is:
- Left shift starting from position .
MSTORE
The MSTORE operation pops an element off the stack, interprets it as a memory address, and writes the remaining element at the top of the stack into memory at the specified memory address. The diagram below illustrates this graphically.
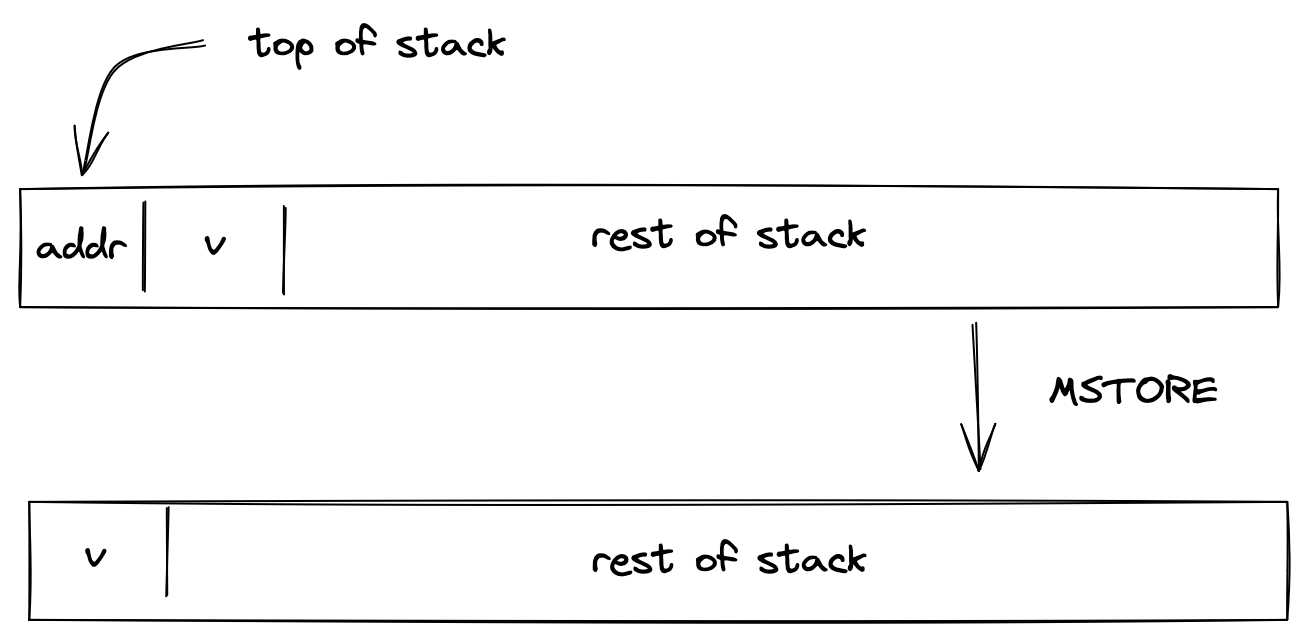
After the operation the contents of memory at address would be set to .
We define the value representing the memory access request as follows:
In the above:
- is the unique operation label of the memory "write element" operation.
- is the identifier of the current memory context.
- is the memory address into which the value from the stack is to be saved.
- is the current clock cycle of the VM.
The effect of this operation on the rest of the stack is:
- Left shift starting from position .
MSTREAM
The MSTREAM operation loads two words from memory, and replaces the top 8 elements of the stack with them, element-wise, in stack order. The start memory address from which the words are loaded is stored in the 13th stack element (position 12). The diagram below illustrates this graphically.
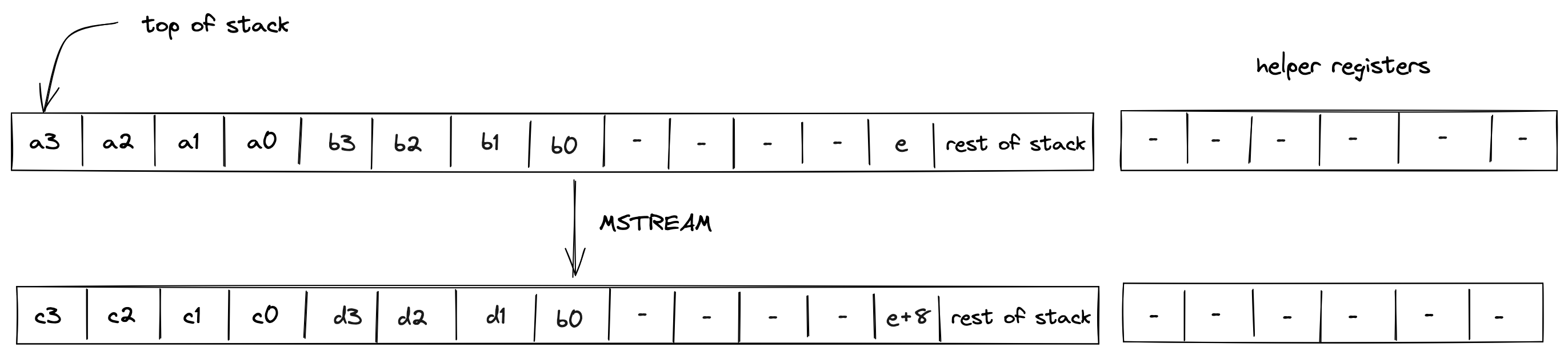
After the operation, the memory address is incremented by 8.
To simplify description of the memory access request value, we first define variables for the values that represent the state of memory after the operation:
Using the above variables, we define the values representing the memory access request as follows:
In the above:
- is the unique operation label of the memory "read word" operation.
- is the identifier of the current memory context.
- and are the memory addresses from which the words are to be loaded onto the stack.
- is the current clock cycle of the VM.
The effect of this operation on the rest of the stack is:
- No change starting from position except position .
Cryptographic operations
In this section we describe the AIR constraints for Miden VM cryptographic operations.
Cryptographic operations in Miden VM are performed by the Hash chiplet. Communication between the stack and the hash chiplet is accomplished via the chiplet bus . To make requests to and to read results from the chiplet bus we need to divide its current value by the value representing the request.
Thus, to describe AIR constraints for the cryptographic operations, we need to define how to compute these input and output values within the stack. We do this in the following sections.
HPERM
The HPERM operation applies Rescue Prime Optimized permutation to the top elements of the stack. The stack is assumed to be arranged so that the elements of the rate are at the top of the stack. The capacity word follows, with the number of elements to be hashed at the deepest position in stack. The diagram below illustrates this graphically.

In the above, (located in the helper register ) is the row address from the hash chiplet set by the prover non-deterministically.
For the HPERM operation, we define input and output values as follows:
In the above, and are the unique operation labels for initiating a linear hash and reading the full state of the hasher respectively. Also note that the term for is missing from the above expressions because for Rescue Prime Optimized permutation computation the index column is expected to be set to .
Using the above values, we can describe the constraint for the chiplet bus column as follows:
The above constraint enforces that the specified input and output rows must be present in the trace of the hash chiplet, and that they must be exactly rows apart.
The effect of this operation on the rest of the stack is:
- No change starting from position .
MPVERIFY
The MPVERIFY operation verifies that a Merkle path from the specified node resolves to the specified root. This operation can be used to prove that the prover knows a path in the specified Merkle tree which starts with the specified node.
Prior to the operation, the stack is expected to be arranged as follows (from the top):
- Value of the node, 4 elements ( in the below image)
- Depth of the path, 1 element ( in the below image)
- Index of the node, 1 element ( in the below image)
- Root of the tree, 4 elements ( in the below image)
The Merkle path itself is expected to be provided by the prover non-deterministically (via the advice provider). If the prover is not able to provide the required path, the operation fails. Otherwise, the state of the stack does not change. The diagram below illustrates this graphically.
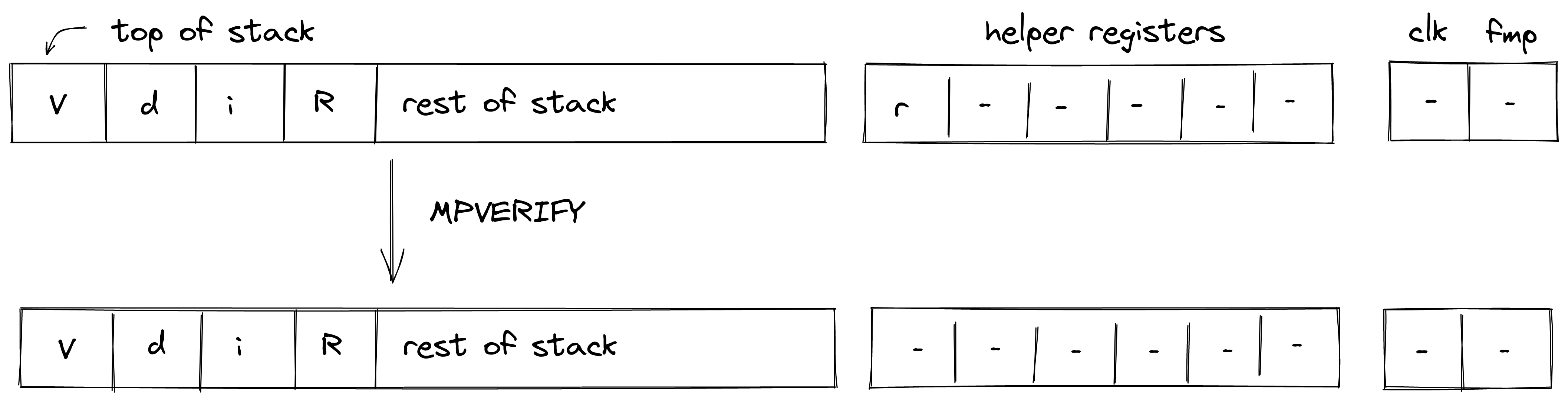
In the above, (located in the helper register ) is the row address from the hash chiplet set by the prover non-deterministically.
For the MPVERIFY operation, we define input and output values as follows:
In the above, and are the unique operation labels for initiating a Merkle path verification computation and reading the hash result respectively. The sum expression for inputs computes the value of the leaf node, while the sum expression for the output computes the value of the tree root.
Using the above values, we can describe the constraint for the chiplet bus column as follows:
The above constraint enforces that the specified input and output rows must be present in the trace of the hash chiplet, and that they must be exactly rows apart, where is the depth of the node.
The effect of this operation on the rest of the stack is:
- No change starting from position .
MRUPDATE
The MRUPDATE operation computes a new root of a Merkle tree where a node at the specified position is updated to the specified value.
The stack is expected to be arranged as follows (from the top):
- old value of the node, 4 element ( in the below image)
- depth of the node, 1 element ( in the below image)
- index of the node, 1 element ( in the below image)
- current root of the tree, 4 elements ( in the below image)
- new value of the node, 4 element ( in the below image)
The Merkle path for the node is expected to be provided by the prover non-deterministically (via merkle sets). At the end of the operation, the old node value is replaced with the new root value computed based on the provided path. Everything else on the stack remains the same. The diagram below illustrates this graphically.
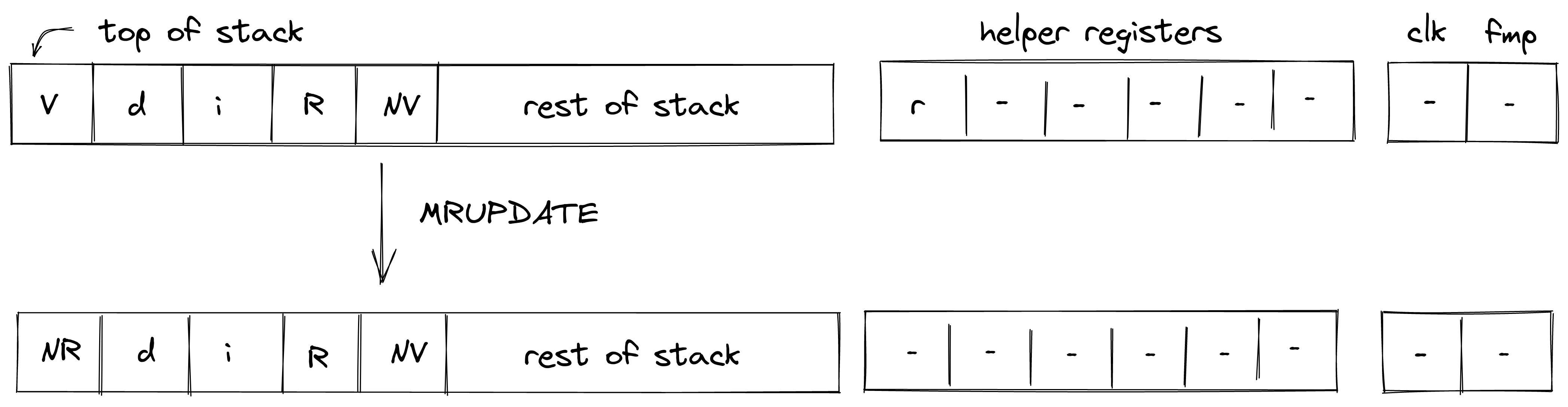
In the above, (located in the helper register ) is the row address from the hash chiplet set by the prover non-deterministically.
For the MRUPDATE operation, we define input and output values as follows:
In the above, the first two expressions correspond to inputs and outputs for verifying the Merkle path between the old node value and the old tree root, while the last two expressions correspond to inputs and outputs for verifying the Merkle path between the new node value and the new tree root. The hash chiplet ensures the same set of sibling nodes are used in both of these computations.
The , , and are the unique operation labels used by the above computations.
The above constraint enforces that the specified input and output rows for both, the old and the new node/root combinations, must be present in the trace of the hash chiplet, and that they must be exactly rows apart, where is the depth of the node. It also ensures that the computation for the old node/root combination is immediately followed by the computation for the new node/root combination.
The effect of this operation on the rest of the stack is:
- No change for positions starting from .
FRIE2F4
The FRIE2F4 operation performs FRI layer folding by a factor of 4 for FRI protocol executed in a degree 2 extension of the base field. It also performs several computations needed for checking correctness of the folding from the previous layer as well as simplifying folding of the next FRI layer.
The stack for the operation is expected to be arranged as follows:
- The first stack elements contain query points to be folded. Each point is represented by two field elements because points to be folded are in the extension field. We denote these points as , , , .
- The next element is the query position in the folded domain. It can be computed as , where is the position in the source domain, and is size of the folded domain.
- The next element is a value indicating domain segment from which the position in the original domain was folded. It can be computed as . Since the size of the source domain is always times bigger than the size of the folded domain, possible domain segment values can be , , , or .
- The next element is a power of initial domain generator which aids in a computation of the domain point .
- The next two elements contain the result of the previous layer folding - a single element in the extension field denoted as .
- The next two elements specify a random verifier challenge for the current layer defined as .
- The last element on the top of the stack () is expected to be a memory address of the layer currently being folded.
The diagram below illustrates stack transition for FRIE2F4 operation.
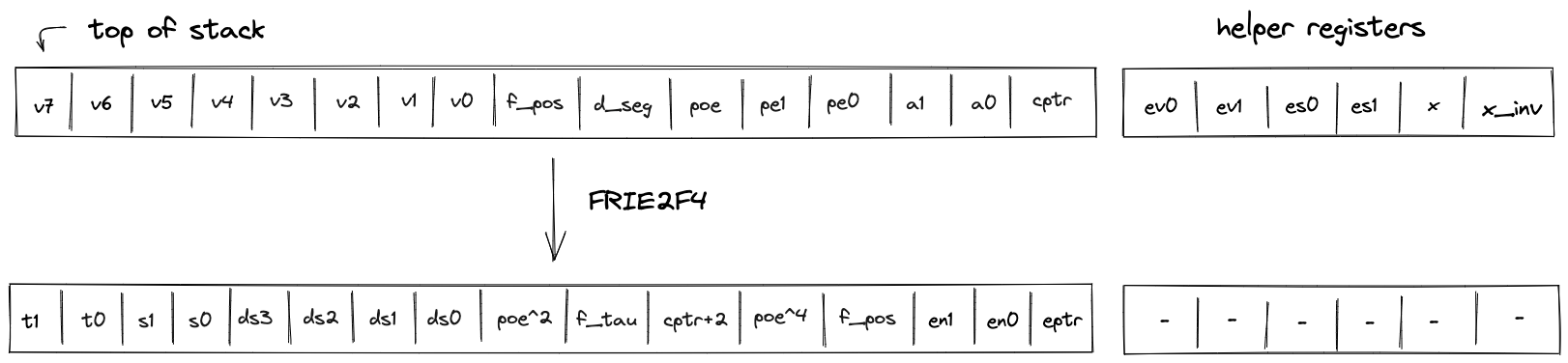
At the high-level, the operation does the following:
- Computes the domain value based on values of and .
- Using and , folds the query values into a single value .
- Compares the previously folded value to the appropriate value of to verify that the folding of the previous layer was done correctly.
- Computes the new value of as (this is done in two steps to keep the constraint degree low).
- Increments the layer address pointer by .
- Shifts the stack by to the left. This moves an element from the stack overflow table into the last position on the stack top.
To keep the degree of the constraints low, a number of intermediate values are used. Specifically, the operation relies on all helper registers, and also uses the first elements of the stack at the next state for degree reduction purposes. Thus, once the operation has been executed, the top elements of the stack can be considered to be "garbage".
TODO: add detailed constraint descriptions. See discussion here.
The effect on the rest of the stack is:
- Left shift starting from position .
HORNERBASE
The HORNERBASE operation performs steps of the Horner method for evaluating a polynomial with coefficients over the base field at a point in the quadratic extension field. More precisely, it performs the following update to the accumulator on the stack
where are the coefficients of the polynomial, the evaluation point, the current accumulator value and the updated accumulator value.
The stack for the operation is expected to be arranged as follows:
- The first stack elements contain base field elements representing the current 8-element batch of coefficients for the polynomial being evaluated.
- The next stack elements are irrelevant for the operation and unaffected by it.
- The next stack element contains the value of the memory pointer
alpha_ptrto the evaluation point . The word address containing is expected to have layout . - The next stack elements contain the value of the current accumulator .
The diagram below illustrates the stack transition for HORNERBASE operation.
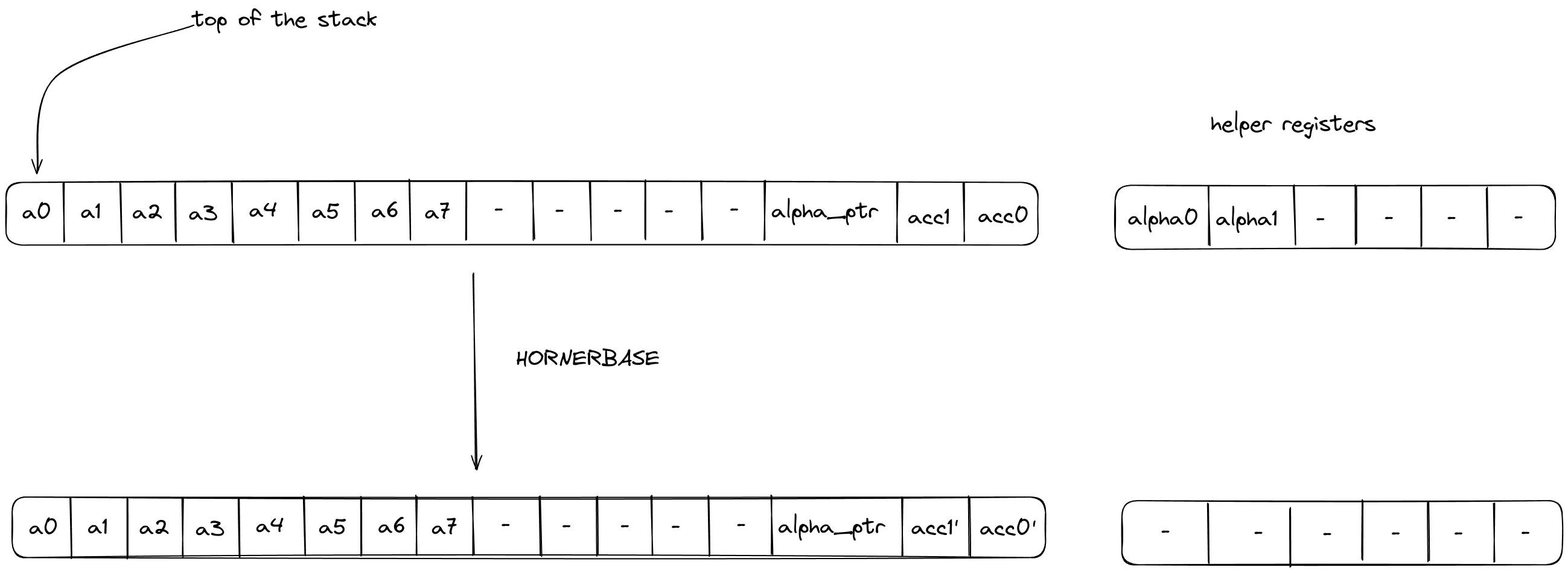
After calling the operation:
- Stack elements and will contain the value of the updated accumulator i.e., .
The effect on the rest of the stack is:
- No change.
The HORNERBASE makes one memory access request:
HORNEREXT
The HORNEREXT operation performs steps of the Horner method for evaluating a polynomial with coefficients over the quadratic extension field at a point in the quadratic extension field. More precisely, it performs the following update to the accumulator on the stack
where are the coefficients of the polynomial, the evaluation point, the current accumulator value and the updated accumulator value.
The stack for the operation is expected to be arranged as follows:
- The first stack elements contain base field elements representing the current 4-element batch of coefficients, in the quadratic extension field, for the polynomial being evaluated.
- The next stack elements are irrelevant for the operation and unaffected by it.
- The next stack element contains the value of the memory pointer
alpha_ptrto the evaluation point . The word address containing is expected to have layout . - The next stack elements contain the value of the current accumulator .
The diagram below illustrates the stack transition for HORNEREXT operation.
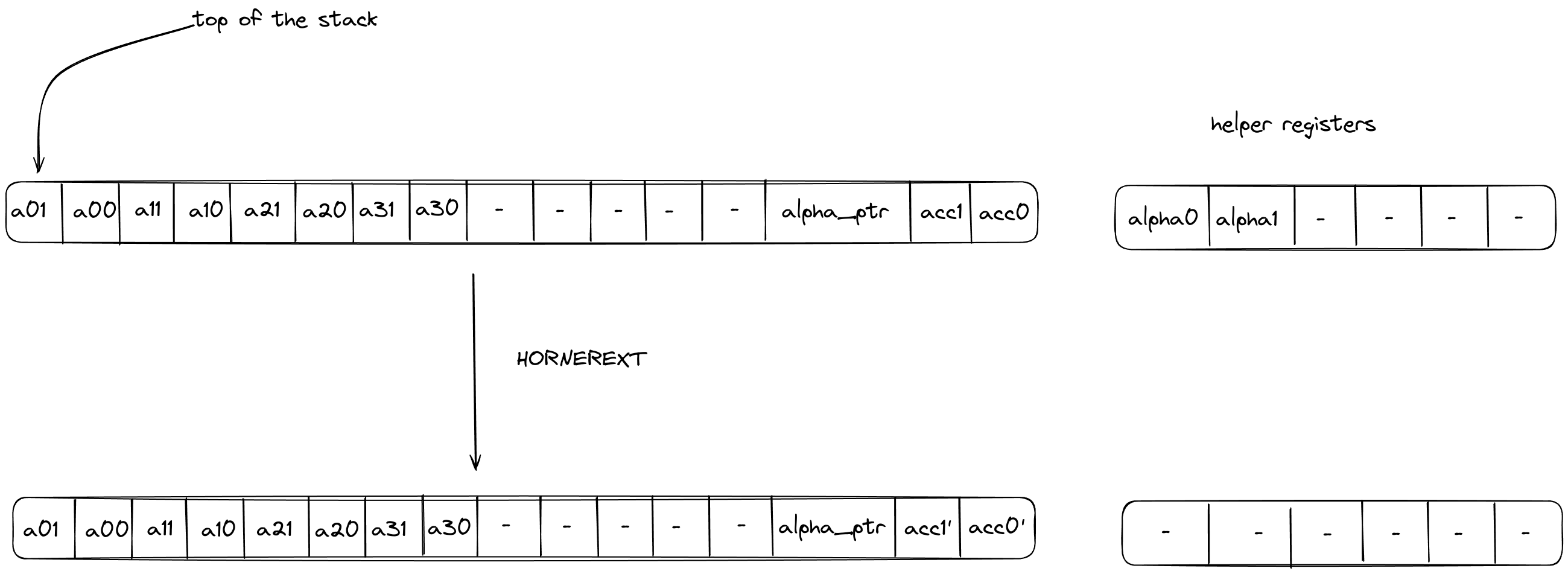
After calling the operation:
- Stack elements and will contain the value of the updated accumulator i.e., .
The effect on the rest of the stack is:
- No change.
The HORNEREXT makes one memory access request:
Range Checker
Miden VM relies very heavily on 16-bit range-checks (checking if a value of a field element is between and ). For example, most of the u32 operations need to perform between two and four 16-bit range-checks per operation. Similarly, operations involving memory (e.g. load and store) require two 16-bit range-checks per operation.
Thus, it is very important for the VM to be able to perform a large number of 16-bit range checks very efficiently. In this note we describe how this can be achieved using the LogUp lookup argument.
8-bit range checks
First, let's define a construction for the simplest possible 8-bit range-check. This can be done with a single column as illustrated below.

For this to work as a range-check we need to enforce a few constraints on this column:
- The value in the first row must be .
- The value in the last row must be .
- As we move from one row to the next, we can either keep the value the same or increment it by .
Denoting as the value of column in the current row, and as the value of column in the next row, we can enforce the last condition as follows:
Together, these constraints guarantee that all values in column are between and (inclusive).
We can then make use of the LogUp lookup argument by adding another column which will keep a running sum that is the logarithmic derivative of the product of values in the column. The transition constraint for would look as follows:
Since constraints cannot include divisions, the constraint would actually be expressed as the following degree 2 constraint:
Using these two columns we can check if some other column in the execution trace is a permutation of values in . Let's call this other column . We can compute the logarithmic derivative for as a running sum in the same way as we compute it for . Then, we can check that the last value in is the same as the final value for the running sum of .
While this approach works, it has a couple of limitations:
- First, column must contain all values between and . Thus, if column does not contain one of these values, we need to artificially add this value to somehow (i.e., we need to pad with extra values).
- Second, assuming is the length of execution trace, we can range-check at most values. Thus, if we wanted to range-check more than values, we'd need to introduce another column similar to .
We can get rid of both requirements by including the multiplicity of the value into the calculation of the logarithmic derivative for LogUp, which will allow us to specify exactly how many times each value needs to be range-checked.
A better construction
Let's add one more column to our table to keep track of how many times each value should be range-checked.
The transition constraint for is now as follows:
This addresses the limitations we had as follows:
- We no longer need to pad the column we want to range-check with extra values because we can skip the values we don't care about by setting the multiplicity to .
- We can range check as many unique values as there are rows in the trace, and there is essentially no limit to how many times each of these values can be range-checked. (The only restriction on the multiplicity value is that it must be less than the size of the set of lookup values. Therefore, for long traces where , must hold, and for short traces must be true.)
Additionally, the constraint degree has not increased versus the naive approach, and the only additional cost is a single trace column.
16-bit range checks
To support 16-bit range checks, let's try to extend the idea of the 8-bit table. Our 16-bit table would look like so (the only difference is that column now has to end with value ):
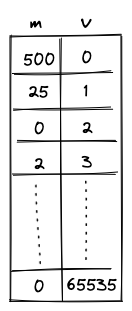
While this works, it is rather wasteful. In the worst case, we'd need to enumerate over 65K values, most of which we may not actually need. It would be nice if we could "skip over" the values that we don't want. One way to do this could be to add bridge rows between two values to be range checked and add constraints to enforce the consistency of the gap between these bridge rows.
If we allow gaps between two consecutive rows to only be 0 or powers of 2, we could enforce a constraint:
This constraint has a degree 9. This construction allows the minimum trace length to be 1024.
We could go even further and allow the gaps between two consecutive rows to only be 0 or powers of 3. In this case we would enforce the constraint:
This allows us to reduce the minimum trace length to 64.
To find out the number of bridge rows to be added in between two values to be range checked, we represent the gap between them as a linear combination of powers of 3, ie,
Then for each except the first, we add a bridge row at a gap of .
Miden approach
This construction is implemented in Miden with the following requirements, capabilities and constraints.
Requirements
- 2 columns of the main trace: , where contains the value being range-checked and is the number of times the value is checked (its multiplicity).
- 1 bus to ensure that the range checks performed in the range checker match those requested by other VM components (the stack and the memory chiplet).
Capabilities
The construction gives us the following capabilities:
- For long traces (when ), we can do an essentially unlimited number of arbitrary 16-bit range-checks.
- For short traces (), we can range-check slightly fewer than unique values, but there is essentially no practical limit to the total number of range checks.
Execution trace
The range checker's execution trace looks as follows:
The columns have the following meanings:
- is the multiplicity column that indicates the number of times the value in that row should be range checked (included into the computation of the logarithmic derivative).
- contains the values to be range checked.
- These values go from to . Values must either stay the same or increase by powers of 3 less than or equal to .
- The final 2 rows of the 16-bit section of the trace must both equal . The extra value of is required in order to pad the trace so the bus column can be computed correctly.
Execution trace constraints
First, we need to constrain that the consecutive values in the range checker are either the same or differ by powers of 3 that are less than or equal to .
In addition to the transition constraints described above, we also need to enforce the following boundary constraints:
- The value of in the first row is .
- The value of in the last row is .
Communication bus
is the bus that connects components which require 16-bit range checks to the values in the range checker. The bus constraints are defined by the components that use it to communicate.
Requests are sent to the range checker bus by the following components:
- The Stack sends requests for 16-bit range checks during some
u32operations. - The Memory chiplet sends requests for 16-bit range checks against the values in the and trace columns to enforce internal consistency.
Responses are provided by the range checker using the transition constraint for the LogUp construction described above.
To describe the complete transition constraint for the bus, we'll define the following variables:
- : the boolean flag that indicates whether or not a stack operation requiring range checks is occurring. This flag has degree 3.
- : the boolean flag that indicates whether or not a memory operation requiring range checks is occurring. This flag has degree 3.
- : the values for which range checks are requested from the stack when is set.
- : the values for which range checks are requested from the memory chiplet when is set.
As previously mentioned, constraints cannot include divisions, so the actual constraint which is applied will be the equivalent expression in which all denominators have been multiplied through, which is degree 9.
If is initialized to and the values sent to the bus by other VM components match those that are range-checked in the trace, then at the end of the trace we should end up with .
Therefore, in addition to the transition constraint described above, we also need to enforce the following boundary constraints:
- The value of in the first row .
- The value of in the last row .
Chiplets
The Chiplets module contains specialized components dedicated to accelerating complex computations. Each chiplet specializes in executing a specific type of computation and is responsible for proving both the correctness of its computations and its own internal consistency.
Currently, Miden VM relies on 4 chiplets:
- The Hash Chiplet (also referred to as the Hasher), used to compute Rescue Prime Optimized hashes both for sequential hashing and for Merkle tree hashing.
- The Bitwise Chiplet, used to compute bitwise operations (e.g.,
AND,XOR) over 32-bit integers. - The Memory Chiplet, used to support random-access memory in the VM.
- The Kernel ROM Chiplet, used to enable executing kernel procedures during the
SYSCALLoperation.
Each chiplet executes its computations separately from the rest of the VM and proves the internal correctness of its execution trace in a unique way that is specific to the operation(s) it supports. These methods are described by each chiplet’s documentation.
Chiplets module trace
The execution trace of the Chiplets module is generated by stacking the execution traces of each of its chiplet components. Because each chiplet is expected to generate significantly fewer trace rows than the other VM components (i.e., the decoder, stack, and range checker), stacking them enables the same functionality without adding as many columns to the execution trace.
Each chiplet is identified within the Chiplets module by one or more chiplet selector columns which cause its constraints to be selectively applied.
The result is an execution trace of 17 trace columns, which allows space for the widest chiplet component (the hash chiplet) and a column to select for it.
During the finalization of the overall execution trace, the chiplets' traces (including internal selectors) are appended to the trace of the Chiplets module one after another, as pictured. Thus, when one chiplet's trace ends, the trace of the next chiplet starts in the subsequent row.
Additionally, a padding segment is added to the end of the Chiplets module's trace so that the number of rows in the table always matches the overall trace length of the other VM processors, regardless of the length of the chiplet traces. The padding will simply contain zeroes.
Chiplets order
The order in which the chiplets are stacked is determined by the requirements of each chiplet, including the width of its execution trace and the degree of its constraints.
For simplicity, all of the "cyclic" chiplets which operate in multi-row cycles and require starting at particular row increments should come before any non-cyclic chiplets, and these should be ordered from longest-cycle to shortest-cycle. This avoids any additional alignment padding between chiplets.
After that, chiplets are ordered by degree of constraints so that higher-degree chiplets get lower-degree chiplet selector flags.
The resulting order is as follows:
| Chiplet | Cycle Length | Internal Degree | Chiplet Selector Degree | Total Degree | Columns | Chiplet Selector Flag |
|---|---|---|---|---|---|---|
| Hash chiplet | 8 | 8 | 1 | 9 | 17 | |
| Bitwise chiplet | 8 | 3 | 2 | 5 | 13 | |
| Memory | - | 6 | 3 | 9 | 12 | |
| Kernel ROM | - | 2 | 4 | 6 | 6 | |
| Padding | - | - | - | - | - |
Additional requirements for stacking execution traces
Stacking the chiplets introduces one new complexity. Each chiplet proves its own correctness with its own set of internal transition constraints, many of which are enforced between each row in its trace and the next row. As a result, when the chiplets are stacked, transition constraints applied to the final row of one chiplet will cause a conflict with the first row of the following chiplet.
This is true for any transition constraints which are applied at every row and selected by a Chiplet Selector Flag for the current row. (Therefore cyclic transition constraints controlled by periodic columns do not cause an issue.)
This requires the following adjustments for each chiplet.
In the hash chiplet: there is no conflict, and therefore no change, since all constraints are periodic.
In the bitwise chiplet: there is no conflict, and therefore no change, since all constraints are periodic.
In the memory chiplet: all transition constraints cause a conflict. To adjust for this, the selector flag for the memory chiplet is designed to exclude its last row. Thus, memory constraints will not be applied when transitioning from the last row of the memory chiplet to the subsequent row. This is achieved without any additional increase in the degree of constraints by using as a selector instead of as seen below.
In the kernel ROM chiplet: the transition constraints applied to the column cause a conflict. It is resolved by using a virtual flag to exclude the last row, which increases the degree of these constraints to .
Operation labels
Each operation supported by the chiplets is given a unique identifier to ensure that the requests and responses sent to the chiplets bus () are indeed processed by the intended chiplet for that operation and that chiplets which support more than one operation execute the correct one.
The labels are composed from the flag values of the chiplet selector(s) and internal operation selectors (if applicable). The unique label of the operation is computed as the binary aggregation of the combined selectors plus , note that the combined flag is represented in big-endian, so the bit representation below is reversed.
Note: We started moving away from this scheme with the memory chiplet, which more simply prepends the chiplet selector to the label (without reversing or adding 1).
| Operation | Chiplet Selector Flag | Internal Selector Flag | Combined Flag | Label |
|---|---|---|---|---|
HASHER_LINEAR_HASH | 3 | |||
HASHER_MP_VERIFY | 11 | |||
HASHER_MR_UPDATE_OLD | 7 | |||
HASHER_MR_UPDATE_NEW | 15 | |||
HASHER_RETURN_HASH | 1 | |||
HASHER_RETURN_STATE | 9 | |||
BITWISE_AND | 2 | |||
BITWISE_XOR | 6 | |||
MEMORY_WRITE_ELEMENT | 24 | |||
MEMORY_WRITE_WORD | 25 | |||
MEMORY_READ_ELEMENT | 26 | |||
MEMORY_READ_WORD | 27 | |||
KERNEL_PROC_CALL | 8 |
Chiplets module constraints
Chiplet constraints
Each chiplet's internal constraints are defined in the documentation for the individual chiplets. To ensure that constraints are only ever selected for one chiplet at a time, the module's selector columns are combined into flags. Each chiplet's internal constraints are multiplied by its chiplet selector flag, and the degree of each constraint is correspondingly increased.
This gives the following sets of constraints:
In the above:
- each represent an internal constraint from the indicated chiplet.
- indicates the degree of the specified constraint.
- flags are applied in a like manner for all internal constraints in each respective chiplet.
- the selector for the memory chiplet excludes the last row of the chiplet (as discussed above).
Chiplet selector constraints
We also need to ensure that the chiplet selector columns are set correctly. Although there are three columns for chiplet selectors, the stacked trace design means that they do not all act as selectors for the entire trace. Thus, selector constraints should only be applied to selector columns when they are acting as selectors.
- acts as a selector for the entire trace.
- acts as a selector column when .
- acts as a selector column when and .
- acts as a selector column when , , and .
Two conditions must be enforced for columns acting as chiplet selectors.
- When acting as a selector, the value in the selector column must be binary.
- When acting as a selector, the value in the selector column may only change from .
The following constraints ensure that selector values are binary.
The following constraints ensure that the chiplets are stacked correctly by restricting selector values so they can only change from .
In other words, the above constraints enforce that if a selector is in the current row, then it must be either or in the next row; if it is in the current row, it must be in the next row.
Chiplets bus
The chiplets must be explicitly connected to the rest of the VM in order for it to use their operations. This connection must prove that all specialized operations which a given VM component claimed to offload to one of the chiplets were in fact executed by the correct chiplet with the same set of inputs and outputs as those used by the offloading component.
This is achieved via a bus called where a request can be sent to any chiplet and a corresponding response will be sent back by that chiplet.
The bus is implemented as a single running product column where:
- Each request is “sent” by computing an operation-specific lookup value from an operation-specific label, the operation inputs, and the operation outputs, and then dividing it out of the running product column.
- Each chiplet response is “sent” by computing the same operation-specific lookup value from the label, inputs, and outputs, and then multiplying it into the running product column.
Thus, if the requests and responses match, then the bus column will start and end with the value . This condition is enforced by boundary constraints on the column.
Note that the order of the requests and responses does not matter, as long as they are all included in . In fact, requests and responses for the same operation will generally occur at different cycles.
Chiplets bus constraints
The chiplets bus constraints are defined by the components that use it to communicate.
Lookup requests are sent to the chiplets bus by the following components:
- The stack sends requests for bitwise, memory, and cryptographic hash operations.
- The decoder sends requests for hash operations for program block hashing.
- The decoder sends a procedure access request to the Kernel ROM chiplet for each
SYSCALLduring program block hashing.
Responses are provided by the hash, bitwise, memory, and kernel ROM chiplets.
Chiplets virtual table
Some chiplets require the use of a virtual table to maintain and enforce the correctness of their internal state. Because the length of these virtual tables does not exceed the length of the chiplets themselves, a single virtual table called can be shared by all chiplets.
Currently, the chiplets virtual table combines two virtual tables:
- the hash chiplet's sibling table
- the kernel ROM chiplet's kernel procedure table
To combine these correctly, the running product column for this table must be constrained not only at the beginning and the end of the trace, but also where the hash chiplet ends and where the kernel ROM chiplet begins. These positions can be identified using the chiplet selector columns.
Chiplets virtual table constraints
The expected boundary values for each chiplet's portion of the virtual table must be enforced. This can be done as follows.
For the sibling table to be properly constrained, the value of the running product column must be when the sibling table starts and finishes. This can be achieved by:
- enforcing a boundary constraint for at the first row
- using the following transition constraint to enforce that the value is once again at the last cycle of the hash chiplet.
For the kernel procedure table to be properly constrained, the value must be when it starts, and it must be equal to the product of all of the kernel ROM procedures when it finishes. This can be achieved by:
- enforcing a boundary constraint against the last row for the value of all of the kernel ROM procedures
- using the following transition constraint to enforce that when the active chiplet changes to the kernel ROM chiplet the value is .
Hash chiplet
Miden VM "offloads" all hash-related computations to a separate hash processor. This chiplet supports executing the Rescue Prime Optimized hash function (or rather a specific instantiation of it) in the following settings:
- A single permutation of Rescue Prime Optimized.
- A simple 2-to-1 hash.
- A linear hash of field elements.
- Merkle path verification.
- Merkle root update.
The chiplet can be thought of as having a small instruction set of instructions. These instructions are listed below, and examples of how these instructions are used by the chiplet are described in the following sections.
| Instruction | Description |
|---|---|
HR | Executes a single round of the VM's native hash function. All cycles which are not one less than a multiple of execute this instruction. That is, the chiplet executes this instruction on cycles , but not , and then again, , but not etc. |
BP | Initiates computation of a single permutation, a 2-to-1 hash, or a linear hash of many elements. This instruction can be executed only on cycles which are multiples of , and it can also be executed concurrently with an HR instruction. |
MP | Initiates Merkle path verification computation. This instruction can be executed only on cycles which are multiples of , and it can also be executed concurrently with an HR instruction. |
MV | Initiates Merkle path verification for the "old" node value during Merkle root update computation. This instruction can be executed only on cycles which are multiples of , and it can also be executed concurrently with an HR instruction. |
MU | Initiates Merkle path verification for the "new" node value during Merkle root update computation. This instruction can be executed only on cycles which are multiples of , and it can also be executed concurrently with an HR instruction. |
HOUT | Returns the result of the currently running computation. This instruction can be executed only on cycles which are one less than a multiple of (e.g. , etc.). |
SOUT | Returns the whole hasher state. This instruction can be executed only on cycles which are one less than a multiple of , and only if the computation was started using BP instruction. |
ABP | Absorbs a new set of elements into the hasher state when computing a linear hash of many elements. This instruction can be executed only on cycles which are one less than a multiple of , and only if the computation was started using BP instruction. |
MPA | Absorbs the next Merkle path node into the hasher state during Merkle path verification computation. This instruction can be executed only on cycles which are one less than a multiple of , and only if the computation was started using MP instruction. |
MVA | Absorbs the next Merkle path node into the hasher state during Merkle path verification for the "old" node value during Merkle root update computation. This instruction can be executed only on cycles which are one less than a multiple of , and only if the computation was started using MV instruction. |
MUA | Absorbs the next Merkle path node into the hasher state during Merkle path verification for the "new" node value during Merkle root update computation. This instruction can be executed only on cycles which are one less than a multiple of , and only if the computation was started using Mu instruction. |
Chiplet trace
Execution trace table of the chiplet consists of trace columns and periodic columns. The structure of the table is such that a single permutation of the hash function can be computed using table rows. The layout of the table is illustrated below.
The meaning of the columns is as follows:
- Three periodic columns , , and are used to help select the instruction executed at a given row. All of these columns contain patterns which repeat every rows. For the pattern is zeros followed by one, helping us identify the last row in the cycle. For the pattern is zeros, one, and zero, which can be used to identify the second-to-last row in a cycle. For the pattern is one followed by zeros, which can identify the first row in the cycle.
- Three selector columns , , and . These columns can contain only binary values (ones or zeros), and they are also used to help select the instruction to execute at a given row.
- Twelve hasher state columns . These columns are used to hold the hasher state for each round of the hash function permutation. The state is laid out as follows:
- The first four columns () are reserved for capacity elements of the state. When the state is initialized for hash computations, should be set to if the number of elements to be hashed is a multiple of the rate width (). Otherwise, should be set to . should be set to the domain value if a domain has been provided (as in the case of control block hashing). All other capacity elements should be set to 's.
- The next eight columns () are reserved for the rate elements of the state. These are used to absorb the values to be hashed. Once the permutation is complete, hash output is located in the first four rate columns ().
- One index column . This column is used to help with Merkle path verification and Merkle root update computations.
In addition to the columns described above, the chiplet relies on two running product columns which are used to facilitate multiset checks (similar to the ones described here). These columns are:
- - which is used to tie the chiplet table with the main VM's stack and decoder. That is, values representing inputs consumed by the chiplet and outputs produced by the chiplet are multiplied into , while the main VM stack (or decoder) divides them out of . Thus, if the sets of inputs and outputs between the main VM stack and hash chiplet are the same, the value of should be equal to at the start and the end of the execution trace.
- - which is used to keep track of the sibling table used for Merkle root update computations. Specifically, when a root for the old leaf value is computed, we add an entry for all sibling nodes to the table (i.e., we multiply by the values representing these entries). When the root for the new leaf value is computed, we remove the entries for the nodes from the table (i.e., we divide by the value representing these entries). Thus, if both computations used the same set of sibling nodes (in the same order), the sibling table should be empty by the time Merkle root update procedure completes (i.e., the value of would be ).
Instruction flags
As mentioned above, chiplet instructions are encoded using a combination of periodic and selector columns. These columns can be used to compute a binary flag for each instruction. Thus, when a flag for a given instruction is set to , the chiplet executes this instruction. Formulas for computing instruction flags are listed below.
| Flag | Value | Notes |
|---|---|---|
| Set to on the first steps of every -step cycle. | ||
| Set to when selector flags are on rows which are multiples of . | ||
| Set to when selector flags are on rows which are multiples of . | ||
| Set to when selector flags are on rows which are multiples of . | ||
| Set to when selector flags are on rows which are multiples of . | ||
| Set to when selector flags are on rows which are less than a multiple of . | ||
| Set to when selector flags are on rows which are less than a multiple of . | ||
| Set to when selector flags are on rows which are less than a multiple of . | ||
| Set to when selector flags are on rows which are less than a multiple of . | ||
| Set to when selector flags are on rows which are less than a multiple of . | ||
| Set to when selector flags are on rows which are less than a multiple of . |
A few additional notes about flag values:
- With the exception of , all flags are mutually exclusive. That is, if one flag is set to , all other flats are set to .
- With the exception of , computing flag values involves multiplications, and thus the degree of these flags is .
- We can also define a flag . This flag will be set to when either or in the current row.
- We can define a flag . This flag will be set to when either or in the next row.
We also impose the following restrictions on how values in selector columns can be updated:
- Values in columns and must be copied over from one row to the next, unless or indicating the
houtorsoutflag is set for the current or the next row. - Value in must be set to if for the previous row, and to if any of the flags , , , or are set to for the previous row.
The above rules ensure that we must finish one computation before starting another, and we can't change the type of the computation before the computation is finished.
Computation examples
Single permutation
Computing a single permutation of Rescue Prime Optimized hash function involves the following steps:
- Initialize hasher state with field elements.
- Apply Rescue Prime Optimized permutation.
- Return the entire hasher state as output.
The chiplet accomplishes the above by executing the following instructions:
[BP, HR] // init state and execute a hash round (concurrently)
HR HR HR HR HR HR // execute 6 more hash rounds
SOUT // return the entire state as output
Execution trace for this computation would look as illustrated below.
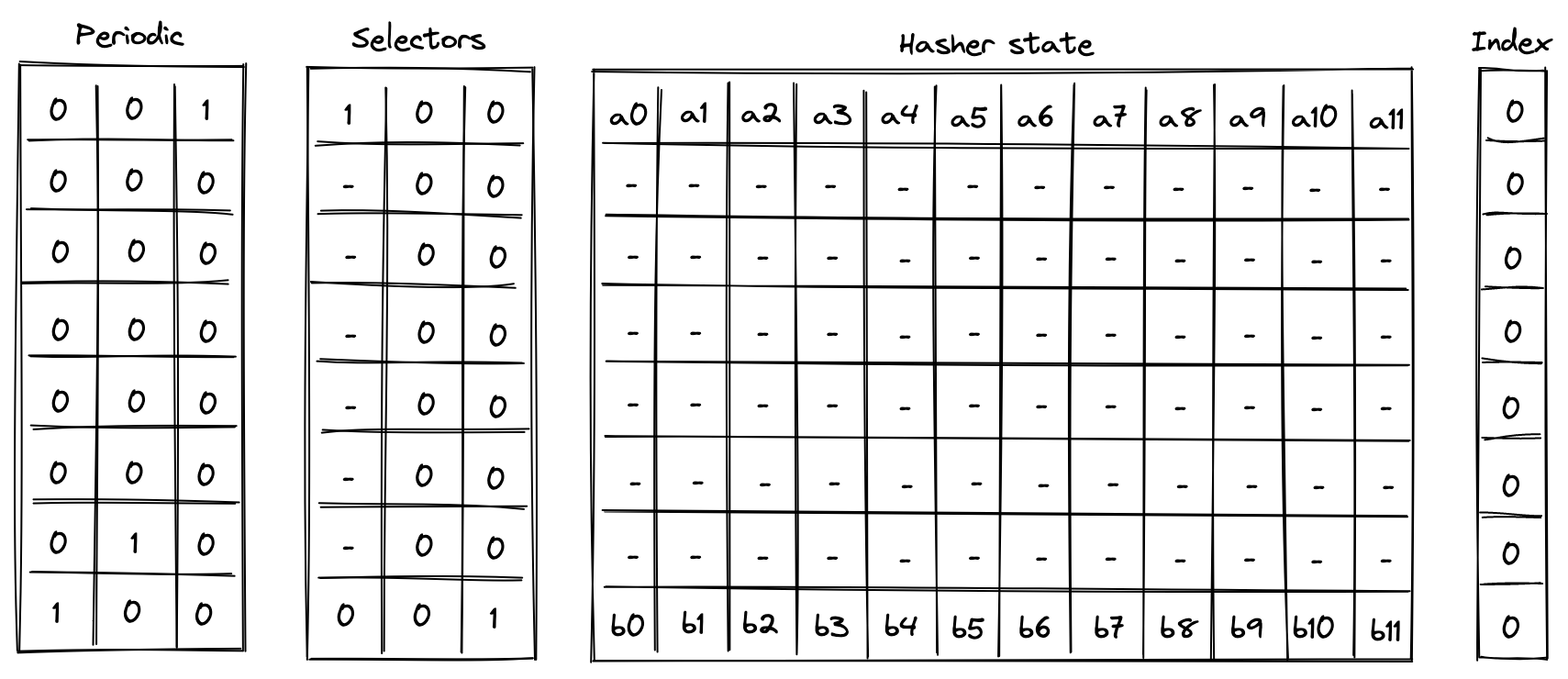
In the above is the input state of the hasher, and is the output state of the hasher.
Simple 2-to-1 hash
Computing a 2-to-1 hash involves the following steps:
- Initialize hasher state with field elements, setting the second capacity element to if the domain is provided (as in the case of control block hashing) or else , and the remaining capacity elements to .
- Apply Rescue Prime Optimized permutation.
- Return elements of the hasher state as output.
The chiplet accomplishes the above by executing the following instructions:
[BP, HR] // init state and execute a hash round (concurrently)
HR HR HR HR HR HR // execute 6 more hash rounds
HOUT // return elements 4, 5, 6, 7 of the state as output
Execution trace for this computation would look as illustrated below.
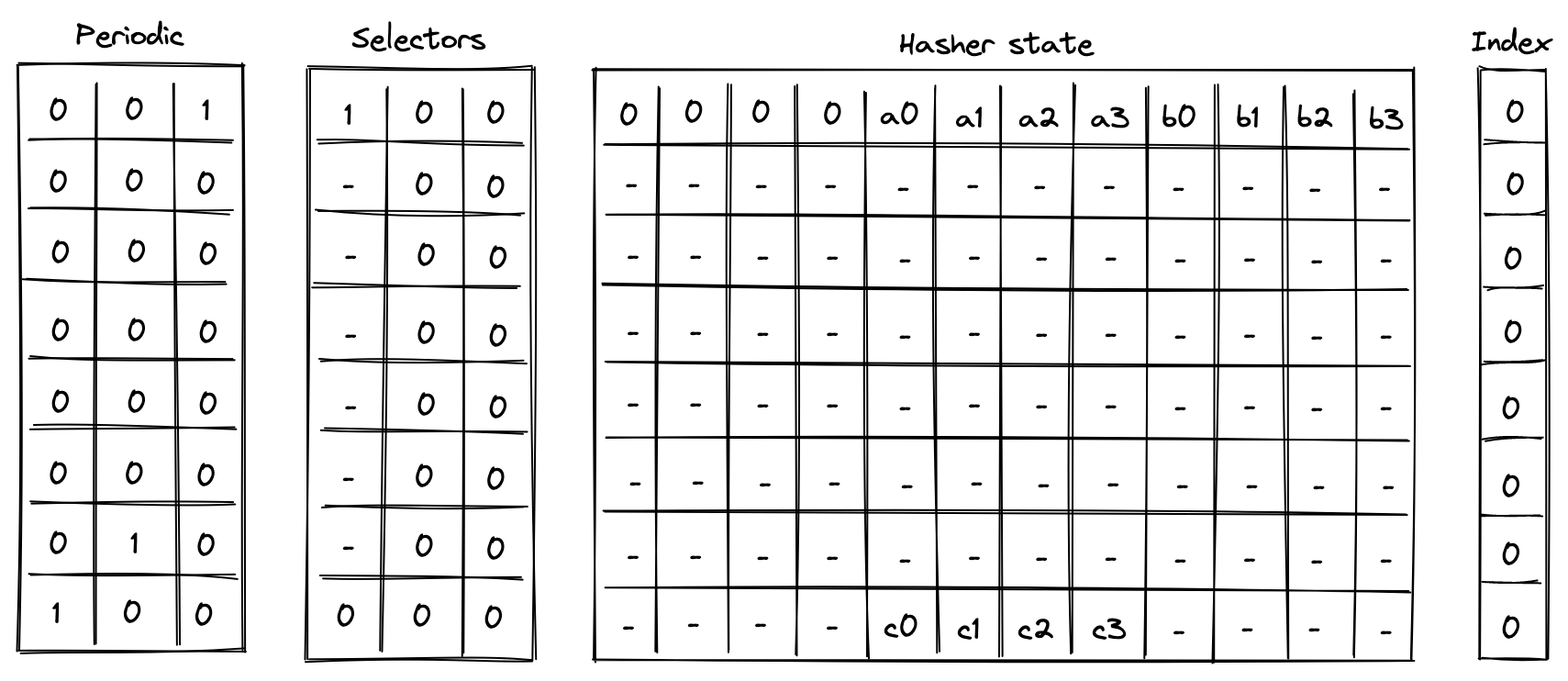
In the above, we compute the following:
Linear hash of n elements
Computing a linear hash of elements consists of the following steps:
- Initialize hasher state with the first elements, setting the first capacity register to if is a multiple of the rate width () or else , and the remaining capacity elements to .
- Apply Rescue Prime Optimized permutation.
- Absorb the next set of elements into the state (up to elements), while keeping capacity elements unchanged.
- Repeat steps 2 and 3 until all elements have been absorbed.
- Return elements of the hasher state as output.
The chiplet accomplishes the above by executing the following instructions (for hashing elements):
[BP, HR] // init state and execute a hash round (concurrently)
HR HR HR HR HR HR // execute 6 more hash rounds
ABP // absorb the next set of elements into the state
HR HR HR HR HR HR HR // execute 7 hash rounds
HOUT // return elements 4, 5, 6, 7 of the state as output
Execution trace for this computation would look as illustrated below.
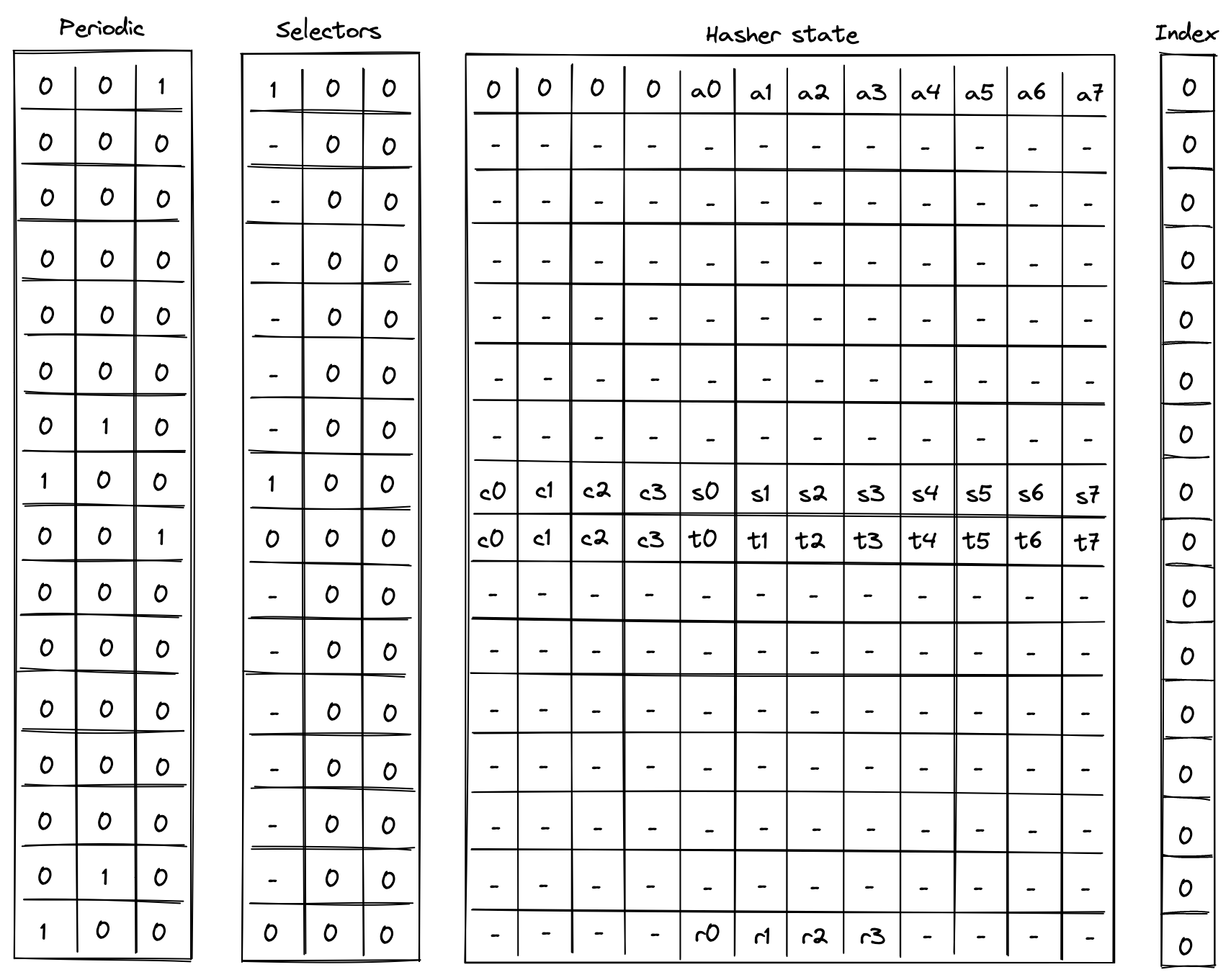
In the above, the value absorbed into hasher state between rows and is the delta between values and . Thus, if we define for , the above computes the following:
Verify Merkle path
Verifying a Merkle path involves the following steps:
- Initialize hasher state with the leaf and the first node of the path, setting all capacity elements to s. a. Also, initialize the index register to the leaf's index value.
- Apply Rescue Prime Optimized permutation. a. Make sure the index value doesn't change during this step.
- Copy the result of the hash to the next row, and absorb the next node of the Merkle path into the hasher state. a. Remove a single bit from the index, and use it to determine how to place the copied result and absorbed node in the state.
- Repeat steps 2 and 3 until all nodes of the Merkle path have been absorbed.
- Return elements of the hasher state as output. a. Also, make sure the index value has been reduced to .
The chiplet accomplishes the above by executing the following instructions (for Merkle tree of depth ):
[MP, HR] // init state and execute a hash round (concurrently)
HR HR HR HR HR HR // execute 6 more hash rounds
MPA // copy result & absorb the next node into the state
HR HR HR HR HR HR HR // execute 7 hash rounds
HOUT // return elements 4, 5, 6, 7 of the state as output
Suppose we have a Merkle tree as illustrated below. This Merkle tree has leaves, each of which consists of field elements. For example, leaf consists of elements , leaf be consists of elements etc.
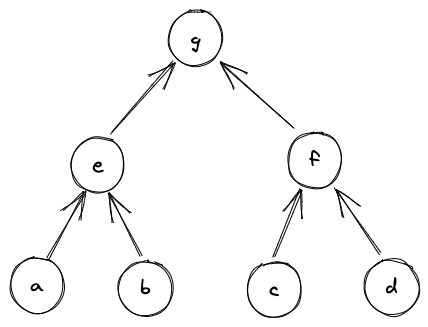
If we wanted to verify that leaf is in fact in the tree, we'd need to compute the following hashes:
And if , we can be convinced that is in fact in the tree at position . Execution trace for this computation would look as illustrated below.
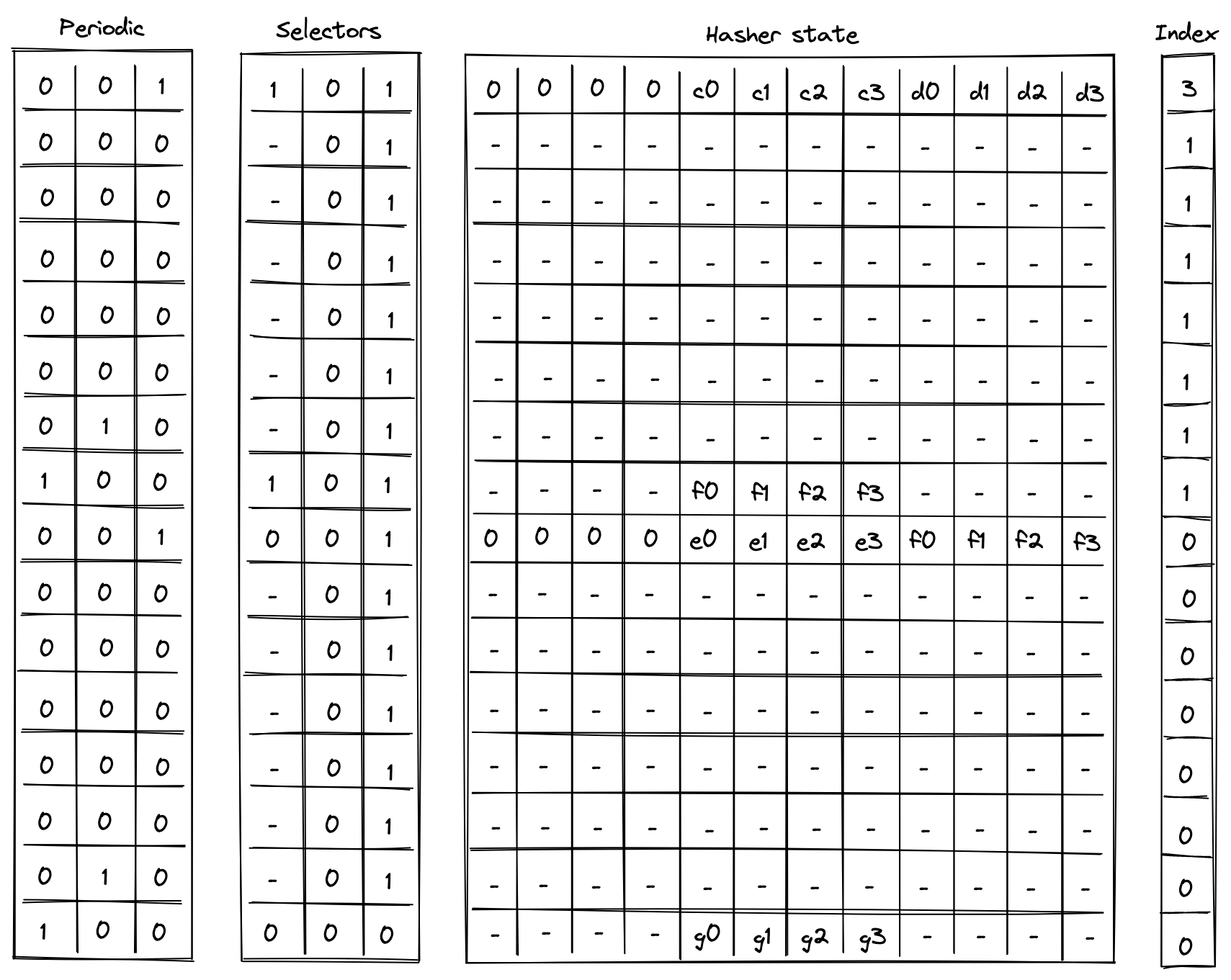
In the above, the prover provides values for nodes and non-deterministically.
Update Merkle root
Updating a node in a Merkle tree (which also updates the root of the tree) can be simulated by verifying two Merkle paths: the path that starts with the old leaf and the path that starts with the new leaf.
Suppose we have the same Merkle tree as in the previous example, and we want to replace node with node . The computations we'd need to perform are:
Then, as long as , and the same values were used for and in both computations, we can be convinced that the new root of the tree is .
The chiplet accomplishes the above by executing the following instructions:
// verify the old merkle path
[MV, HR] // init state and execute a hash round (concurrently)
HR HR HR HR HR HR // execute 6 more hash rounds
MPV // copy result & absorb the next node into the state
HR HR HR HR HR HR HR // execute 7 hash rounds
HOUT // return elements 4, 5, 6, 7 of the state as output
// verify the new merkle path
[MU, HR] // init state and execute a hash round (concurrently)
HR HR HR HR HR HR // execute 6 more hash rounds
MPU // copy result & absorb the next node into the state
HR HR HR HR HR HR HR // execute 7 hash rounds
HOUT // return elements 4, 5, 6, 7 of the state as output
The semantics of MV and MU instructions are similar to the semantics of MP instruction from the previous example (and MVA and MUA are similar to MPA) with one important difference: MV* instructions add the absorbed node (together with its index in the tree) to permutation column , while MU* instructions remove the absorbed node (together with its index in the tree) from . Thus, if the same nodes were used during both Merkle path verification, the state of should not change. This mechanism is used to ensure that the same internal nodes were used in both computations.
AIR constraints
When describing AIR constraints, we adopt the following notation: for column , we denote the value in the current row simply as , and the value in the next row of the column as . Thus, all transition constraints described in this note work with two consecutive rows of the execution trace.
Selector columns constraints
For selector columns, first we must ensure that only binary values are allowed in these columns. This can be done with the following constraints:
Next, we need to make sure that unless or , the values in columns and are copied over to the next row. This can be done with the following constraints:
Next, we need to enforce that if any of flags is set to , the next value of is . In all other cases, should be unconstrained. These flags will only be set for rows that are 1 less than a multiple of 8 (the last row of each cycle). This can be done with the following constraint:
Lastly, we need to make sure that no invalid combinations of flags are allowed. This can be done with the following constraints:
The above constraints enforce that on every step which is one less than a multiple of , if , then must also be set to . Basically, if we set , then we must make sure that either or .
Node index constraints
Node index column is relevant only for Merkle path verification and Merkle root update computations, but to simplify the overall constraint system, the same constraints will be imposed on this column for all computations.
Overall, we want values in the index column to behave as follows:
- When we start a new computation, we should be able to set to an arbitrary value.
- When a computation is finished, value in must be .
- When we absorb a new node into the hasher state we must shift the value in by one bit to the right.
- In all other cases value in should not change.
A shift by one bit to the right can be described with the following equation: , where is the value of the bit which is discarded. Thus, as long as is a binary value, the shift to the right is performed correctly, and this can be enforced with the following constraint:
Since we want to enforce this constraint only when a new node is absorbed into the hasher state, we'll define a flag for when this should happen as follows:
And then the full constraint would looks as follows:
Next, to make sure when a computation is finished , we can use the following constraint:
Finally, to make sure that the value in is copied over to the next row unless we are absorbing a new row or the computation is finished, we impose the following constraint:
To satisfy these constraints for computations not related to Merkle paths (i.e., 2-to-1 hash and liner hash of elements), we can set at the start of the computation. This guarantees that will remain until the end of the computation.
Hasher state constraints
Hasher state columns should behave as follows:
- For the first row of every -row cycle (i.e., when ), we need to apply Rescue Prime Optimized round constraints to the hasher state. For brevity, we omit these constraints from this note.
- On the th row of every -row cycle, we apply the constraints based on which transition flag is set as described in the table below.
Specifically, when absorbing the next set of elements into the state during linear hash computation (i.e., ), the first elements (the capacity portion) are carried over to the next row. For this can be described as follows:
When absorbing the next node during Merkle path computation (i.e., ), the result of the previous hash () are copied over either to or to depending on the value of , which is defined in the same way as in the previous section. For this can be described as follows:
Note, that when a computation is completed (i.e., ), the next hasher state is unconstrained.
Multiset check constraints
In this sections we describe constraints which enforce updates for multiset check columns and . These columns can be updated only on rows which are multiples of or less than a multiple of . On all other rows the values in the columns remain the same.
To simplify description of the constraints, we define the following variables. Below, we denote random values sent by the verifier after the prover commits to the main execution trace as , , etc.
In the above:
- is a transition label, composed of the operation label and the periodic columns that uniquely identify each transition function. The values in the and periodic columns are included to identify the row in the hash cycle where the operation occurs. They serve to differentiate between operations that share selectors but occur at different rows in the cycle, such as
BP, which uses at the first row in the cycle to initiate a linear hash, andABP, which uses at the last row in the cycle to absorb new elements. - is a common header which is a combination of the transition label, a unique row address, and the node index. For the unique row address, the
clkcolumn from the system component is used, but we add , because the system'sclkcolumn starts at . - , , are the first, second, and third words (4 elements) of the hasher state.
- is the third word of the hasher state but computed using the same values as used for the second word. This is needed for computing the value of below to ensure that the same values are used for the leaf node regardless of which part of the state the node comes from.
Chiplets bus constraints
As described previously, the chiplets bus , implemented as a running product column, is used to tie the hash chiplet with the main VM's stack and decoder. When receiving inputs from or returning results to the stack (or decoder), the hash chiplet multiplies by their respective values. On the other side, when sending inputs to the hash chiplet or receiving results from the chiplet, the stack (or decoder) divides by their values.
In the section below we describe only the hash chiplet side of the constraints (i.e., multiplying by relevant values). We define the values which are to be multiplied into for each operation as follows:
When starting a new simple or linear hash computation (i.e., ) or when returning the entire state of the hasher (), the entire hasher state is included into :
When starting a Merkle path computation (i.e., ), we include the leaf of the path into . The leaf is selected from the state based on value of (defined as in the previous section):
When absorbing a new set of elements into the state while computing a linear hash (i.e., ), we include deltas between the last elements of the hasher state (the rate) into :
When a computation is complete (i.e., ), we include the second word of the hasher state (the result) into :
Using the above values, we can describe the constraints for updating column as follows.
The above constraint reduces to the following under various flag conditions:
| Condition | Applied constraint |
|---|---|
| Otherwise |
Note that the degree of the above constraint is .
Sibling table constraints
Note: Although this table is described independently, it is implemented as part of the chiplets virtual table, which combines all virtual tables required by any of the chiplets into a single master table.
As mentioned previously, the sibling table (represented by running column ) is used to keep track of sibling nodes used during Merkle root update computations. For this computation, we need to enforce the following rules:
- When computing the old Merkle root, whenever a new sibling node is absorbed into the hasher state (i.e., ), an entry for this sibling should be included into .
- When computing the new Merkle root, whenever a new sibling node is absorbed into the hasher state (i.e., ), the entry for this sibling should be removed from .
To simplify the description of the constraints, we use variables and defined above and define the value representing an entry in the sibling table as follows:
Using the above value, we can define the constraint for updating as follows:
The above constraint reduces to the following under various flag conditions:
| Condition | Applied constraint |
|---|---|
| Otherwise |
Note that the degree of the above constraint is .
To make sure computation of the old Merkle root is immediately followed by the computation of the new Merkle root, we impose the following constraint:
The above means that whenever we start a new computation which is not the computation of the new Merkle root, the sibling table must be empty. Thus, after the hash chiplet computes the old Merkle root, the only way to clear the table is to compute the new Merkle root.
Together with boundary constraints enforcing that at the first and last rows of the running product column which implements the sibling table, the above constraints ensure that if a node was included into as a part of computing the old Merkle root, the same node must be removed from as a part of computing the new Merkle root. These two boundary constraints are described as part of the chiplets virtual table constraints.
Bitwise chiplet
In this note we describe how to compute bitwise AND and XOR operations on 32-bit values and the constraints required for proving correct execution.
Assume that and are field elements in a 64-bit prime field. Assume also that and are known to contain values smaller than . We want to compute , where is either bitwise AND or XOR, and is a field element containing the result of the corresponding bitwise operation.
First, observe that we can compute AND and XOR relations for single bit values as follows:
To compute bitwise operations for multi-bit values, we will decompose the values into individual bits, apply the operations to single bits, and then aggregate the bitwise results into the final result.
To perform this operation we will use a table with 12 columns, and computing a single AND or XOR operation will require 8 table rows. We will also rely on two periodic columns as shown below.
In the above, the columns have the following meanings:
- Periodic columns and . These columns contain values needed to switch various constraints on or off. contains a single one, followed by a repeating sequence of seven zeros. contains a repeating sequence of seven ones, followed by a single zero.
- Input columns and . On the first row of each 8-row cycle, the prover will set values in these columns to the upper 4 bits of the values to which a bitwise operation is to be applied. For all subsequent rows, we will append the next-most-significant 4-bit limb to each value. Thus, by the final row columns and will contain the full input values for the bitwise operation.
- Columns , , , , , , , will contain lower 4 bits of their corresponding values.
- Output column . This column represents the value of column for the prior row. For the first row, it is set to .
- Output column . This column will be used to aggregate the results of bitwise operations performed over columns , , , , , , , . By the time we get to the last row in each 8-row cycle, this column will contain the final result.
Example
Let's illustrate the above table on a concrete example. For simplicity, we'll use 16-bit values, and thus, we'll only need 4 rows to complete the operation (rather than 8 for 32-bit values). Let's say (b1010_0011_0111_1011) and (b1001_1101_1110_1010), then (b1000_0001_0110_1010). The table for this computation looks like so:
| a | b | a0 | a1 | a2 | a3 | b0 | b1 | b2 | b3 | zp | z |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 9 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 8 |
| 163 | 157 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 8 | 129 |
| 2615 | 2526 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 129 | 2070 |
| 41851 | 40426 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 2070 | 33130 |
Here, in the first row, we set each of the and columns to the value of their most-significant 4-bit limb. The bit columns ( and ) in the first row contain the lower 4 bits of their corresponding values (b1010 and b1001). Column contains the result of bitwise AND for the upper 4 bits (b1000), while column contains that result for the prior row.
With every subsequent row, we inject the next-most-significant 4 bits of each value into the bit columns, increase the and columns accordingly, and aggregate the result of bitwise AND into the column, adding it to times the value of in the previous row. We set column to be the value of in the prior row. By the time we get to the last row, the column contains the result of the bitwise AND, while columns and contain their original values.
Constraints
AIR constraints needed to ensure the correctness of the above table are described below. We also add one more column to the execution trace, to allow us to select between two bitwise operations (U32AND and U32XOR).
Selectors
The Bitwise chiplet supports two operations with the following operation selectors:
U32AND:U32XOR:
The constraints must require that the selectors be binary and stay the same throughout the cycle:
Input decomposition
We need to make sure that inputs and are decomposed correctly into their individual bits. To do this, first, we need to make sure that columns , , , , , , , , can contain only binary values ( or ). This can be accomplished with the following constraints (for ranging between and ):
Then, we need to make sure that on the first row of every 8-row cycle, the values in the columns and are exactly equal to the aggregation of binary values contained in the individual bit columns , and . This can be enforced with the following constraints:
The above constraints enforce that when , and .
Lastly, we need to make sure that for all rows in an 8-row cycle except for the last one, the values in and columns are increased by the values contained in the individual bit columns and . Denoting as the value of column in the current row, and as the value of column in the next row, we can enforce these conditions as follows:
The above constraints enforce that when , and .
Output aggregation
To ensure correct aggregation of operations over individual bits, first we need to ensure that in the first row, the aggregated output value of the previous row should be 0.
Next, we need to ensure that for each row except the last, the aggregated output value must equal the previous aggregated output value in the next row.
Lastly, we need to ensure that for all rows the value in the column is computed by multiplying the previous output value (from the column in the current row) by 16 and then adding it to the bitwise operation applied to the row's set of bits of and . The entire constraint must also be multiplied by the operation selector flag to ensure it is only applied for the appropriate operation.
For U32AND, this is enforced with the following constraint:
For U32XOR, this is enforced with the following constraint:
Chiplets bus constraints
To simplify the notation for describing bitwise constraints on the chiplets bus, we'll first define variable , which represents how , , and in the execution trace are reduced to a single value. Denoting the random values received from the verifier as , etc., this can be achieved as follows.
Where, is the unique operation label of the bitwise operation.
The request side of the constraint for the bitwise operation is described in the stack bitwise operation section.
To provide the results of bitwise operations to the chiplets bus, we want to include values of , and at the last row of the cycle.
First, we'll define another intermediate variable . It will include into the product when . ( represents the value of for row of the trace.)
Then, setting , we can compute the permutation product from the bitwise chiplet as follows:
The above ensures that when (which is true for all rows in the 8-row cycle except for the last one), the product does not change. Otherwise, gets included into the product.
The response side of the bus communication can be enforced with the following constraint:
Memory chiplet
Miden VM supports linear read-write random access memory. This memory is element-addressable, meaning that a single value is located at each address, although reading and writing values to/from memory in batches of four is supported. Each value is a field element in a -bit prime field with modulus . A memory address is a field element in the range .
In this note we describe the rationale for selecting the above design and describe AIR constraints needed to support it.
The design makes extensive use of -bit range checks. An efficient way of implementing such range checks is described here.
Alternative designs
The simplest (and most efficient) alternative to the above design is contiguous write-once memory. To support such memory, we need to allocate just two trace columns as illustrated below.
In the above, addr column holds memory address, and value column holds the field element representing the value stored at this address. Notice that some rows in this table are duplicated. This is because we need one row per memory access (either read or write operation). In the example above, value was first stored at memory address , and then read from this address.
The AIR constraints for this design are very simple. First, we need to ensure that values in the addr column either remain the same or are incremented by as we move from one row to the next. This can be achieved with the following constraint:
where is the value in addr column in the current row, and is the value in this column in the next row.
Second, we need to make sure that if the value in the addr column didn't change, the value in the value column also remained the same (i.e., a value stored in a given address can only be set once). This can be achieved with the following constraint:
where is the value in value column at the current row, and is the value in this column in the next row.
As mentioned above, this approach is very efficient: each memory access requires just trace cells.
Read-write memory
Write-once memory is tricky to work with, and many developers may need to climb a steep learning curve before they become comfortable working in this model. Thus, ideally, we'd want to support read-write memory. To do this, we need to introduce additional columns as illustrated below.
In the above, we added clk column, which keeps track of the clock cycle at which memory access happened. We also need to differentiate between memory reads and writes. To do this, we now use two columns to keep track of the value: old val contains the value stored at the address before the operation, and new val contains the value after the operation. Thus, if old val and new val are the same, it was a read operation. If they are different, it was a write operation.
The AIR constraints needed to support the above structure are as follows.
We still need to make sure memory addresses are contiguous:
Whenever memory address changes, we want to make sure that old val is set to (i.e., our memory is always initialized to ). This can be done with the following constraint:
On the other hand, if memory address doesn't change, we want to make sure that new val in the current row is the same as old val in the next row. This can be done with the following constraint:
Lastly, we need to make sure that for the same address values in clk column are always increasing. One way to do this is to perform a -bit range check on the value of , where is the reference to clk column. However, this would mean that memory operations involving the same address must happen within VM cycles from each other. This limitation would be difficult to enforce statically. To remove this limitation, we need to add two more columns as shown below:

In the above column d0 contains the lower bits of while d1 contains the upper bits. The constraint needed to enforces this is as follows:
Additionally, we need to apply -bit range checks to columns d0 and d1.
Overall, the cost of reading or writing a single element is now trace cells and -bit range-checks.
Non-contiguous memory
Requiring that memory addresses are contiguous may also be a difficult limitation to impose statically. To remove this limitation, we need to introduce one more column as shown below:

In the above, the prover sets the value in the new column t to when the address doesn't change, and to otherwise. To simplify constraint description, we'll define variable computed as follows:
Then, to make sure the prover sets the value of correctly, we'll impose the following constraints:
The above constraints ensure that whenever the address changes, and otherwise. We can then define the following constraints to make sure values in columns d0 and d1 contain either the delta between addresses or between clock cycles.
| Condition | Constraint | Comments |
|---|---|---|
When the address changes, columns d0 and d1 at the next row should contain the delta between the old and the new address. | ||
When the address remains the same, columns d0 and d1 at the next row should contain the delta between the old and the new clock cycle. |
We can combine the above constraints as follows:
The above constraint, in combination with -bit range checks against columns d0 and d1 ensure that values in addr and clk columns always increase monotonically, and also that column addr may contain duplicates, while values in clk column must be unique for a given address.
Context separation
In many situations it may be desirable to assign memories to different contexts. For example, when making a cross-contract calls, the memories of the caller and the callee should be separate. That is, the caller should not be able to access the memory of the callee and vice-versa.
To accommodate this feature, we need to add one more column as illustrated below.
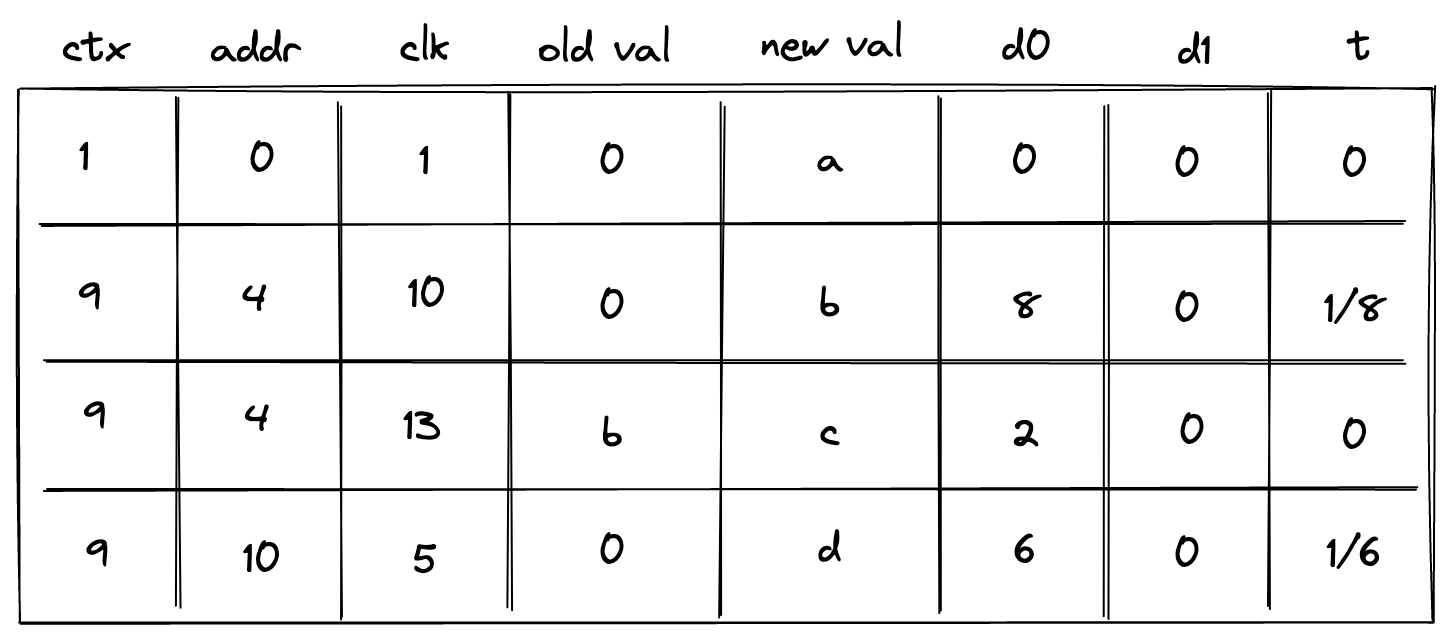
This new column ctx should behave similarly to the address column: values in it should increase monotonically, and there could be breaks between them. We also need to change how the prover populates column t:
- If the context changes,
tshould be set to the inverse , where is a reference to columnctx. - If the context remains the same but the address changes, column
tshould be set to the inverse of . - Otherwise, column
tshould be set to .
To simplify the description of constraints, we'll define two variables and as follows:
Thus, when the context changes, and otherwise. Also, when context remains the same and address changes, and otherwise.
To make sure the prover sets the value of column t correctly, we'll need to impose the following constraints:
We can then define the following constraints to make sure values in columns d0 and d1 contain the delta between contexts, between addresses, or between clock cycles.
| Condition | Constraint | Comments |
|---|---|---|
When the context changes, columns d0 and d1 at the next row should contain the delta between the old and the new contexts. | ||
| | When the context remains the same but the address changes, columns d0 and d1 at the next row should contain the delta between the old and the new addresses. | |
| | When both the context and the address remain the same, columns d0 and d1 at the next row should contain the delta between the old and the new clock cycle. |
We can combine the above constraints as follows:
The above constraint, in combination with -bit range checks against columns d0 and d1 ensure that values in ctx, addr, and clk columns always increase monotonically, and also that columns ctx and addr may contain duplicates, while the values in column clk must be unique for a given combination of ctx and addr.
Notice that the above constraint has degree .
Miden approach
While the approach described above works, it comes at significant cost. Reading or writing a single value requires trace cells and -bit range checks. Assuming a single range check requires roughly trace cells, the total number of trace cells needed grows to . This is about x worse the simple contiguous write-once memory described earlier.
Miden VM frequently needs to deal with batches of field elements, which we call words. For example, the output of Rescue Prime Optimized hash function is a single word. A single 256-bit integer value can be stored as two words (where each element contains one -bit value). Thus, we can optimize for this common use case by making the chiplet handle words as opposed to individual elements. That is, memory is still element-addressable in that each memory address stores a single field element, and memory addresses may be read or written individually. However, the chiplet also handles reading and writing elements in batches of four simultaneously, with the restriction that such batches be word-aligned addresses (i.e. the address is a multiple of 4).
The layout of Miden VM memory table is shown below:

where:
rwis a selector column which is set to for read operations and for write operations.ewis a selector column which is set to when a word is being accessed, and when an element is being accessed.ctxcontains context ID. Values in this column must increase monotonically but there can be gaps between two consecutive values of up to . Also, two consecutive values can be the same.word_addrcontains the memory address of the first element in the word. Values in this column must increase monotonically for a given context but there can be gaps between two consecutive values of up to . Values in this column must be divisible by 4. Also, two consecutive values can be the same.idx0andidx1are selector columns used to identify which element in the word is being accessed. Specifically, the index within the word is computed asidx1 * 2 + idx0.- However, when
ewis set to (indicating that a word is accessed), these columns are meaningless and are set to .
- However, when
clkcontains clock cycle at which the memory operation happened. Values in this column must increase monotonically for a given context and memory word but there can be gaps between two consecutive values of up to .- Unlike the previously described approaches, we allow
clkto be constant in the same context/word address, with the restriction that when this is the case, then only reads are allowed.
- Unlike the previously described approaches, we allow
v0, v1, v2, v3columns contain field elements stored at a given context/word/clock cycle after the memory operation.- Columns
d0andd1contain lower and upper bits of the delta between two consecutive context IDs, addresses, or clock cycles. Specifically:- When the context changes within a frame, these columns contain in the "next" row.
- When the context remains the same but the word address changes within a frame, these columns contain in the "next" row.
- When both the context and the word address remain the same within a frame, these columns contain in the "next" row.
- Column
tcontains the inverse of the delta between two consecutive context IDs, addresses, or clock cycles. Specifically:- When the context changes within a frame, this column contains the inverse of in the "next" row.
- When the context remains the same but the word address changes within a frame, this column contains the inverse of in the "next" row.
- When both the context and the word address remain the same within a frame, this column contains the inverse of in the "next" row.
- Column
f_scwstands for "flag same context and word address", which is set to when the current and previous rows have the same context and word address, and otherwise.
For every memory access operation (i.e., read or write a word or element), a new row is added to the memory table. If neither ctx nor addr have changed, the v columns are set to equal the values from the previous row (except for any element written to). If ctx or addr have changed, then the v columns are initialized to (except for any element written to).
AIR constraints
We first define the memory chiplet selector flags. , and will refer to the chiplet selector flags.
-
is set to 1 when the current row is in the memory chiplet.
-
is set to 1 when the current row is in the memory chiplet, except for the last row of the chiplet.
- is set to 1 when the next row is the first row of the memory chiplet.
To simplify description of constraints, we'll define two variables and as follows:
Where and .
To make sure the prover sets the value of column t correctly, we'll need to impose the following constraints:
The above constraints guarantee that when context changes, . When context remains the same but word address changes, . And when neither the context nor the word address change, .
We enforce that the rw, ew, idx0 and idx1 contain binary values.
To enforce the values of context ID, word address, and clock cycle grow monotonically as described in the previous section, we define the following constraint.
In addition to this constraint, we also need to make sure that the values in registers and are less than , and this can be done with range checks.
Next, we need to ensure that when the context, word address and clock are constant in a frame, then only read operations are allowed in that clock cycle.
Next, for all frames where the "current" and "next" rows are in the chiplet, we need to ensure that the value of the f_scw column in the "next" row is set to when the context and word address are the same, and otherwise.
Note that this does not constrain the value of f_scw in the first row of the chiplet. This is intended, as the first row's constraints do not depend on the previous row (since the previous row is not part of the same chiplet), and therefore do not depend on f_scw (see "first row" constraints below).
Finally, we need to constrain the v0, v1, v2, v3 columns. We will define a few variables to help in defining the constraints.
The flag is set to when is being accessed, and otherwise. Next, for ,
which is set to when is not written to, and otherwise.
We're now ready to describe the constraints for the v0, v1, v2, v3 columns.
- For the first row of the chiplet (in the "next" position of the frame), for ,
That is, if the next row is the first row of the memory chiplet, and is not written to, then must be .
- For all rows of the chiplet except the first, for ,
That is, if is not written to, then either its value needs to be copied over from the previous row (when ), or it must be set to 0 (when ).
Chiplets bus constraints
Communication between the memory chiplet and the stack is accomplished via the chiplets bus . To respond to memory access requests from the stack, we need to divide the current value in by the value representing a row in the memory table. This value can be computed as follows:
where
and where is the appropriate operation label of the memory access operation.
To ensure that values of memory table rows are included into the chiplets bus, we impose the following constraint:
On the stack side, for every memory access request, a corresponding value is divided out of the column. Specifics of how this is done are described here.
Kernel ROM chiplet
The kernel ROM enables executing predefined kernel procedures. These procedures are always executed in the root context and can only be accessed by a SYSCALL operation. The chiplet tracks and enforces correctness of all kernel procedure calls as well as maintaining a list of all the procedures defined for the kernel, whether they are executed or not. More background about Miden VM execution contexts can be found here.
Kernel ROM trace
The kernel ROM table consists of 6 columns.
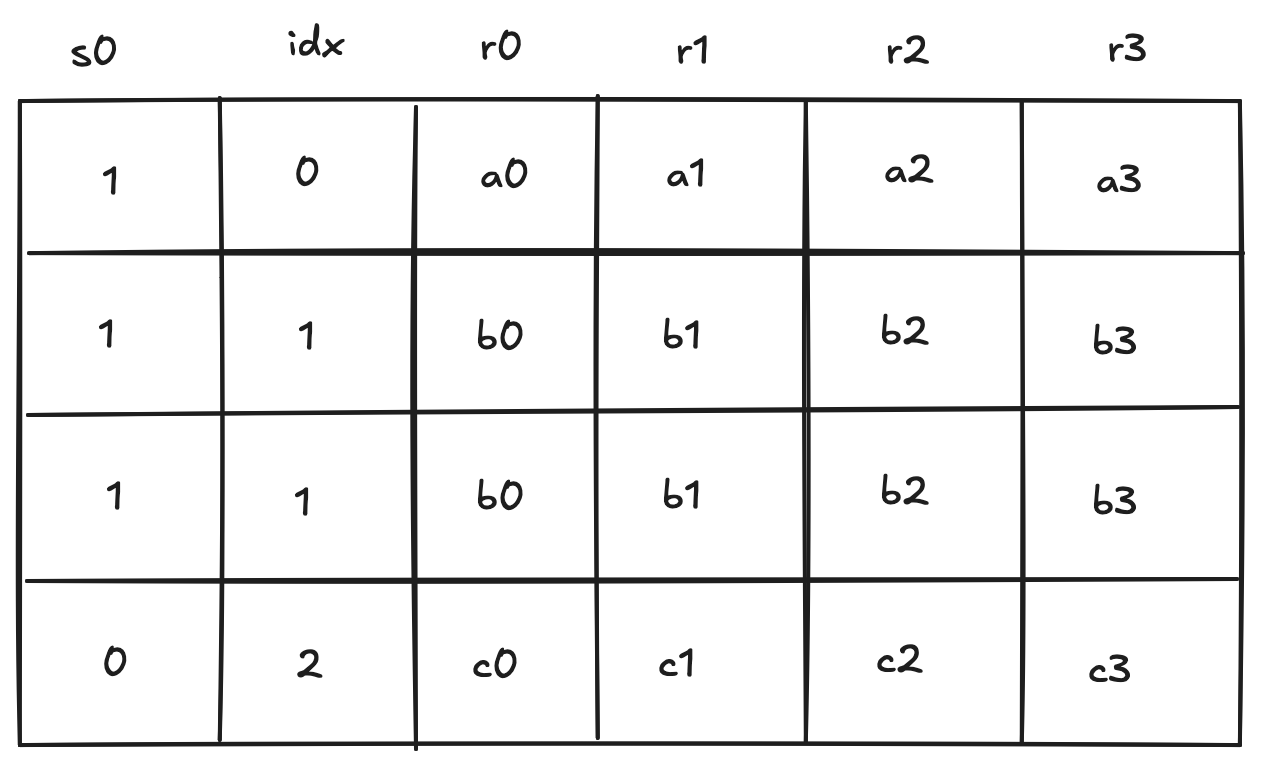
The meaning of columns in the above is as follows:
- Column specifies whether the value in the row should be included into the chiplets bus .
- is a column which starts out at and must either remain the same or be incremented by with every row.
- are contain the roots of the kernel functions. The values in these columns can change only when the value in the column changes. If the column remains the same, the values in the columns must also remain the same.
Constraints
The following constraints are required to enforce correctness of the kernel ROM trace.
For convenience, let's define .
The column must be binary.
The value in the column must either stay the same or increase by .
Finally, if the column stays the same then the kernel procedure root must not change. This can be achieved by enforcing the following constraint against each of the four procedure root columns:
These constraints on should not be applied to the very last row of the kernel ROM's execution trace, since we do not want to enforce a value that would conflict with the first row of a subsequent chiplet (or padding). Therefore we can create a special virtual flag for this constraint using the selector column from the chiplets module that selects for the kernel ROM chiplet.
The modified constraints which should be applied are the following:
Note: these constraints should also be multiplied by chiplets module's selector flag for the kernel ROM chiplet, as is true for all constraints in this chiplet.
Chiplets bus constraints
The chiplets bus is used to keep track of all kernel function calls. To simplify the notation for describing kernel ROM constraints on the chiplets bus, we'll first define variable , which represents how each kernel procedure in the kernel ROM's execution trace is reduced to a single value. Denoting the random values received from the verifier as , etc., this can be achieved as follows.
Where, is the unique operation label of the kernel procedure call operation.
The request side of the constraint for the operation is enforced during program block hashing of the SYSCALL operation.
To provide accessed kernel procedures to the chiplets bus, we must send the kernel procedure to the bus every time it is called, which is indicated by the column.
Thus, when this reduces to , but when it becomes .
Kernel procedure table constraints
Note: Although this table is described independently, it is implemented as part of the chiplets virtual table, which combines all virtual tables required by any of the chiplets into a single master table.
This kernel procedure table keeps track of all unique kernel function roots. The values in this table will be updated only when the value in the idx column changes.
The row value included into is:
The constraint against is:
Thus, when , the above reduces to , but when , the above becomes .
We also need to impose boundary constraints to make sure that running product column implementing the kernel procedure table is equal to when the kernel procedure table begins and to the product of all unique kernel functions when it ends. The last boundary constraint means that the verifier only needs to know which kernel was used, but doesn't need to know which functions were invoked within the kernel. These two constraints are described as part of the chiplets virtual table constraints.
Lookup arguments in Miden VM
Zero knowledge virtual machines frequently make use of lookup arguments to enable performance optimizations. Miden VM uses two types of arguments: multiset checks and a multivariate lookup based on logarithmic derivatives known as LogUp. A brief introduction to multiset checks can be found here. The description of LogUp can be found here.
In Miden VM, lookup arguments are used for two purposes:
- To prove the consistency of intermediate values that must persist between different cycles of the trace without storing the full data in the execution trace (which would require adding more columns to the trace).
- To prove correct interaction between two independent sections of the execution trace, e.g., between the main trace where the result of some operation is required, but would be expensive to compute, and a specialized component which can perform that operation cheaply.
The first is achieved using virtual tables of data, where we add a row at some cycle in the trace and remove it at a later cycle when it is needed again. Instead of maintaining the entire table in the execution trace, multiset checks allow us to prove data consistency of this table using one running product column.
The second is done by reducing each operation to a lookup value and then using a communication bus to provably connect the two sections of the trace. These communication buses can be implemented either via multiset checks or via the LogUp argument.
Virtual tables in Miden VM
Miden VM makes use of 6 virtual tables across 4 components, all of which are implemented via multiset checks:
- Stack:
- Decoder:
- Chiplets:
- Chiplets virtual table, which combines the following two tables into one:
Communication buses in Miden VM
One strategy for improving the efficiency of a zero knowledge virtual machine is to use specialized components for complex operations and have the main circuit “offload” those operations to the corresponding components by specifying inputs and outputs and allowing the proof of execution to be done by the dedicated component instead of by the main circuit.
These specialized components are designed to prove the internal correctness of the execution of the operations they support. However, in isolation they cannot make any guarantees about the source of the input data or the destination of the output data.
In order to prove that the inputs and outputs specified by the main circuit match the inputs and outputs provably executed in the specialized component, some kind of provable communication bus is needed.
This bus is typically implemented as some kind of lookup argument, and in Miden VM in particular we use multiset checks or LogUp.
Miden VM uses 2 communication buses:
- The chiplets bus , which communicates with all of the chiplets (Hash, Bitwise, Memory, and Kernel ROM). It is implemented using multiset checks.
- The range checker bus , which facilitates requests between the stack and memory components and the range checker. It is implemented using LogUp.
Length of auxiliary columns for lookup arguments
The auxiliary columns used for buses and virtual tables are computed by including information from the current row of the main execution trace into the next row of the auxiliary trace column. Thus, in order to ensure that the trace is long enough to give the auxiliary column space for its final value, a padding row may be required at the end of the trace of the component upon which the auxiliary column depends.
This is true when the data in the main trace could go all the way to the end of the trace, such as in the case of the range checker.
Cost of auxiliary columns for lookup arguments
It is important to note that depending on the field in which we operate, an auxiliary column implementing a lookup argument may actually require more than one trace column. This is specifically true for small fields.
Since Miden uses a 64-bit field, each auxiliary column needs to be represented by columns to achieve ~100-bit security and by columns to achieve ~128-bit security.
Multiset checks
A brief introduction to multiset checks can be found here. In Miden VM, multiset checks are used to implement virtual tables and efficient communication buses.
Running product columns
Although the multiset equality check can be thought of as comparing multiset equality between two vectors and , in Miden VM it is implemented as a single running product column in the following way:
- The running product column is initialized to a value at the beginning of the trace. (We typically use .)
- All values of are multiplied into the running product column.
- All values of are divided out of the running product column.
- If and were multiset equal, then the running product column will equal at the end of the trace.
Running product columns are computed using a set of random values , sent to the prover by the verifier after the prover commits to the execution trace of the program.
Virtual tables
Virtual tables can be used to store intermediate data which is computed at one cycle and used at a different cycle. When the data is computed, the row is added to the table, and when it is used later, the row is deleted from the table. Thus, all that needs to be proved is the data consistency between the row that was added and the row that was deleted.
The consistency of a virtual table can be proved with a single trace column , which keeps a running product of rows that were inserted into and deleted from the table. This is done by reducing each row to a single value, multiplying the value into when the row is inserted, and dividing the value out of when the row is removed. Thus, at any step of the computation, will contain a product of all rows currently in the table.
The initial value of is set to 1. Thus, if the table is empty by the time Miden VM finishes executing a program (we added and then removed exactly the same set of rows), the final value of will also be equal to 1. The initial and final values are enforced via boundary constraints.
Computing a virtual table's trace column
To compute a product of rows, we'll first need to reduce each row to a single value. This can be done as follows.
Let be columns in the virtual table, and assume the verifier sends a set of random values , to the prover after the prover commits to the execution trace of the program.
The prover reduces row in the table to a single value as:
Then, when row is added to the table, we'll update the value in the column like so:
Analogously, when row is removed from the table, we'll update the value in column like so:
Virtual tables in Miden VM
Miden VM makes use of 6 virtual tables across 4 components:
- Stack:
- Decoder:
- Chiplets:
- Chiplets virtual table, which combines the following two tables into one:
Communication buses via multiset checks
A bus can be implemented as a single trace column where a request can be sent to a specific component and a corresponding response will be sent back by that component.
The values in this column contain a running product of the communication with the component as follows:
- Each request is “sent” by computing a lookup value from some information that's specific to the specialized component, the operation inputs, and the operation outputs, and then dividing it out of the running product column .
- Each chiplet response is “sent” by computing the same lookup value from the component-specific information, inputs, and outputs, and then multiplying it into the running product column .
Thus, if the requests and responses match, and the bus column is initialized to , then will start and end with the value . This condition is enforced by boundary constraints on column .
Note that the order of the requests and responses does not matter, as long as they are all included in . In fact, requests and responses for the same operation will generally occur at different cycles. Additionally, there could be multiple requests sent in the same cycle, and there could also be a response provided at the same cycle that a request is received.
Communication bus constraints
These constraints can be expressed in a general way with the 2 following requirements:
- The lookup value must be computed using random values , etc. that are provided by the verifier after the prover has committed to the main execution trace.
- The lookup value must include all uniquely identifying information for the component/operation and its inputs and outputs.
Given an example operation with inputs and outputs , the lookup value can be computed as follows:
The constraint for sending this to the bus as a request would be:
The constraint for sending this to the bus as a response would be:
However, these constraints must be combined, since it's possible that requests and responses both occur during the same cycle.
To combine them, let be the request value and let be the response value. These values are both computed the same way as shown above, but the data sources are different, since the input/output values used to compute come from the trace of the component that's "offloading" the computation, while the input/output values used to compute come from the trace of the specialized component.
The final constraint can be expressed as:
Communication buses in Miden VM
In Miden VM, the specialized components are implemented as dedicated segments of the execution trace, which include the 3 chiplets in the Chiplets module (the hash chiplet, bitwise chiplet, and memory chiplet).
Miden VM currently uses multiset checks to implement the chiplets bus , which communicates with all of the chiplets (Hash, Bitwise, and Memory).
LogUp: multivariate lookups with logarithmic derivatives
The description of LogUp can be found here. In MidenVM, LogUp is used to implement efficient communication buses.
Using the LogUp construction instead of a simple multiset check with running products reduces the computational effort for the prover and the verifier. Given two columns and in the main trace where contains duplicates and does not (i.e. is part of the lookup table), LogUp allows us to compute two logarithmic derivatives and check their equality.
In the above:
- is the number of values in , which must be smaller than the size of the field. (The prime field used for Miden VM has modulus , so must be true.)
- is the number of values in , which must be smaller than the size of the field. (, for Miden VM)
- is the multiplicity of , which is expected to match the number of times the value is duplicated in column . It must be smaller than the size of the set of lookup values. ()
- is a random value that is sent to the prover by the verifier after the prover commits to the execution trace of the program.
Thus, instead of needing to compute running products, we are able to assert correct lookups by computing running sums.
Usage in Miden VM
The generalized trace columns and constraints for this construction are as follows, where component is some component in the trace and lookup table contains the values which need to be looked up from and how many times they are looked up (the multiplicity ).

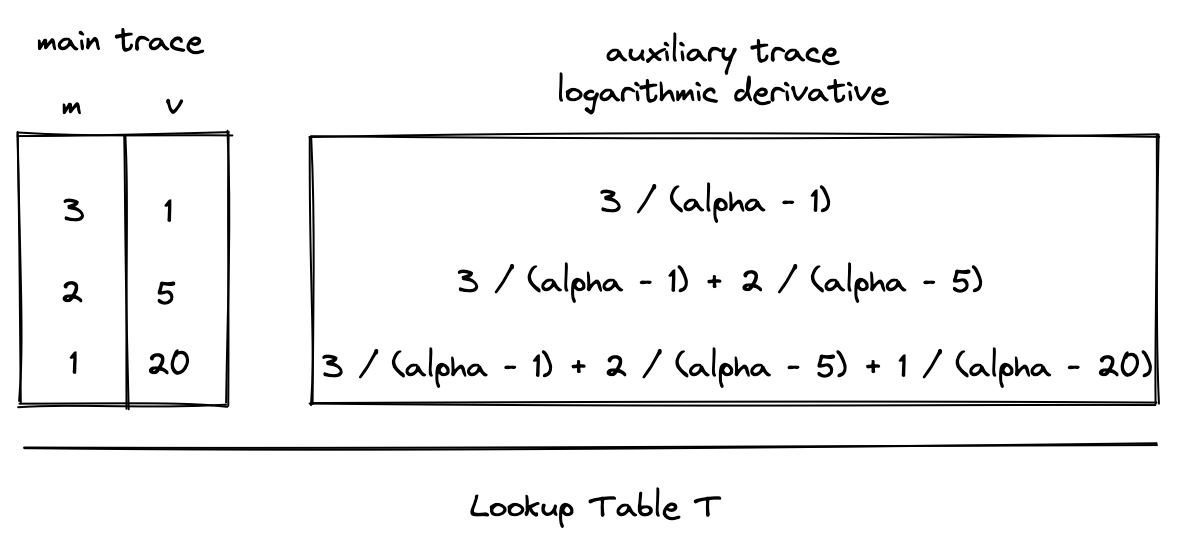
Constraints
The diagrams above show running sum columns for computing the logarithmic derivatives for both and . As an optimization, we can combine these values into a single auxiliary column in the extension field that contains the running sum of values from both logarithmic derivatives. We'll refer to this column as a communication bus , since it communicates the lookup request from the component to the lookup table .
This can be expressed as follows:
Since constraints must be expressed without division, the actual constraint which is enforced will be the following:
In general, we will write constraints within these docs using the previous form, since it's clearer and more readable.
Additionally, boundary constraints must be enforced against to ensure that its initial and final values are . This will enforce that the logarithmic derivatives for and were equal.
Extending the construction to multiple components
The functionality of the bus can easily be extended to receive lookup requests from multiple components. For example, to additionally support requests from column , the bus constraint would be modified to the following:
Since the maximum constraint degree in Miden VM is 9, the lookup table could accommodate requests from at most 7 trace columns in the same trace row via this construction.
Extending the construction with flags
Boolean flags can also be used to determine when requests from various components are sent to the bus. For example, let be 1 when a request should be sent from and 0 otherwise, and let be similarly defined for column . We can use the following constraint to turn requests on or off:
If any of these flags have degree greater than 2 then this will increase the overall degree of the constraint and reduce the number of lookup requests that can be accommodated by the bus per row.
Background Material
Proofs of execution generated by Miden VM are based on STARKs. A STARK is a novel proof-of-computation scheme that allows you to create an efficiently verifiable proof that a computation was executed correctly. The scheme was developed by Eli Ben-Sasson, Michael Riabzev et al. at Technion - Israel Institute of Technology. STARKs do not require an initial trusted setup, and rely on very few cryptographic assumptions.
Here are some resources to learn more about STARKs:
- STARKs paper: Scalable, transparent, and post-quantum secure computational integrity
- STARKs vs. SNARKs: A Cambrian Explosion of Crypto Proofs
Vitalik Buterin's blog series on zk-STARKs:
- STARKs, part 1: Proofs with Polynomials
- STARKs, part 2: Thank Goodness it's FRI-day
- STARKs, part 3: Into the Weeds
Alan Szepieniec's STARK tutorials:
StarkWare's STARK Math blog series:
- STARK Math: The Journey Begins
- Arithmetization I
- Arithmetization II
- Low Degree Testing
- A Framework for Efficient STARKs
StarkWare's STARK tutorial:
Getting started
Welcome to the documentation for the Miden compiler toolchain.
warning
The compiler is currently in an experimental state, and has known bugs and limitations, it is not yet ready for production usage. However, we'd encourage you to start experimenting with it yourself, and give us feedback on any issues or sharp edges you encounter.
The documentation found here should provide a good starting point for the current capabilities of the toolchain, however if you find something that is not covered, but is not listed as unimplemented or a known limitation, please let us know by reporting an issue on the compiler issue tracker.
What is provided?
The compiler toolchain consists of the following primary components:
- An intermediate representation (IR), which can be lowered to by compiler backends wishing to support Miden as a target. The Miden IR is an SSA IR, much like Cranelift or LLVM, providing a much simpler path from any given source language (e.g. Rust), to Miden Assembly. It is used internally by the rest of the Miden compiler suite.
- A WebAssembly (Wasm) frontend for Miden IR. It can handle lowering both core Wasm modules, as
well as basic components using the experimental WebAssembly Component Model. Currently, the Wasm
frontend is known to work with Wasm modules produced by
rustc, which is largely just what LLVM produces, but with the shadow stack placed at the start of linear memory rather than after read-only data. In the future we intend to support more variety in the structure of Wasm modules we accept, but for the time being we're primarily focused on using this as the path for lowering Rust to Miden. - The compiler driver, in the form of the
midencexecutable, and a Rust crate,midenc-compilerto allow integrating the compiler into other tools. This plays the same role asrustcdoes in the Rust ecosystem. - A Cargo extension,
cargo-miden, that provides a convenient developer experience for creating and compiling Rust projects targeting Miden. It contains a project template for a basic Rust crate, and handles orchestratingrustcandmidencto compile the crate to WebAssembly, and then to Miden Assembly. - A terminal-based interactive debugger, available via
midenc debug, which provides a UI very similar tolldborgdbwhen using the TUI mode. You can use this to run a program, or step through it cycle-by-cycle. You can set various types of breakpoints; see the source code, call stack, and contents of the operand stack at the current program point; as well as interatively read memory and format it in various ways for display. - A Miden SDK for Rust, which provides types and bindings to functionality exported from the Miden
standard library, as well as the Miden transaction kernel API. You can use this to access native
Miden features which are not provided by Rust out-of-the-box. The project template generated by
cargo miden newautomatically adds this as a dependency.
What can I do with it?
That all sounds great, but what can you do with the compiler today? The answer depends a bit on what aspect of the compiler you are interested in:
Rust
The most practically useful, and interesting capability provided by the compiler currently, is the ability to compile arbitrary Rust programs to Miden Assembly. See the guides for more information on setting up and compiling a Rust crate for execution via Miden.
WebAssembly
More generally, the compiler frontend is capable of compiling WebAssembly modules, with some constraints, to Miden Assembly. As a result, it is possible to compile a wider variety of languages to Miden Assembly than just Rust, so long as the language can compile to WebAssembly. However, we do not currently provide any of the language-level support for languages other than Rust, and have limited ability to provide engineering support for languages other than Rust at this time.
Our Wasm frontend does not support all of the extensions to the WebAssembly MVP, most notably the reference types and GC proposals.
Miden IR
If you are interested in compiling to Miden from your own compiler, you can target Miden IR, and invoke the driver from your compiler to emit Miden artifacts. At this point in time, we don't have the resources to provide much in the way of engineering support for this use case, but if you find issues in your efforts to use the IR in your compiler, we would certainly like to know about them!
We do not currently perform any optimizations on the IR, since we are primarily working with the output of compiler backends which have already applied optimizations, at this time. This may change in the future, but for now it is expected that you implement your own optimization passes as needed.
Known bugs and limitations
For the latest information on known bugs and limitations, see the issue tracker.
Where to start?
Provided here are a set of guides which are focused on documenting a couple of supported workflows we expect will meet the needs of most users, within the constraints of the current feature set of the compiler. If you find that there is something you wish to do that is not covered, and is not one of our known limitations, please open an issue, and we will try to address the missing docs as soon as possible.
Installation
To get started, there are a few ways you might use the Miden compiler. Select the one that applies to you, and the corresponding guide will walk you through getting up and running:
Usage
The Usage section documents how to work with Miden's compiler tools. Key components include:
- Command-line interface (
midenc) - A low-level compiler driver offering precise control over compilation outputs and diagnostic information - Cargo extension (
cargo-miden) - Higher-level build tool integration for managing Miden projects within Rust's package ecosystem
Getting started with midenc
The midenc executable is the command-line interface for the compiler driver, as well as other
helpful tools, such as the interactive debugger.
While it is a lower-level tool compared to cargo-miden, just like the difference between rustc
and cargo, it provides a lot of functionality for emitting diagnostic information, controlling
the output of the compiler, and configuring the compilation pipeline. Most users will want to use
cargo-miden, but understanding midenc is helpful for those times where you need to get your
hands dirty.
Installation
warning
Currently, midenc (and as a result, cargo-miden), requires the nightly Rust toolchain, so
make sure you have it installed first:
rustup toolchain install nightly-2025-01-16
NOTE: You can also use the latest nightly, but the specific nightly shown here is known to work.
To install the midenc, clone the compiler repo first:
git clone https://github.com/0xpolygonmiden/compiler
Then, run the following in your shell in the cloned repo folder:
cargo install --path midenc --locked
Usage
Once installed, you should be able to invoke the compiler, you should see output similar to this:
midenc help compile
Usage: midenc compile [OPTIONS] [-- <INPUTS>...]
Arguments:
[INPUTS]...
Path(s) to the source file(s) to compile.
You may also use `-` as a file name to read a file from stdin.
Options:
--output-dir <DIR>
Write all compiler artifacts to DIR
-W <LEVEL>
Modify how warnings are treated by the compiler
[default: auto]
Possible values:
- none: Disable all warnings
- auto: Enable all warnings
- error: Promotes warnings to errors
-v, --verbose
When set, produces more verbose output during compilation
-h, --help
Print help (see a summary with '-h')
The actual help output covers quite a bit more than shown here, this is just for illustrative purposes.
The midenc executable supports two primary functions at this time:
midenc compileto compile one of our supported input formats to Miden Assemblymidenc debugto run a Miden program attached to an interactive debuggermidenc runto run a Miden program non-interactively, equivalent tomiden run
Compilation
See the help output for midenc compile for detailed information on its options and their
behavior. However, the following is an example of how one might use midenc compile in practice:
midenc compile --target rollup \
--entrypoint 'foo::main' \
-lextra \
-L ./masm \
--emit=hir=-,masp \
-o out.masp \
target/wasm32-wasip1/release/foo.wasm
In this scenario, we are in the root of a Rust crate, named foo, which we have compiled for the
wasm32-wasip1 target, which placed the resulting WebAssembly module in the
target/wasm32-wasip1/release directory. This crate exports a function named main, which we want
to use as the entrypoint of the program.
Additionally, our Rust code links against some hand-written Miden Assembly code, namespaced under
extra, which can be found in ./masm/extra. We are telling midenc to link the extra library,
and to add the ./masm directory to the library search path.
Lastly, we're configuring the output:
- We're using
--emitto requestmidencto dump Miden IR (hir) to stdout (specified via the-shorthand), in addition to the Miden package artifact (masp). - We're telling
midencto write the compiled output toout.maspin the current directory, rather than the default path that would have been used (target/miden/foo.masp).
Debugging
See Debugging Programs for details on using midenc debug to debug Miden programs.
Next steps
We have put together two useful guides to walk through more detail on compiling Rust to WebAssembly:
- To learn how to compile Rust to WebAssembly so that you can invoke
midenc compileon the resulting Wasm module, see this guide. - If you already have a WebAssembly module, or know how to produce one, and want to learn how to compile it to Miden Assembly, see this guide.
You may also be interested in our basic account project template, as a starting point for your own Rust project.
Getting started with Cargo
As part of the Miden compiler toolchain, we provide a Cargo extension, cargo-miden, which provides
a template to spin up a new Miden project in Rust, and takes care of orchestrating rustc and
midenc to compile the Rust crate to a Miden package.
Installation
warning
Currently, midenc (and as a result, cargo-miden), requires the nightly Rust toolchain, so
make sure you have it installed first:
rustup toolchain install nightly-2025-01-16
NOTE: You can also use the latest nightly, but the specific nightly shown here is known to work.
To install the extension, clone the compiler repo first:
git clone https://github.com/0xpolygonmiden/compiler
Then, run the following in your shell in the cloned repo folder:
cargo install --path tools/cargo-miden --locked
This will take a minute to compile, but once complete, you can run cargo help miden or just
cargo miden to see the set of available commands and options.
To get help for a specific command, use cargo miden help <command> or cargo miden <command> --help.
Creating a new project
Your first step will be to create a new Rust project set up for compiling to Miden:
cargo miden new foo
In this above example, this will create a new directory foo, containing a Cargo project for a
crate named foo, generated from our Miden project template.
The template we use sets things up so that you can pretty much just build and run. Since the toolchain depends on Rust's native WebAssembly target, it is set up just like a minimal WebAssembly crate, with some additional tweaks for Miden specifically.
Out of the box, you will get a Rust crate that depends on the Miden SDK, and sets the global allocator to a simple bump allocator we provide as part of the SDK, and is well suited for most Miden use cases, avoiding the overhead of more complex allocators.
As there is no panic infrastructure, panic = "abort" is set, and the panic handler is configured
to use the native WebAssembly unreachable intrinsic, so the compiler will strip out all of the
usual panic formatting code.
Compiling to Miden package
Now that you've created your project, compiling it to Miden package is as easy as running the following command from the root of the project directory:
cargo miden build --release
This will emit the compiled artifacts to target/miden/release/foo.masp.
Running a compiled Miden VM program
warning
To run the compiled Miden VM program you need to have midenc installed. See midenc docs for the installation instructions.
The compiled Miden VM program can be run from the Miden package with the following:
midenc run target/miden/release/foo.masp --inputs some_inputs.toml
See midenc run --help for the inputs file format.
Examples
Check out the examples for some cargo-miden project examples.
Guides
This section contains practical guides for working with the Miden compiler:
- Compiling Rust to WebAssembly - Walks through compiling Rust code to WebAssembly modules
- WebAssembly to Miden Assembly - Explains compiling Wasm modules to Miden Assembly
- Developing Miden Programs in Rust - Demonstrates using Rust with Miden's standard library
- Developing Miden Rollup Accounts and Note Scripts in Rust - Shows Rust development for Miden rollup components
Compiling Rust To WebAssembly
This chapter will walk you through compiling a Rust crate to a WebAssembly (Wasm) module
in binary (i.e. .wasm) form. The Miden compiler has a frontend which can take such
modules and compile them on to Miden Assembly, which will be covered in the next chapter.
Setup
First, let's set up a simple Rust project that contains an implementation of the Fibonacci function (I know, it's overdone, but we're trying to keep things as simple as possible to make it easier to show the results at each step, so bear with me):
Start by creating a new library crate:
cargo new --lib wasm-fib && cd wasm-fib
To compile to WebAssembly, you must have the appropriate Rust toolchain installed, so let's add
a toolchain file to our project root so that rustup and cargo will know what we need, and use
them by default:
cat <<EOF > rust-toolchain.toml
[toolchain]
channel = "stable"
targets = ["wasm32-wasip1"]
EOF
Next, edit the Cargo.toml file as follows:
[package]
name = "wasm-fib"
version = "0.1.0"
edition = "2021"
[lib]
# Build this crate as a self-contained, C-style dynamic library
# This is required to emit the proper Wasm module type
crate-type = ["cdylib"]
[dependencies]
# Use a tiny allocator in place of the default one, if we want
# to make use of types in the `alloc` crate, e.g. String. We
# don't need that now, but it's good information to have in hand.
#miden-sdk-alloc = "0.0.5"
# When we build for Wasm, we'll use the release profile
[profile.release]
# Explicitly disable panic infrastructure on Wasm, as
# there is no proper support for them anyway, and it
# ensures that panics do not pull in a bunch of standard
# library code unintentionally
panic = "abort"
# Enable debug information so that we get useful debugging output
debug = true
# Optimize the output for size
opt-level = "z"
Most of these things are done to keep the generated code size as small as possible. Miden is a target where the conventional wisdom about performance should be treated very carefully: we're almost always going to benefit from less code, even if conventionally that code would be less efficient, simply due to the difference in proving time accumulated due to extra instructions. That said, there are no hard and fast rules, but these defaults are good ones to start with.
tip
We reference a simple bump allocator provided by miden-sdk-alloc above, but any simple
allocator will do. The trade offs made by these small allocators are not generally suitable for
long-running, or allocation-heavy applications, as they "leak" memory (generally because they
make little to no attempt to recover freed allocations), however they are very useful for
one-shot programs that do minimal allocation, which is going to be the typical case for Miden
programs.
Next, edit src/lib.rs as shown below:
This exports our fib function from the library, making it callable from within a larger Miden program.
All that remains is to compile to WebAssembly:
cargo build --release --target=wasm32-wasip1
This places a wasm_fib.wasm file under the target/wasm32-wasip1/release/ directory, which
we can then examine with wasm2wat to set the code we generated:
wasm2wat target/wasm32-wasip1/release/wasm_fib.wasm
Which dumps the following output (may differ slightly on your machine, depending on the specific compiler version):
(module $wasm_fib.wasm
(type (;0;) (func (param i32) (result i32)))
(func $fib (type 0) (param i32) (result i32)
(local i32 i32 i32)
i32.const 0
local.set 1
i32.const 1
local.set 2
loop (result i32) ;; label = @1
local.get 2
local.set 3
block ;; label = @2
local.get 0
br_if 0 (;@2;)
local.get 1
return
end
local.get 0
i32.const -1
i32.add
local.set 0
local.get 1
local.get 3
i32.add
local.set 2
local.get 3
local.set 1
br 0 (;@1;)
end)
(memory (;0;) 16)
(global $__stack_pointer (mut i32) (i32.const 1048576))
(export "memory" (memory 0))
(export "fib" (func $fib)))
Success!
Next steps
In Compiling WebAssembly to Miden Assembly, we walk through how to take the
WebAssembly module we just compiled, and lower it to Miden Assembly using midenc!
Compiling WebAssembly to Miden Assembly
This guide will walk you through compiling a WebAssembly (Wasm) module, in binary form
(i.e. a .wasm file), to Miden Assembly (Masm), both in its binary package form (a .masp file),
and in textual Miden Assembly syntax form (i.e. a .masm file).
Setup
We will be making use of the example crate we created in Compiling Rust to WebAssembly, which produces a small Wasm module that is easy to examine in Wasm text format, and demonstrates a good set of default choices for a project compiling to Miden Assembly from Rust.
In this chapter, we will be compiling Wasm to Masm using the midenc executable, so ensure that
you have followed the instructions in the Getting Started with midenc guide
and then return here.
note
While we are using midenc for this guide, the more common use case will be to use the
cargo-miden Cargo extension to handle the gritty details of compiling from Rust to Wasm
for you. However, the purpose of this guide is to show you what cargo-miden is handling
for you, and to give you a foundation for using midenc yourself if needed.
Compiling to Miden Assembly
In the last chapter, we compiled a Rust crate to WebAssembly that contains an implementation
of the Fibonacci function called fib, that was emitted to
target/wasm32-wasip1/release/wasm_fib.wasm. All that remains is to tell midenc to compile this
module to Miden Assembly.
Currently, by default, the compiler will emit an experimental package format that the Miden VM does
not yet support. We will instead use midenc run to execute the package using the VM for us, but
once the package format is stabilized, this same approach will work with miden run as well.
We also want to examine the Miden Assembly generated by the compiler, so we're going to ask the compiler to emit both types of artifacts:
midenc compile --emit masm=wasm_fib.masm,masp target/wasm32-wasip1/release/wasm_fib.wasm
This will compile our Wasm module to a Miden package with the .masp extension, and also emit the
textual Masm to wasm_fib.masm so we can review it. The wasm_fib.masp file will be emitted in the
default output directory, which is the current working directory by default.
If we dump the contents of wasm_fib.masm, we'll see the following generated code:
export.fib
push.0
push.1
movup.2
swap.1
dup.1
neq.0
push.1
while.true
if.true
push.4294967295
movup.2
swap.1
u32wrapping_add
dup.1
swap.1
swap.3
swap.1
u32wrapping_add
movup.2
swap.1
dup.1
neq.0
push.1
else
drop
drop
push.0
end
end
end
If you compare this to the WebAssembly text format, you can see that this is a fairly faithful translation, but there may be areas where we generate sub-optimal Miden Assembly.
note
At the moment the compiler does only minimal optimization, late in the pipeline during codegen, and only in an effort to minimize operand stack management code. So if you see an instruction sequence you think is bad, bring it to our attention, and if it is something that we can solve as part of our overall optimization efforts, we will be sure to do so. There are limits to what we can generate compared to what one can write by hand, particularly because Rust's memory model requires us to emulate byte-addressable memory on top of Miden's word-addressable memory, however our goal is to keep this overhead within an acceptable bound in the general case, and easily-recognized patterns that can be simplified using peephole optimization are precisely the kind of thing we'd like to know about, as those kinds of optimizations are likely to produce the most significant wins.
Testing with the Miden VM
note
Because the compiler ships with the VM embedded for midenc debug, you can run your program
without having to install the VM separately, though you should do that as well, as midenc only
exposes a limited set of commands for executing programs, intended for debugging.
We can test our compiled program like so:
$ midenc run --num-outputs 1 wasm_fib.masp -- 10
============================================================
Run program: wasm_fib.masp
============================================================
Executed program with hash 0xe5ba88695040ec2477821b26190e9addbb1c9571ae30c564f5bbfd6cabf6c535 in 19 milliseconds
Output: [55]
VM cycles: 295 extended to 512 steps (42% padding).
├── Stack rows: 295
├── Range checker rows: 67
└── Chiplets rows: 250
├── Hash chiplet rows: 248
├── Bitwise chiplet rows: 0
├── Memory chiplet rows: 1
└── Kernel ROM rows: 0
Success! We got the expected result of 55.
Next steps
This guide is not comprehensive, as we have not yet examined in detail the differences between compiling libraries vs programs, linking together multiple libraries, packages, or discussed some of the more esoteric compiler options. We will be updating this documentation with those details and more in the coming weeks and months, so bear with us while we flesh out our guides!
Developing Miden programs in Rust
This chapter will walk through how to develop Miden programs in Rust using the standard library
provided by the miden-stdlib-sys crate (see the
README.
Getting started
Import the standard library from the miden-stdlib-sys crate:
Using Felt (field element) type
The Felt type is a field element type that is used to represent the field element values of the
Miden VM.
To initialize a Felt value from an integer constant checking the range at compile time, use the
felt! macro:
Otherwise, use the Felt::new constructor:
The constructor returns an error if the value is not a valid field element, e.g. if it is not in the
range 0..=M where M is the modulus of the field (2^64 - 2^32 + 1).
The Felt type implements the standard arithmetic operations, e.g. addition, subtraction,
multiplication, division, etc. which are accessible through the standard Rust operators +, -,
*, /, etc. All arithmetic operations are wrapping, i.e. performed modulo M.
TODO: Add examples of using operations on Felt type and available functions (assert*, etc.).
Developing Miden rollup accounts and note scripts in Rust
This chapter walks you through how to develop Miden rollup accounts and note scripts in Rust using the Miden SDK crate.
Debugging programs
A very useful tool in the Miden compiler suite, is its TUI-based interactive debugger, accessible
via the midenc debug command.
warning
The debugger is still quite new, and while very useful already, still has a fair number of UX annoyances. Please report any bugs you encounter, and we'll try to get them patched ASAP!
Getting started
The debugger is launched by executing midenc debug, and giving it a path to a program compiled
by midenc compile. See Program Inputs for information on how to provide inputs
to the program you wish to debug. Run midenc help debug for more detailed usage documentation.
The debugger may also be used as a library, but that is left as an exercise for the reader for now.
Example
# Compile a program to MAST from a rustc-generated Wasm module
midenc compile foo.wasm -o foo.masl
# Load that program into the debugger and start executing it
midenc debug foo.masl
Program inputs
To pass arguments to the program on the operand stack, or via the advice provider, you have two options, depending on the needs of the program:
- Pass arguments to
midenc debugin the same order you wish them to appear on the stack. That is, the first argument you specify will be on top of the stack, and so on. - Specify a configuration file from which to load inputs for the program, via the
--inputsoption.
Via command line
To specify the contents of the operand stack, you can do so following the raw arguments separator --.
Each operand must be a valid field element value, in either decimal or hexadecimal format. For example:
midenc debug foo.masl -- 1 2 0xdeadbeef
If you pass arguments via the command line in conjunction with --inputs, then the command line arguments
will be used instead of the contents of the inputs.stack option (if set). This lets you specify a baseline
set of inputs, and then try out different arguments using the command line.
Via inputs config
While simply passing operands to the midenc debug command is useful, it only allows you to specify
inputs to be passed via operand stack. To provide inputs via the advice provider, you will need to use
the --inputs option. The configuration file expected by --inputs also lets you tweak the execution
options for the VM, such as the maximum and expected cycle counts.
An example configuration file looks like so:
# This section is used for execution options
[options]
max_cycles = 5000
expected_cycles = 4000
# This section is the root table for all inputs
[inputs]
# Specify elements to place on the operand stack, leftmost element will be on top of the stack
stack = [1, 2, 0xdeadbeef]
# This section contains input options for the advice provider
[inputs.advice]
# Specify elements to place on the advice stack, leftmost element will be on top
stack = [1, 2, 3, 4]
# The `inputs.advice.map` section is a list of advice map entries that should be
# placed in the advice map before the program is executed. Entries with duplicate
# keys are handled on a last-write-wins basis.
[[inputs.advice.map]]
# The key for this entry in the advice map
digest = '0x3cff5b58a573dc9d25fd3c57130cc57e5b1b381dc58b5ae3594b390c59835e63'
# The values to be stored under this key
values = [1, 2, 3, 4]
[[inputs.advice.map]]
digest = '0x20234ee941e53a15886e733cc8e041198c6e90d2a16ea18ce1030e8c3596dd38''
values = [5, 6, 7, 8]
Usage
Once started, you will be dropped into the main debugger UI, stopped at the first cycle of the program. The UI is organized into pages and panes, with the main/home page being the one you get dropped into when the debugger starts. The home page contains the following panes:
- Source Code - displays source code for the current instruction, if available, with the relevant line and span highlighted, with syntax highlighting (when available)
- Disassembly - displays the 5 most recently executed VM instructions, and the current cycle count
- Stack Trace - displays a stack trace for the current instruction, if the program was compiled with tracing enabled. If frames are unavailable, this pane may be empty.
- Operand Stack - displays the contents of the operand stack and its current depth
- Breakpoints - displays the set of current breakpoints, along with how many were hit at the current instruction, when relevant
Keyboard shortcuts
On the home page, the following keyboard shortcuts are available:
| Shortcut | Mnemonic | Description |
|---|---|---|
q | quit | exit the debugger |
h | next pane | cycle focus to the next pane |
l | prev pane | cycle focus to the previous pane |
s | step | advance the VM one cycle |
n | step next | advance the VM to the next instruction |
c | continue | advance the VM to the next breakpoint, else to completion |
e | exit frame | advance the VM until we exit the current call frame, a breakpoint is triggered, or execution terminates |
d | delete | delete an item (where applicable, e.g. the breakpoints pane) |
: | command prompt | bring up the command prompt (see below for details) |
When various panes have focus, additional keyboard shortcuts are available, in any pane
with a list of items, or multiple lines (e.g. source code), j and k (or the up and
down arrows) will select the next item up and down, respectively. As more features are
added, I will document their keyboard shortcuts below.
Commands
From the home page, typing : will bring up the command prompt in the footer pane.
You will know the prompt is active because the keyboard shortcuts normally shown there will
no longer appear, and instead you will see the prompt, starting with :. It supports any
of the following commands:
| Command | Aliases | Action | Description |
|---|---|---|---|
quit | q | quit | exit the debugger |
debug | show debug log | display the internal debug log for the debugger itself | |
reload | reload program | reloads the program from disk, and resets the UI (except breakpoints) | |
breakpoint | break, b | create breakpoint | see Breakpoints |
read | r | read memory | inspect linear memory (see Reading Memory |
Breakpoints
One of the most common things you will want to do with the debugger is set and manage breakpoints.
Using the command prompt, you can create breakpoints by typing b (or break or breakpoint),
followed by a space, and then the desired breakpoint expression to do any of the following:
- Break at an instruction which corresponds to a source file (or file and line) whose name/path matches a pattern
- Break at the first instruction which causes a call frame to be pushed for a procedure whose name matches a pattern
- Break any time a specific opcode is executed
- Break at the next instruction
- Break after N cycles
- Break at CYCLE
The syntax for each of these can be found below, in the same order (shown using b as the command):
| Expression | Description |
|---|---|
b FILE[:LINE] | Break when an instruction with a source location in FILE (a glob pattern) and that occur on LINE (literal, if provided) are hit. |
b in NAME | Break when the glob pattern NAME matches the fully-qualified procedure namecontaining the current instruction |
b for OPCODE | Break when the an instruction with opcode OPCODE is exactly matched (including immediate values) |
b next | Break on the next instruction |
b after N | Break after N cycles |
b at CYCLE | Break when the cycle count reaches CYCLE. If CYCLE has already occurred, this has no effect |
When a breakpoint is hit, it will be highlighted, and the breakpoint window will display the number of hit breakpoints in the lower right.
After a breakpoint is hit, it expires if it is one of the following types:
- Break after N
- Break at CYCLE
- Break next
When a breakpoint expires, it is removed from the breakpoint list on the next cycle.
Reading memory
Another useful diagnostic task is examining the contents of linear memory, to verify that expected
data has been written. You can do this via the command prompt, using r (or read), followed by
a space, and then the desired memory address and options:
The format for read expressions is :r ADDR [OPTIONS..], where ADDR is a memory address in
decimal or hexadecimal format (the latter requires the 0x prefix). The read command supports
the following for OPTIONS:
| Option | Alias | Values | Default | Description |
|---|---|---|---|---|
-mode MODE | -m |
| words | Specify a memory addressing mode |
-format FORMAT | -f |
| decimal | Specify the format used to print integral values |
-count N | -c | 1 | Specify the number of units to read | |
-type TYPE | -t | See Types | word | Specify the type of value to read This also has the effect of modifying the default -format and unit size for -count |
Any invalid combination of options, or invalid syntax, will display an error in the status bar.
Types
| Type | Description |
|---|---|
iN | A signed integer of N bits |
uN | An unsigned integer of N bits |
felt | A field element |
word | A Miden word, i.e. an array of four field elements |
ptr or pointer | A 32-bit memory address (implies -format hex) |
Roadmap
The following are some features planned for the near future:
- Watchpoints, i.e. cause execution to break when a memory store touches a specific address
- Conditional breakpoints, i.e. only trigger a breakpoint when an expression attached to it evaluates to true
- More DYIM-style breakpoints, i.e. when breaking on first hitting a match for a file or procedure, we probably shouldn't continue to break for every instruction to which that breakpoint technically applies. Instead, it would make sense to break and then temporarily disable that breakpoint until something changes that would make breaking again useful. This will rely on the ability to disable breakpoints, not delete them, which we don't yet support.
- More robust type support in the
readcommand - Display procedure locals and their contents in a dedicated pane
FAQ
How is privacy implemented in Miden?
Miden leverages Zero Knowledge proofs and client side execution and proving to provide security and privacy.
Does Miden support encrypted notes?
At the moment, Miden does not have support for encrypted notes but it is a planned feature.
Why does Miden have delegated proving?
Miden leverages delegated proving for a few technical and practical reasons:
- Computational: Generating Zero Knowledge proofs is a computationally intensive work. The proving process requires significant processing power and memory, making it impractical for some end-user devices (like smartphones) to generate.
- Technical architecture:
Miden's architecture separates concerns between:
- Transaction Creation: End users create and sign transactions
- Proof Generation: Specialized provers generate validity proofs
- Verification: The network verifies these proofs
- Proving efficiency: Delegated provers can use optimized hardware that wouldn't be available to end-user devices, specifically designed for the mathematical operations needed in STARK proof generation.
What is the lifecycle of a transaction?
1. Transaction Creation
- User creates a transaction specifying the operations to perform (transfers, contract interactions, etc.)
- Client performs preliminary validation of the transaction and its structure
- The user authorizes the specified state transitions by signing the transaction
2. Transaction Submission
- The signed transaction is submitted to Miden network nodes
- The transaction enters the mempool (transaction pool) where it waits to be selected to be included in the state
- Nodes perform basic validation checks on the transaction structure and signature
3. Transaction Selection
- A sequencer (or multiple sequencers in a decentralized setting) selects transactions from the mempool
- The sequencer groups transactions into bundles based on state access patterns and other criteria
- The transaction execution order is determined according to protocol mechanism
4. Transaction Execution
- The current state relevant to the transaction is loaded
- The Miden VM executes the transaction operations
- State Transition Computation: The resulting state transitions are computed
- An execution trace of the transaction is generated which captures all the computation
5. Proof Generation
- A STARK based cryptographic proof is generated attesting to the correctness of the execution
- A proof for the aggregated transaction is created
6. Block Production
- The aggregated bundle of transactions along with their proofs are assembled into a block
- A recursive proof attesting to all bundle proofs is generated
- The block data structure is finalized with the aggregated proof
7. L1 Submission
- Transaction data is posted to the data availability layer
- The block proof and state delta commitment are submitted to the Miden contract (that is bridged to Ethereum/AggLayer)
- The L1 contract verifies validity of the proof
- Upon successful verification, the L1 contract updates the state root
8. Finalization
- Transaction receipts and events are generated
- The global state commitment is updated to reflect the new state
- The transaction is now considered finalized on the L1
- Users and indexers get notified/updated about the transaction completion
Do notes in Miden support recency conditions?
Yes, Miden enables consumption of notes based on time conditions, such as:
- A specific block height being reached
- A timestamp threshold being passed
- An oracle providing specific data
- Another transaction being confirmed
What does a Miden operator do in Miden?
A Miden operator is an entity that maintains the infrastructure necessary for the functioning of the Miden rollup. Their roles may involve:
- Running Sequencer Nodes
- Operating the Prover Infrastructure
- Submitting Proofs to L1
- Maintaining Data Availability
- Participating in the Consensus Mechanism
How does bridging works in Miden?
Miden does not yet have a fully operational bridge, work in progress.
What does the gas fee model of Miden look like?
Miden does not yet have a fully implemented fee model, work in progress.
Glossary
Account
An account is a data structure that represents an entity (user account, smart contract) of the Miden blockchain, they are analogous to smart contracts.
Account builder
Account builder provides a structured way to create and initialize new accounts on the Miden network with specific properties, permissions, and initial state.
AccountCode
Represents the executable code associated with an account.
AccountComponent
An AccountComponent can be described as a modular unit of code to represent the functionality of a Miden Account. Each AccountCode is composed of multiple AccountComponent's.
AccountId
The AccountId is a value that uniquely identifies each account in Miden.
AccountIdVersion
The AccountIdVersion represents the different versions of account identifier formats supported by Miden.
AccountStorage
The AccountStorage is a key-value store associated with an account. It is made up of storage slots.
Asset
An Asset represents a digital resource with value that can be owned, transferred, and managed within the Miden blockchain.
AssetVault
The AssetVault is used for managing assets within accounts. It provides a way for storing and transfering assets associated with each account.
Batch
A Batch allows multiple transactions to be grouped together, these batches will then be aggregated into blocks, improving network throughput.
Block
A Block is a fundamental data structure which groups multiple batches together and forms the blockchain's state.
Delta
A Delta represents the changes between two states s and s'. By applying a Delta d to s would result in s'.
Felt
A Felt or Field Element is a data type used for cryptographic operations. It represents an element in the finite field used in Miden.
Kernel
A fundamental module of the MidenVM that acts as a base layer by providing core functionality and security guarantees for the protocol.
Miden Assembly
An assembly language specifically designed for the Miden VM. It's a low-level programming language with specialized instructions optimized for zero-knowledge proof generation.
Note
A Note is a fundamental data structure that represents an off-chain asset or a piece of information that can be transferred between accounts. Miden's UTXO-like (Unspent Transaction Output) model is designed around the concept of notes. There are output notes which are new notes created by the transaction and input notes which are consumed (spent) by the transaction.
Note script
A Note script is a program that defines the rules and conditions under which a note can be consumed.
Note tag
A Note tag is an identifier or metadata associated with notes that provide additional filtering capabilities.
Note ID
Note ID is a unique identifier assigned to each note to distinguish it from other notes.
Nullifier
A nullifier is a cryptographic commitment that marks a note as spent, preventing it from being consumed again.
Prover
A Prover is responsible for generating zero-knowledge proofs that attest to the correctness of the execution of a program without revealing the underlying data.
Word
A Word is a data structure that represents the basic unit of computation and storage in Miden, it is composed or four Felt's.

A collection of awesome Miden links, resources and shiny things.
Visit our website!
Table of contents
Misc
- Miden website
- Miden organization repository
- Miden protocol playground
- Miden VM playground
- Miden tutorials
- Miden X
- Miden Telegram
Documentation
Tooling
Research papers
- Generalized Indifferentiable Sponge and its Application to Polygon Miden VM
- XHash: Efficient STARK-friendly Hash Function
- Rescue-Prime Optimized
- Lattice-Based Cryptography in Miden VM
- STARK-based Signatures from the RPO Permutation
- A note on adding zero-knowledge to STARKs
- Arithmetization Oriented Encryption
Blog posts
- Miden Alpha Testnet v6 is Live
- Miden Alpha Testnet v5 is Live
- Miden Alpha Testnet v4 is Live
- Miden Alpha Testnet v3 is Live
- Miden Asset Model
- Miden State Model
- Miden Pioneers: Composability Labs building an Onchain CLOB
- Miden Alpha Testnet v2 is Live
- Miden Pioneers: Rize Labs building online poker
- Miden Pioneers: Keom, Defi using Zero Knowledge
- Miden September Monthly Developer Update
- Layer 2 Demystified
- Privacy scales better
- Polygon 2.0: Protocol Architecture
- Introducting Polygon 2.0: The Value Layer of the Internet
- Miden Transaction model
- Miden Ethereum Extended
- Open Source, Zero Knowledge, and the Age of Copypasta
- ZK Whiteboard Sessions: Your Dev-Driven Curricula for All Things ZK
- Meet the Humans Building Polygon ZK
- Polygon's Zero Knowledge Strategy Explained
- Polygon Announces Polygon Miden
Videos
- ZK Day at SBC - Workshop by Paul-Henry Kajfasz, Senior Protocol Engineer at Polygon Miden - Paul-Henry Kajfasz, ZK Day at SBC
- Polygon Miden: A New VM for the ZK Future | Avail Whiteboard Series - Bobbin Threadbare, Avail Whiteboard Series
- ZK8: The power of multiset checks in STARK-based VMs - grjte - Polygon Miden - grjte, ZK Summit 8
- ZK9: AirScript - a simple and efficient way to write AIR constraints - grjte, ZK Summit 9
- ZK10: Optimizing recursive STARK verification in Polygon Miden VM - Bobbin Threadbare, ZK Summit 10
- zkStudyClub: AirScript presented by Bobbin Threadbare - Bobbin Threadbare, ZK Study Club
- ZK Whiteboard Sessions - Module Four: SNARKs vs STARKs with Bobbin Threadbare - Bobbin Threadbare, Brendan Farmer, ZK Whiteboard Sessions
- ZK HACK IV - Provable State Changes: Polygon Miden Transaction Kernel - Dominik Schmid, Bobbin Threadbare, ZK Hack IV
- ZK Whiteboard Sessions – Module Nine: Introduction to zkRollups with Barry Whitehat - Bobbin Threadbare, Barry Whitehat, ZK Whiteboard Sessions
- ZK Whiteboard Sessions – Module Eight: Achieving Decentralised Private Computation - Bobbin Threadbare, Pratyush Mishra, ZK Whiteboard Sessions
- ZK Whiteboard Sessions – Module Seven: Zero Knowledge Virtual Machines (zkVM) with grjte - Bobbin Threadbare, grjte, ZK Whiteboard Sessions
- AirScript: a DSL for writing AIR constraints | Bobbin Threadbare | PROGCRYPTO - Bobbin Threadbare, PROGCRYPTO
- StarkWare Sessions 23 | AirScript: A DSL for Writing AIR Constraints | Bobbin Threadbare - Bobbin Threadbare, StarkWare Sessions 2023
- Miden & the Future of Privacy Preserving Protocols presented by Paul-Henry Kajfasz of Polygon Miden - Paul-Henry Kajfasz, ZK Accelerate Athens
- Recursion in the Miden VM, by Augusto Hack of Polygon Miden - Augusto Hack, ZK Accelerate Istanbul
- Polygon Miden VM | Avail's Hot Take Series: The Execution Race (EthDenver) - Dominik Schmid, EthDenver
- ZK7: Miden VM: a STARK-friendly VM for blockchains - Bobbin Threadbare – Polygon - Bobbin Threadbare, ZK Summit 7
- 09 Miden VM architecture overview - Bobbin Threadbare, 0xParc
- Bobbin Threadbare - Miden VM: the heart of Polygon Miden - Bobbin Threadbare, Layer Two Amsterdam
- Polygon Miden: Extending Ethereum’s Feature Set | Dominik Schmid (April 2023) - Dominik Schmid, Ethereum Berlin
- Using a Hybrid UTXO and Account-based State Model in a ZK Rollup by Bobbin Threadbare - Bobbin Threadbare, Devcon Bogota
- Miden: Ethereum Extended - Dominik Schmid, Ethereum Engineering Group
- Polygon Miden - a STARK based ZK Rollup - Bobbin Threadbare, ETH Global
- Episode 210: The Road to STARKs and Miden with Bobbin Threadbare - Bobbin Threadbare, ZK Podcast
- Provable Compliance on Polygon Miden and beyond / Anne-Grace Kleczewski - Anne-Grace Kleczewski, Duct Tape
- LAMBDA Class: How Polygon Miden works by Ignacio Amigo - Ignacio Amigo, Keom
- Privacy Scales Better by Dominik Schmid, Polygon | L2con Brussels - Dominik Schmid, L2con Brussels
- Mass adoption with private and asynchronous blockchains, by Bobbin Threadbare of Polygon Miden - Bobbin Threadbare, ZK Accelerate Bangkok
Contributing
We welcome contributions. Feel free to submit pull requests or open issues.
License
This project is licensed under the MIT License.